Awesome
<div align="center"><img src="./assets/head.jpg"></div>AWESOME DATA SCIENCE
![]()
An open-source Data Science repository to learn and apply towards solving real world problems.
This is a shortcut path to start studying Data Science. Just follow the steps to answer the questions, "What is Data Science and what should I study to learn Data Science?"
Sponsors
| Sponsor | Pitch |
|---|---|
| --- | Be the first to sponsor! github@academic.io |
Table of Contents
- What is Data Science?
- Where do I Start?
- Training Resources
- The Data Science Toolbox
- Literature and Media
- Socialize
- Fun
- Other Awesome Lists
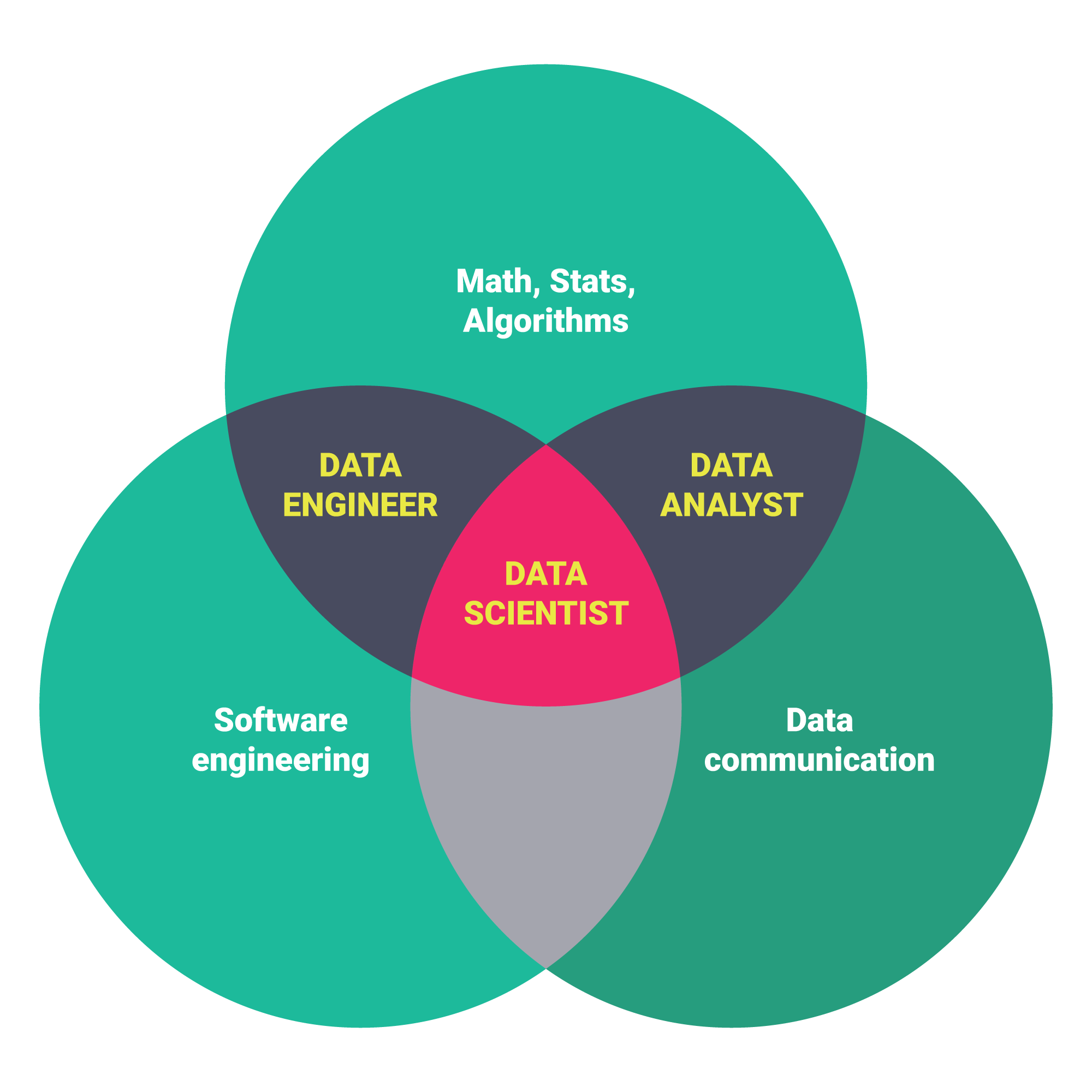
What is Data Science?
Data Science is one of the hottest topics on the Computer and Internet farmland nowadays. People have gathered data from applications and systems until today and now is the time to analyze them. The next steps are producing suggestions from the data and creating predictions about the future. Here you can find the biggest question for Data Science and hundreds of answers from experts.
| Link | Preview |
|---|---|
| What is Data Science @ O'reilly | Data scientists combine entrepreneurship with patience, the willingness to build data products incrementally, the ability to explore, and the ability to iterate over a solution. They are inherently interdisciplinary. They can tackle all aspects of a problem, from initial data collection and data conditioning to drawing conclusions. They can think outside the box to come up with new ways to view the problem, or to work with very broadly defined problems: “here’s a lot of data, what can you make from it?” |
| What is Data Science @ Quora | Data Science is a combination of a number of aspects of Data such as Technology, Algorithm development, and data interference to study the data, analyse it, and find innovative solutions to difficult problems. Basically Data Science is all about Analysing data and driving for business growth by finding creative ways. |
| The sexiest job of 21st century | Data scientists today are akin to Wall Street “quants” of the 1980s and 1990s. In those days people with backgrounds in physics and math streamed to investment banks and hedge funds, where they could devise entirely new algorithms and data strategies. Then a variety of universities developed master’s programs in financial engineering, which churned out a second generation of talent that was more accessible to mainstream firms. The pattern was repeated later in the 1990s with search engineers, whose rarefied skills soon came to be taught in computer science programs. |
| Wikipedia | Data science is an interdisciplinary field that uses scientific methods, processes, algorithms and systems to extract knowledge and insights from many structural and unstructured data. Data science is related to data mining, machine learning and big data. |
| How to Become a Data Scientist | Data scientists are big data wranglers, gathering and analyzing large sets of structured and unstructured data. A data scientist’s role combines computer science, statistics, and mathematics. They analyze, process, and model data then interpret the results to create actionable plans for companies and other organizations. |
| a very short history of #datascience | The story of how data scientists became sexy is mostly the story of the coupling of the mature discipline of statistics with a very young one--computer science. The term “Data Science” has emerged only recently to specifically designate a new profession that is expected to make sense of the vast stores of big data. But making sense of data has a long history and has been discussed by scientists, statisticians, librarians, computer scientists and others for years. The following timeline traces the evolution of the term “Data Science” and its use, attempts to define it, and related terms. |
| Software Development Resources for Data Scientists | Data scientists concentrate on making sense of data through exploratory analysis, statistics, and models. Software developers apply a separate set of knowledge with different tools. Although their focus may seem unrelated, data science teams can benefit from adopting software development best practices. Version control, automated testing, and other dev skills help create reproducible, production-ready code and tools. |
| Data Scientist Roadmap | Data science is an excellent career choice in today’s data-driven world where approx 328.77 million terabytes of data are generated daily. And this number is only increasing day by day, which in turn increases the demand for skilled data scientists who can utilize this data to drive business growth. |
| Navigating Your Path to Becoming a Data Scientist | _Data science is one of the most in-demand careers today. With businesses increasingly relying on data to make decisions, the need for skilled data scientists has grown rapidly. Whether it’s tech companies, healthcare organizations, or even government institutions, data scientists play a crucial role in turning raw data into valuable insights. But how do you become a data scientist, especially if you’re just starting out? _ |
Where do I Start?
While not strictly necessary, having a programming language is a crucial skill to be effective as a data scientist. Currently, the most popular language is Python, closely followed by R. Python is a general-purpose scripting language that sees applications in a wide variety of fields. R is a domain-specific language for statistics, which contains a lot of common statistics tools out of the box.
Python is by far the most popular language in science, due in no small part to the ease at which it can be used and the vibrant ecosystem of user-generated packages. To install packages, there are two main methods: Pip (invoked as pip install), the package manager that comes bundled with Python, and Anaconda (invoked as conda install), a powerful package manager that can install packages for Python, R, and can download executables like Git.
Unlike R, Python was not built from the ground up with data science in mind, but there are plenty of third party libraries to make up for this. A much more exhaustive list of packages can be found later in this document, but these four packages are a good set of choices to start your data science journey with: Scikit-Learn is a general-purpose data science package which implements the most popular algorithms - it also includes rich documentation, tutorials, and examples of the models it implements. Even if you prefer to write your own implementations, Scikit-Learn is a valuable reference to the nuts-and-bolts behind many of the common algorithms you'll find. With Pandas, one can collect and analyze their data into a convenient table format. Numpy provides very fast tooling for mathematical operations, with a focus on vectors and matrices. Seaborn, itself based on the Matplotlib package, is a quick way to generate beautiful visualizations of your data, with many good defaults available out of the box, as well as a gallery showing how to produce many common visualizations of your data.
When embarking on your journey to becoming a data scientist, the choice of language isn't particularly important, and both Python and R have their pros and cons. Pick a language you like, and check out one of the Free courses we've listed below!
Real World
Data science is a powerful tool that is utilized in various fields to solve real-world problems by extracting insights and patterns from complex data.
Disaster
-
deprem-ml AYA: Açık Yazılım Ağı (+25k developers) is trying to help disaster response using artificial intelligence. Everything is open-sourced afet.org.
Training Resources
How do you learn data science? By doing data science, of course! Okay, okay - that might not be particularly helpful when you're first starting out. In this section, we've listed some learning resources, in rough order from least to greatest commitment - Tutorials, Massively Open Online Courses (MOOCs), Intensive Programs, and Colleges.
Tutorials
- 1000 Data Science Projects you can run on the browser with IPython.
- #tidytuesday A weekly data project aimed at the R ecosystem.
- Data science your way
- PySpark Cheatsheet
- Machine Learning, Data Science and Deep Learning with Python
- How To Label Data
- Your Guide to Latent Dirichlet Allocation
- Over 1000 Data Science Online Courses at Classpert Online Search Engine
- Tutorials of source code from the book Genetic Algorithms with Python by Clinton Sheppard
- Tutorials to get started on signal processing for machine learning
- Realtime deployment Tutorial on Python time-series model deployment.
- Python for Data Science: A Beginner’s Guide
- Minimum Viable Study Plan for Machine Learning Interviews
- Understand and Know Machine Learning Engineering by Building Solid Projects
- 12 free Data Science projects to practice Python and Pandas
- Best CV/Resume for Data Science Freshers
- Understand Data Science Course in Java
- Data Analytics Interview Questions (Beginner to Advanced)
- Top 100+ Data Science Interview Questions and Answers
Free Courses
-
AI Expert Roadmap - Roadmap to becoming an Artificial Intelligence Expert
-
Convex Optimization - Convex Optimization (basics of convex analysis; least-squares, linear and quadratic programs, semidefinite programming, minimax, extremal volume, and other problems; optimality conditions, duality theory...)
-
Skillcombo - Data Science - 1000+ free online Data Science courses
-
Learning from Data - Introduction to machine learning covering basic theory, algorithms and applications
-
Kaggle - Learn about Data Science, Machine Learning, Python etc
-
ML Observability Fundamentals - Learn how to monitor and root-cause production ML issues.
-
Weights & Biases Effective MLOps: Model Development - Free Course and Certification for building an end-to-end machine using W&B
-
Python for Machine Learning - Start your journey to machine learning with Python, one of the most powerful programming languages.
-
Python for Data Science by Scaler - This course is designed to empower beginners with the essential skills to excel in today's data-driven world. The comprehensive curriculum will give you a solid foundation in statistics, programming, data visualization, and machine learning.
-
MLSys-NYU-2022 - Slides, scripts and materials for the Machine Learning in Finance course at NYU Tandon, 2022.
-
Hands-on Train and Deploy ML - A hands-on course to train and deploy a serverless API that predicts crypto prices.
-
LLMOps: Building Real-World Applications With Large Language Models - Learn to build modern software with LLMs using the newest tools and techniques in the field.
-
Prompt Engineering for Vision Models - Learn to prompt cutting-edge computer vision models with natural language, coordinate points, bounding boxes, segmentation masks, and even other images in this free course from DeepLearning.AI.
-
Data Science Course By IBM - Free resources and learn what data science is and how it’s used in different industries.
MOOC's
- Coursera Introduction to Data Science
- Data Science - 9 Steps Courses, A Specialization on Coursera
- Data Mining - 5 Steps Courses, A Specialization on Coursera
- Machine Learning – 5 Steps Courses, A Specialization on Coursera
- CS 109 Data Science
- OpenIntro
- CS 171 Visualization
- Process Mining: Data science in Action
- Oxford Deep Learning
- Oxford Deep Learning - video
- Oxford Machine Learning
- UBC Machine Learning - video
- Data Science Specialization
- Coursera Big Data Specialization
- Statistical Thinking for Data Science and Analytics by Edx
- Cognitive Class AI by IBM
- Udacity - Deep Learning
- Keras in Motion
- Microsoft Professional Program for Data Science
- COMP3222/COMP6246 - Machine Learning Technologies
- CS 231 - Convolutional Neural Networks for Visual Recognition
- Coursera Tensorflow in practice
- Coursera Deep Learning Specialization
- 365 Data Science Course
- Coursera Natural Language Processing Specialization
- Coursera GAN Specialization
- Codecademy's Data Science
- Linear Algebra - Linear Algebra course by Gilbert Strang
- A 2020 Vision of Linear Algebra (G. Strang)
- Python for Data Science Foundation Course
- Data Science: Statistics & Machine Learning
- Machine Learning Engineering for Production (MLOps)
- Recommender Systems Specialization from University of Minnesota is an intermediate/advanced level specialization focused on Recommender System on the Coursera platform.
- Stanford Artificial Intelligence Professional Program
- Data Scientist with Python
- Programming with Julia
- Scaler Data Science & Machine Learning Program
- Data Science Skill Tree
- Data Science for Beginners - Learn with AI tutor
- Machine Learning for Beginners - Learn with AI tutor
Intensive Programs
Colleges
- A list of colleges and universities offering degrees in data science.
- Data Science Degree @ Berkeley
- Data Science Degree @ UVA
- Data Science Degree @ Wisconsin
- BS in Data Science & Applications
- MS in Computer Information Systems @ Boston University
- MS in Business Analytics @ ASU Online
- MS in Applied Data Science @ Syracuse
- M.S. Management & Data Science @ Leuphana
- Master of Data Science @ Melbourne University
- Msc in Data Science @ The University of Edinburgh
- Master of Management Analytics @ Queen's University
- Master of Data Science @ Illinois Institute of Technology
- Master of Applied Data Science @ The University of Michigan
- Master Data Science and Artificial Intelligence @ Eindhoven University of Technology
- Master's Degree in Data Science and Computer Engineering @ University of Granada
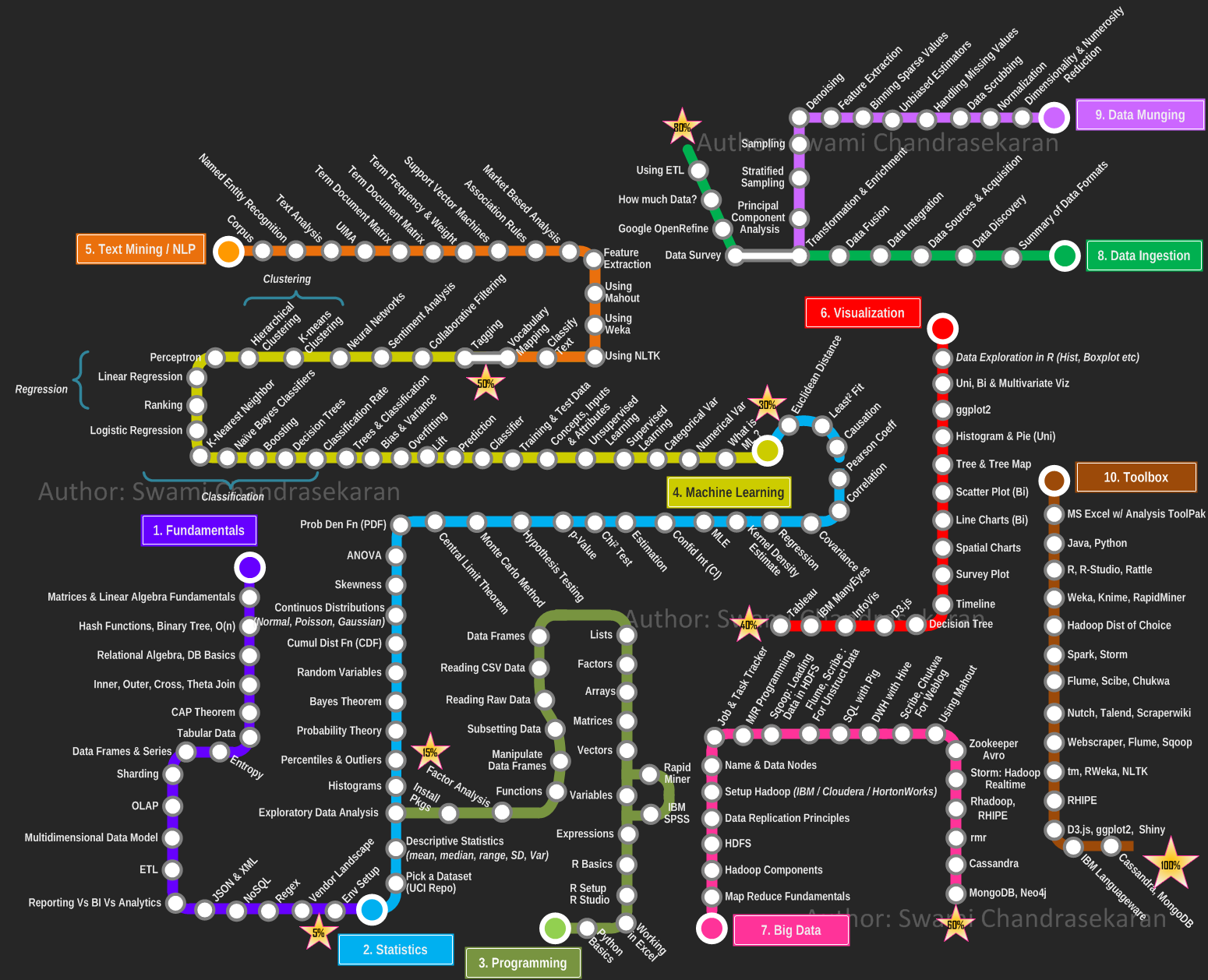
The Data Science Toolbox
This section is a collection of packages, tools, algorithms, and other useful items in the data science world.
Algorithms
These are some Machine Learning and Data Mining algorithms and models help you to understand your data and derive meaning from it.
Three kinds of Machine Learning Systems
- Based on training with human supervision
- Based on learning incrementally on fly
- Based on data points comparison and pattern detection
Comparison
- datacompy - DataComPy is a package to compare two Pandas DataFrames.
Supervised Learning
- Regression
- Linear Regression
- Ordinary Least Squares
- Logistic Regression
- Stepwise Regression
- Multivariate Adaptive Regression Splines
- Softmax Regression
- Locally Estimated Scatterplot Smoothing
- Classification
- Ensemble Learning
Unsupervised Learning
- Clustering
- Dimension Reduction
- Neural Networks
- Self-organizing map
- Adaptive resonance theory
- Hidden Markov Models (HMM)
Semi-Supervised Learning
- S3VM
- Clustering
- Generative models
- Low-density separation
- Laplacian regularization
- Heuristic approaches
Reinforcement Learning
Data Mining Algorithms
- C4.5
- k-Means
- SVM (Support Vector Machine)
- Apriori
- EM (Expectation-Maximization)
- PageRank
- AdaBoost
- KNN (K-Nearest Neighbors)
- Naive Bayes
- CART (Classification and Regression Trees)
Deep Learning architectures
- Multilayer Perceptron
- Convolutional Neural Network (CNN)
- Recurrent Neural Network (RNN)
- Boltzmann Machines
- Autoencoder
- Generative Adversarial Network (GAN)
- Self-Organized Maps
- Transformer
- Conditional Random Field (CRF)
- ML System Designs)
General Machine Learning Packages
- scikit-learn
- scikit-multilearn
- sklearn-expertsys
- scikit-feature
- scikit-rebate
- seqlearn
- sklearn-bayes
- sklearn-crfsuite
- sklearn-deap
- sigopt_sklearn
- sklearn-evaluation
- scikit-image
- scikit-opt
- scikit-posthocs
- pystruct
- Shogun
- xLearn
- cuML
- causalml
- mlpack
- MLxtend
- modAL
- Sparkit-learn
- hyperlearn
- dlib
- imodels
- RuleFit
- pyGAM
- Deepchecks
- scikit-survival
- interpretable
- XGBoost
- LightGBM
- CatBoost
- JAX
Deep Learning Packages
PyTorch Ecosystem
- PyTorch
- torchvision
- torchtext
- torchaudio
- ignite
- PyTorchNet
- PyToune
- skorch
- PyVarInf
- pytorch_geometric
- GPyTorch
- pyro
- Catalyst
- pytorch_tabular
- Yolov3
- Yolov5
- Yolov8
TensorFlow Ecosystem
- TensorFlow
- TensorLayer
- TFLearn
- Sonnet
- tensorpack
- TRFL
- Polyaxon
- NeuPy
- tfdeploy
- tensorflow-upstream
- TensorFlow Fold
- tensorlm
- TensorLight
- Mesh TensorFlow
- Ludwig
- TF-Agents
- TensorForce
Keras Ecosystem
Visualization Tools
- altair
- addepar
- amcharts
- anychart
- bokeh
- Comet
- slemma
- cartodb
- Cube
- d3plus
- Data-Driven Documents(D3js)
- dygraphs
- ECharts
- exhibit
- gephi
- ggplot2
- Glue
- Google Chart Gallery
- highcarts
- import.io
- jqplot
- Matplotlib
- nvd3
- Netron
- Openrefine
- plot.ly
- raw
- Resseract Lite
- Seaborn
- techanjs
- Timeline
- variancecharts
- vida
- vizzu
- Wrangler
- r2d3
- NetworkX
- Redash
- C3
- TensorWatch
- geomap
- Dash
Miscellaneous Tools
| Link | Description |
|---|---|
| The Data Science Lifecycle Process | The Data Science Lifecycle Process is a process for taking data science teams from Idea to Value repeatedly and sustainably. The process is documented in this repo |
| Data Science Lifecycle Template Repo | Template repository for data science lifecycle project |
| RexMex | A general purpose recommender metrics library for fair evaluation. |
| ChemicalX | A PyTorch based deep learning library for drug pair scoring. |
| PyTorch Geometric Temporal | Representation learning on dynamic graphs. |
| Little Ball of Fur | A graph sampling library for NetworkX with a Scikit-Learn like API. |
| Karate Club | An unsupervised machine learning extension library for NetworkX with a Scikit-Learn like API. |
| ML Workspace | All-in-one web-based IDE for machine learning and data science. The workspace is deployed as a Docker container and is preloaded with a variety of popular data science libraries (e.g., Tensorflow, PyTorch) and dev tools (e.g., Jupyter, VS Code) |
| Neptune.ai | Community-friendly platform supporting data scientists in creating and sharing machine learning models. Neptune facilitates teamwork, infrastructure management, models comparison and reproducibility. |
| steppy | Lightweight, Python library for fast and reproducible machine learning experimentation. Introduces very simple interface that enables clean machine learning pipeline design. |
| steppy-toolkit | Curated collection of the neural networks, transformers and models that make your machine learning work faster and more effective. |
| Datalab from Google | easily explore, visualize, analyze, and transform data using familiar languages, such as Python and SQL, interactively. |
| Hortonworks Sandbox | is a personal, portable Hadoop environment that comes with a dozen interactive Hadoop tutorials. |
| R | is a free software environment for statistical computing and graphics. |
| Tidyverse | is an opinionated collection of R packages designed for data science. All packages share an underlying design philosophy, grammar, and data structures. |
| RStudio | IDE – powerful user interface for R. It’s free and open source, and works on Windows, Mac, and Linux. |
| Python - Pandas - Anaconda | Completely free enterprise-ready Python distribution for large-scale data processing, predictive analytics, and scientific computing |
| Pandas GUI | Pandas GUI |
| Scikit-Learn | Machine Learning in Python |
| NumPy | NumPy is fundamental for scientific computing with Python. It supports large, multi-dimensional arrays and matrices and includes an assortment of high-level mathematical functions to operate on these arrays. |
| Vaex | Vaex is a Python library that allows you to visualize large datasets and calculate statistics at high speeds. |
| SciPy | SciPy works with NumPy arrays and provides efficient routines for numerical integration and optimization. |
| Data Science Toolbox | Coursera Course |
| Data Science Toolbox | Blog |
| Wolfram Data Science Platform | Take numerical, textual, image, GIS or other data and give it the Wolfram treatment, carrying out a full spectrum of data science analysis and visualization and automatically generate rich interactive reports—all powered by the revolutionary knowledge-based Wolfram Language. |
| Datadog | Solutions, code, and devops for high-scale data science. |
| Variance | Build powerful data visualizations for the web without writing JavaScript |
| Kite Development Kit | The Kite Software Development Kit (Apache License, Version 2.0), or Kite for short, is a set of libraries, tools, examples, and documentation focused on making it easier to build systems on top of the Hadoop ecosystem. |
| Domino Data Labs | Run, scale, share, and deploy your models — without any infrastructure or setup. |
| Apache Flink | A platform for efficient, distributed, general-purpose data processing. |
| Apache Hama | Apache Hama is an Apache Top-Level open source project, allowing you to do advanced analytics beyond MapReduce. |
| Weka | Weka is a collection of machine learning algorithms for data mining tasks. |
| Octave | GNU Octave is a high-level interpreted language, primarily intended for numerical computations.(Free Matlab) |
| Apache Spark | Lightning-fast cluster computing |
| Hydrosphere Mist | a service for exposing Apache Spark analytics jobs and machine learning models as realtime, batch or reactive web services. |
| Data Mechanics | A data science and engineering platform making Apache Spark more developer-friendly and cost-effective. |
| Caffe | Deep Learning Framework |
| Torch | A SCIENTIFIC COMPUTING FRAMEWORK FOR LUAJIT |
| Nervana's python based Deep Learning Framework | Intel® Nervana™ reference deep learning framework committed to best performance on all hardware. |
| Skale | High performance distributed data processing in NodeJS |
| Aerosolve | A machine learning package built for humans. |
| Intel framework | Intel® Deep Learning Framework |
| Datawrapper | An open source data visualization platform helping everyone to create simple, correct and embeddable charts. Also at github.com |
| Tensor Flow | TensorFlow is an Open Source Software Library for Machine Intelligence |
| Natural Language Toolkit | An introductory yet powerful toolkit for natural language processing and classification |
| Annotation Lab | Free End-to-End No-Code platform for text annotation and DL model training/tuning. Out-of-the-box support for Named Entity Recognition, Classification, Relation extraction and Assertion Status Spark NLP models. Unlimited support for users, teams, projects, documents. |
| nlp-toolkit for node.js | This module covers some basic nlp principles and implementations. The main focus is performance. When we deal with sample or training data in nlp, we quickly run out of memory. Therefore every implementation in this module is written as stream to only hold that data in memory that is currently processed at any step. |
| Julia | high-level, high-performance dynamic programming language for technical computing |
| IJulia | a Julia-language backend combined with the Jupyter interactive environment |
| Apache Zeppelin | Web-based notebook that enables data-driven, interactive data analytics and collaborative documents with SQL, Scala and more |
| Featuretools | An open source framework for automated feature engineering written in python |
| Optimus | Cleansing, pre-processing, feature engineering, exploratory data analysis and easy ML with PySpark backend. |
| Albumentations | А fast and framework agnostic image augmentation library that implements a diverse set of augmentation techniques. Supports classification, segmentation, and detection out of the box. Was used to win a number of Deep Learning competitions at Kaggle, Topcoder and those that were a part of the CVPR workshops. |
| DVC | An open-source data science version control system. It helps track, organize and make data science projects reproducible. In its very basic scenario it helps version control and share large data and model files. |
| Lambdo | is a workflow engine that significantly simplifies data analysis by combining in one analysis pipeline (i) feature engineering and machine learning (ii) model training and prediction (iii) table population and column evaluation. |
| Feast | A feature store for the management, discovery, and access of machine learning features. Feast provides a consistent view of feature data for both model training and model serving. |
| Polyaxon | A platform for reproducible and scalable machine learning and deep learning. |
| LightTag | Text Annotation Tool for teams |
| UBIAI | Easy-to-use text annotation tool for teams with most comprehensive auto-annotation features. Supports NER, relations and document classification as well as OCR annotation for invoice labeling |
| Trains | Auto-Magical Experiment Manager, Version Control & DevOps for AI |
| Hopsworks | Open-source data-intensive machine learning platform with a feature store. Ingest and manage features for both online (MySQL Cluster) and offline (Apache Hive) access, train and serve models at scale. |
| MindsDB | MindsDB is an Explainable AutoML framework for developers. With MindsDB you can build, train and use state of the art ML models in as simple as one line of code. |
| Lightwood | A Pytorch based framework that breaks down machine learning problems into smaller blocks that can be glued together seamlessly with an objective to build predictive models with one line of code. |
| AWS Data Wrangler | An open-source Python package that extends the power of Pandas library to AWS connecting DataFrames and AWS data related services (Amazon Redshift, AWS Glue, Amazon Athena, Amazon EMR, etc). |
| Amazon Rekognition | AWS Rekognition is a service that lets developers working with Amazon Web Services add image analysis to their applications. Catalog assets, automate workflows, and extract meaning from your media and applications. |
| Amazon Textract | Automatically extract printed text, handwriting, and data from any document. |
| Amazon Lookout for Vision | Spot product defects using computer vision to automate quality inspection. Identify missing product components, vehicle and structure damage, and irregularities for comprehensive quality control. |
| Amazon CodeGuru | Automate code reviews and optimize application performance with ML-powered recommendations. |
| CML | An open source toolkit for using continuous integration in data science projects. Automatically train and test models in production-like environments with GitHub Actions & GitLab CI, and autogenerate visual reports on pull/merge requests. |
| Dask | An open source Python library to painlessly transition your analytics code to distributed computing systems (Big Data) |
| Statsmodels | A Python-based inferential statistics, hypothesis testing and regression framework |
| Gensim | An open-source library for topic modeling of natural language text |
| spaCy | A performant natural language processing toolkit |
| Grid Studio | Grid studio is a web-based spreadsheet application with full integration of the Python programming language. |
| Python Data Science Handbook | Python Data Science Handbook: full text in Jupyter Notebooks |
| Shapley | A data-driven framework to quantify the value of classifiers in a machine learning ensemble. |
| DAGsHub | A platform built on open source tools for data, model and pipeline management. |
| Deepnote | A new kind of data science notebook. Jupyter-compatible, with real-time collaboration and running in the cloud. |
| Valohai | An MLOps platform that handles machine orchestration, automatic reproducibility and deployment. |
| PyMC3 | A Python Library for Probabalistic Programming (Bayesian Inference and Machine Learning) |
| PyStan | Python interface to Stan (Bayesian inference and modeling) |
| hmmlearn | Unsupervised learning and inference of Hidden Markov Models |
| Chaos Genius | ML powered analytics engine for outlier/anomaly detection and root cause analysis |
| Nimblebox | A full-stack MLOps platform designed to help data scientists and machine learning practitioners around the world discover, create, and launch multi-cloud apps from their web browser. |
| Towhee | A Python library that helps you encode your unstructured data into embeddings. |
| LineaPy | Ever been frustrated with cleaning up long, messy Jupyter notebooks? With LineaPy, an open source Python library, it takes as little as two lines of code to transform messy development code into production pipelines. |
| envd | 🏕️ machine learning development environment for data science and AI/ML engineering teams |
| Explore Data Science Libraries | A search engine 🔎 tool to discover & find a curated list of popular & new libraries, top authors, trending project kits, discussions, tutorials & learning resources |
| MLEM | 🐶 Version and deploy your ML models following GitOps principles |
| MLflow | MLOps framework for managing ML models across their full lifecycle |
| cleanlab | Python library for data-centric AI and automatically detecting various issues in ML datasets |
| AutoGluon | AutoML to easily produce accurate predictions for image, text, tabular, time-series, and multi-modal data |
| Arize AI | Arize AI community tier observability tool for monitoring machine learning models in production and root-causing issues such as data quality and performance drift. |
| Aureo.io | Aureo.io is a low-code platform that focuses on building artificial intelligence. It provides users with the capability to create pipelines, automations and integrate them with artificial intelligence models – all with their basic data. |
| ERD Lab | Free cloud based entity relationship diagram (ERD) tool made for developers. |
| Arize-Phoenix | MLOps in a notebook - uncover insights, surface problems, monitor, and fine tune your models. |
| Comet | An MLOps platform with experiment tracking, model production management, a model registry, and full data lineage to support your ML workflow from training straight through to production. |
| Opik | Evaluate, test, and ship LLM applications across your dev and production lifecycles. |
| Synthical | AI-powered collaborative environment for research. Find relevant papers, create collections to manage bibliography, and summarize content — all in one place |
| teeplot | Workflow tool to automatically organize data visualization output |
| Streamlit | App framework for Machine Learning and Data Science projects |
| Gradio | Create customizable UI components around machine learning models |
| Weights & Biases | Experiment tracking, dataset versioning, and model management |
| DVC | Open-source version control system for machine learning projects |
| Optuna | Automatic hyperparameter optimization software framework |
| Ray Tune | Scalable hyperparameter tuning library |
| Apache Airflow | Platform to programmatically author, schedule, and monitor workflows |
| Prefect | Workflow management system for modern data stacks |
| Kedro | Open-source Python framework for creating reproducible, maintainable data science code |
| Hamilton | Lightweight library to author and manage reliable data transformations |
| SHAP | Game theoretic approach to explain the output of any machine learning model |
| LIME | Explaining the predictions of any machine learning classifier |
| flyte | Workflow automation platform for machine learning |
| dbt | Data build tool |
| SHAP | Game theoretic approach to explain the output of any machine learning model |
| LIME | Explaining the predictions of any machine learning classifier |
Literature and Media
This section includes some additional reading material, channels to watch, and talks to listen to.
Books
- Data Science From Scratch: First Principles with Python
- Artificial Intelligence with Python - Tutorialspoint
- Machine Learning from Scratch
- Probabilistic Machine Learning: An Introduction
- A Comprehensive Guide to Machine Learning
- How to Lead in Data Science - Early Access
- Fighting Churn With Data
- Data Science at Scale with Python and Dask
- Python Data Science Handbook
- The Data Science Handbook: Advice and Insights from 25 Amazing Data Scientists
- Think Like a Data Scientist
- Introducing Data Science
- Practical Data Science with R
- Everyday Data Science & (cheaper PDF version)
- Exploring Data Science - free eBook sampler
- Exploring the Data Jungle - free eBook sampler
- Classic Computer Science Problems in Python
- Math for Programmers Early access
- R in Action, Third Edition Early Access
- Data Science Bookcamp Early access
- Data Science Thinking: The Next Scientific, Technological and Economic Revolution
- Applied Data Science: Lessons Learned for the Data-Driven Business
- The Data Science Handbook
- Essential Natural Language Processing - Early access
- Mining Massive Datasets - free e-book comprehended by an online course
- Pandas in Action - Early access
- Genetic Algorithms and Genetic Programming
- Advances in Evolutionary Algorithms - Free Download
- Genetic Programming: New Approaches and Successful Applications - Free Download
- Evolutionary Algorithms - Free Download
- Advances in Genetic Programming, Vol. 3 - Free Download
- Global Optimization Algorithms: Theory and Application - Free Download
- Genetic Algorithms and Evolutionary Computation - Free Download
- Convex Optimization - Convex Optimization book by Stephen Boyd - Free Download
- Data Analysis with Python and PySpark - Early Access
- R for Data Science
- Build a Career in Data Science
- Machine Learning Bookcamp - Early access
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition
- Effective Data Science Infrastructure
- Practical MLOps: How to Get Ready for Production Models
- Data Analysis with Python and PySpark
- Regression, a Friendly guide - Early Access
- Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing
- Data Science at the Command Line: Facing the Future with Time-Tested Tools
- Machine Learning - CIn UFPE
- Machine Learning with Python - Tutorialspoint
- Deep Learning
- Designing Cloud Data Platforms - Early Access
- An Introduction to Statistical Learning with Applications in R
- The Elements of Statistical Learning: Data Mining, Inference, and Prediction
- Deep Learning with PyTorch
- Neural Networks and Deep Learning
- Deep Learning Cookbook
- Introduction to Machine Learning with Python
- Artificial Intelligence: Foundations of Computational Agents, 2nd Edition - Free HTML version
- The Quest for Artificial Intelligence: A History of Ideas and Achievements - Free Download
- Graph Algorithms for Data Science - Early Access
- Data Mesh in Action - Early Access
- Julia for Data Analysis - Early Access
- Casual Inference for Data Science - Early Access
- Regular Expression Puzzles and AI Coding Assistants by David Mertz
- Dive into Deep Learning
- Data for All
- Interpretable Machine Learning: A Guide for Making Black Box Models Explainable - Free GitHub version
- Foundations of Data Science Free Download
- Comet for DataScience: Enhance your ability to manage and optimize the life cycle of your data science project
- Software Engineering for Data Scientists - Early Access
- Julia for Data Science - Early Access
- An Introduction to Statistical Learning - Download Page
- Machine Learning For Absolute Beginners
- Unifying Business, Data, and Code: Designing Data Products with JSON Schema
Book Deals (Affiliated) 🛍
Journals, Publications and Magazines
- ICML - International Conference on Machine Learning
- GECCO - The Genetic and Evolutionary Computation Conference (GECCO)
- epjdatascience
- Journal of Data Science - an international journal devoted to applications of statistical methods at large
- Big Data Research
- Journal of Big Data
- Big Data & Society
- Data Science Journal
- datatau.com/news - Like Hacker News, but for data
- Data Science Trello Board
- Medium Data Science Topic - Data Science related publications on medium
- Towards Data Science Genetic Algorithm Topic -Genetic Algorithm related Publications towards Data Science
- all AI news - The AI/ML/Big Data news aggregator platform
Newsletters
- AI Digest. A weekly newsletter to keep up to date with AI, machine learning, and data science. Archive.
- DataTalks.Club. A weekly newsletter about data-related things. Archive.
- The Analytics Engineering Roundup. A newsletter about data science. Archive.
Bloggers
- Wes McKinney - Wes McKinney Archives.
- Matthew Russell - Mining The Social Web.
- Greg Reda - Greg Reda Personal Blog
- Kevin Davenport - Kevin Davenport Personal Blog
- Julia Evans - Recurse Center alumna
- Hakan Kardas - Personal Web Page
- Sean J. Taylor - Personal Web Page
- Drew Conway - Personal Web Page
- Hilary Mason - Personal Web Page
- Noah Iliinsky - Personal Blog
- Matt Harrison - Personal Blog
- Vamshi Ambati - AllThings Data Sciene
- Prash Chan - Tech Blog on Master Data Management And Every Buzz Surrounding It
- Clare Corthell - The Open Source Data Science Masters
- Paul Miller Based in the UK and working globally, Cloud of Data's consultancy services help clients understand the implications of taking data and more to the Cloud.
- Data Science London Data Science London is a non-profit organization dedicated to the free, open, dissemination of data science. We are the largest data science community in Europe. We are more than 3,190 data scientists and data geeks in our community.
- Datawrangling by Peter Skomoroch. MACHINE LEARNING, DATA MINING, AND MORE
- Quora Data Science - Data Science Questions and Answers from experts
- Siah a PhD student at Berkeley
- Louis Dorard a technology guy with a penchant for the web and for data, big and small
- Machine Learning Mastery about helping professional programmers confidently apply machine learning algorithms to address complex problems.
- Daniel Forsyth - Personal Blog
- Data Science Weekly - Weekly News Blog
- Revolution Analytics - Data Science Blog
- R Bloggers - R Bloggers
- The Practical Quant Big data
- Yet Another Data Blog Yet Another Data Blog
- Spenczar a data scientist at Twitch. I handle the whole data pipeline, from tracking to model-building to reporting.
- KD Nuggets Data Mining, Analytics, Big Data, Data, Science not a blog a portal
- Meta Brown - Personal Blog
- Data Scientist is building the data scientist culture.
- WhatSTheBigData is some of, all of, or much more than the above and this blog explores its impact on information technology, the business world, government agencies, and our lives.
- Tevfik Kosar - Magnus Notitia
- New Data Scientist How a Social Scientist Jumps into the World of Big Data
- Harvard Data Science - Thoughts on Statistical Computing and Visualization
- Data Science 101 - Learning To Be A Data Scientist
- Kaggle Past Solutions
- DataScientistJourney
- NYC Taxi Visualization Blog
- Learning Lover
- Dataists
- Data-Mania
- Data-Magnum
- P-value - Musings on data science, machine learning, and stats.
- datascopeanalytics
- Digital transformation
- datascientistjourney
- Data Mania Blog - The File Drawer - Chris Said's science blog
- Emilio Ferrara's web page
- DataNews
- Reddit TextMining
- Periscopic
- Hilary Parker
- Data Stories
- Data Science Lab
- Meaning of
- Adventures in Data Land
- DATA MINERS BLOG
- Dataclysm
- FlowingData - Visualization and Statistics
- Calculated Risk
- O'reilly Learning Blog
- Dominodatalab
- i am trask - A Machine Learning Craftsmanship Blog
- Vademecum of Practical Data Science - Handbook and recipes for data-driven solutions of real-world problems
- Dataconomy - A blog on the newly emerging data economy
- Springboard - A blog with resources for data science learners
- Analytics Vidhya - A full-fledged website about data science and analytics study material.
- Occam's Razor - Focused on Web Analytics.
- Data School - Data science tutorials for beginners!
- Colah's Blog - Blog for understanding Neural Networks!
- Sebastian's Blog - Blog for NLP and transfer learning!
- Distill - Dedicated to clear explanations of machine learning!
- Chris Albon's Website - Data Science and AI notes
- Andrew Carr - Data Science with Esoteric programming languages
- floydhub - Blog for Evolutionary Algorithms
- Jingles - Review and extract key concepts from academic papers
- nbshare - Data Science notebooks
- Deep and Shallow - All things Deep and Shallow in Data Science
- Loic Tetrel - Data science blog
- Chip Huyen's Blog - ML Engineering, MLOps, and the use of ML in startups
- Maria Khalusova - Data science blog
- Aditi Rastogi - ML,DL,Data Science blog
- Santiago Basulto - Data Science with Python
- Akhil Soni - ML, DL and Data Science
- Akhil Soni - ML, DL and Data Science
Presentations
- How to Become a Data Scientist
- Introduction to Data Science
- Intro to Data Science for Enterprise Big Data
- How to Interview a Data Scientist
- How to Share Data with a Statistician
- The Science of a Great Career in Data Science
- What Does a Data Scientist Do?
- Building Data Start-Ups: Fast, Big, and Focused
- How to win data science competitions with Deep Learning
- Full-Stack Data Scientist
Podcasts
- AI at Home
- AI Today
- Adversarial Learning
- Becoming a Data Scientist
- Chai time Data Science
- Data Crunch
- Data Engineering Podcast
- Data Science at Home
- Data Science Mixer
- Data Skeptic
- Data Stories
- Datacast
- DataFramed
- DataTalks.Club
- Gradient Descent
- Learning Machines 101
- Let's Data (Brazil)
- Linear Digressions
- Not So Standard Deviations
- O'Reilly Data Show Podcast
- Partially Derivative
- Superdatascience
- The Data Engineering Show
- The Radical AI Podcast
- The Robot Brains Podcast
- What's The Point
- How AI Built This
- The Analytics Engineering Podcast
YouTube Videos & Channels
- What is machine learning?
- Andrew Ng: Deep Learning, Self-Taught Learning and Unsupervised Feature Learning
- Data36 - Data Science for Beginners by Tomi Mester
- Deep Learning: Intelligence from Big Data
- Interview with Google's AI and Deep Learning 'Godfather' Geoffrey Hinton
- Introduction to Deep Learning with Python
- What is machine learning, and how does it work?
- Data School - Data Science Education
- Neural Nets for Newbies by Melanie Warrick (May 2015)
- Neural Networks video series by Hugo Larochelle
- Google DeepMind co-founder Shane Legg - Machine Super Intelligence
- Data Science Primer
- Data Science with Genetic Algorithms
- Data Science for Beginners
- DataTalks.Club
- Mildlyoverfitted - Tutorials on intermediate ML/DL topics
- mlops.community - Interviews of industry experts about production ML
- ML Street Talk - Unabashedly technical and non-commercial, so you will hear no annoying pitches.
- Neural networks by 3Blue1Brown
- Neural networks from scratch by Sentdex
- Manning Publications YouTube channel
- Ask Dr Chong: How to Lead in Data Science - Part 1
- Ask Dr Chong: How to Lead in Data Science - Part 2
- Ask Dr Chong: How to Lead in Data Science - Part 3
- Ask Dr Chong: How to Lead in Data Science - Part 4
- Ask Dr Chong: How to Lead in Data Science - Part 5
- Ask Dr Chong: How to Lead in Data Science - Part 6
- Regression Models: Applying simple Poisson regression
- Deep Learning Architectures
- Time Series Modelling and Analysis
Socialize
Below are some Social Media links. Connect with other data scientists!
- Facebook Accounts
- Twitter Accounts
- Telegram Channels
- Slack Communities
- GitHub Groups
- Data Science Competitions
Facebook Accounts
- Data
- Big Data Scientist
- Data Science Day
- Data Science Academy
- Facebook Data Science Page
- Data Science London
- Data Science Technology and Corporation
- Data Science - Closed Group
- Center for Data Science
- Big data hadoop NOSQL Hive Hbase
- Analytics, Data Mining, Predictive Modeling, Artificial Intelligence
- Big Data Analytics using R
- Big Data Analytics with R and Hadoop
- Big Data Learnings
- Big Data, Data Science, Data Mining & Statistics
- BigData/Hadoop Expert
- Data Mining / Machine Learning / AI
- Data Mining/Big Data - Social Network Ana
- Vademecum of Practical Data Science
- Veri Bilimi Istanbul
- The Data Science Blog
Twitter Accounts
| Description | |
|---|---|
| Big Data Combine | Rapid-fire, live tryouts for data scientists seeking to monetize their models as trading strategies |
| Big Data Mania | Data Viz Wiz, Data Journalist, Growth Hacker, Author of Data Science for Dummies (2015) |
| Big Data Science | Big Data, Data Science, Predictive Modeling, Business Analytics, Hadoop, Decision and Operations Research. |
| Charlie Greenbacker | Director of Data Science at @ExploreAltamira |
| Chris Said | Data scientist at Twitter |
| Clare Corthell | Dev, Design, Data Science @mattermark #hackerei |
| DADI Charles-Abner | #datascientist @Ekimetrics. , #machinelearning #dataviz #DynamicCharts #Hadoop #R #Python #NLP #Bitcoin #dataenthousiast |
| Data Science Central | Data Science Central is the industry's single resource for Big Data practitioners. |
| Data Science London | Data Science. Big Data. Data Hacks. Data Junkies. Data Startups. Open Data |
| Data Science Renee | Documenting my path from SQL Data Analyst pursuing an Engineering Master's Degree to Data Scientist |
| Data Science Report | Mission is to help guide & advance careers in Data Science & Analytics |
| Data Science Tips | Tips and Tricks for Data Scientists around the world! #datascience #bigdata |
| Data Vizzard | DataViz, Security, Military |
| DataScienceX | |
| deeplearning4j | |
| DJ Patil | White House Data Chief, VP @ RelateIQ. |
| Domino Data Lab | |
| Drew Conway | Data nerd, hacker, student of conflict. |
| Emilio Ferrara | #Networks, #MachineLearning and #DataScience. I work on #Social Media. Postdoc at @IndianaUniv |
| Erin Bartolo | Running with #BigData--enjoying a love/hate relationship with its hype. @iSchoolSU #DataScience Program Mgr. |
| Greg Reda | Working @ GrubHub about data and pandas |
| Gregory Piatetsky | KDnuggets President, Analytics/Big Data/Data Mining/Data Science expert, KDD & SIGKDD co-founder, was Chief Scientist at 2 startups, part-time philosopher. |
| Hadley Wickham | Chief Scientist at RStudio, and an Adjunct Professor of Statistics at the University of Auckland, Stanford University, and Rice University. |
| Hakan Kardas | Data Scientist |
| Hilary Mason | Data Scientist in Residence at @accel. |
| Jeff Hammerbacher | ReTweeting about data science |
| John Myles White | Scientist at Facebook and Julia developer. Author of Machine Learning for Hackers and Bandit Algorithms for Website Optimization. Tweets reflect my views only. |
| Juan Miguel Lavista | Principal Data Scientist @ Microsoft Data Science Team |
| Julia Evans | Hacker - Pandas - Data Analyze |
| Kenneth Cukier | The Economist's Data Editor and co-author of Big Data (http://www.big-data-book.com/). |
| Kevin Davenport | Organizer of https://www.meetup.com/San-Diego-Data-Science-R-Users-Group/ |
| Kevin Markham | Data science instructor, and founder of Data School |
| Kim Rees | Interactive data visualization and tools. Data flaneur. |
| Kirk Borne | DataScientist, PhD Astrophysicist, Top #BigData Influencer. |
| Linda Regber | Data storyteller, visualizations. |
| Luis Rei | PhD Student. Programming, Mobile, Web. Artificial Intelligence, Intelligent Robotics Machine Learning, Data Mining, Natural Language Processing, Data Science. |
| Mark Stevenson | Data Analytics Recruitment Specialist at Salt (@SaltJobs) Analytics - Insight - Big Data - Data science |
| Matt Harrison | Opinions of full-stack Python guy, author, instructor, currently playing Data Scientist. Occasional fathering, husbanding, organic gardening. |
| Matthew Russell | Mining the Social Web. |
| Mert Nuhoğlu | Data Scientist at BizQualify, Developer |
| Monica Rogati | Data @ Jawbone. Turned data into stories & products at LinkedIn. Text mining, applied machine learning, recommender systems. Ex-gamer, ex-machine coder; namer. |
| Noah Iliinsky | Visualization & interaction designer. Practical cyclist. Author of vis books: https://www.oreilly.com/pub/au/4419 |
| Paul Miller | Cloud Computing/ Big Data/ Open Data Analyst & Consultant. Writer, Speaker & Moderator. Gigaom Research Analyst. |
| Peter Skomoroch | Creating intelligent systems to automate tasks & improve decisions. Entrepreneur, ex-Principal Data Scientist @LinkedIn. Machine Learning, ProductRei, Networks |
| Prash Chan | Solution Architect @ IBM, Master Data Management, Data Quality & Data Governance Blogger. Data Science, Hadoop, Big Data & Cloud. |
| Quora Data Science | Quora's data science topic |
| R-Bloggers | Tweet blog posts from the R blogosphere, data science conferences, and (!) open jobs for data scientists. |
| Rand Hindi | |
| Randy Olson | Computer scientist researching artificial intelligence. Data tinkerer. Community leader for @DataIsBeautiful. #OpenScience advocate. |
| Recep Erol | Data Science geek @ UALR |
| Ryan Orban | Data scientist, genetic origamist, hardware aficionado |
| Sean J. Taylor | Social Scientist. Hacker. Facebook Data Science Team. Keywords: Experiments, Causal Inference, Statistics, Machine Learning, Economics. |
| Silvia K. Spiva | #DataScience at Cisco |
| Harsh B. Gupta | Data Scientist at BBVA Compass |
| Spencer Nelson | Data nerd |
| Talha Oz | Enjoys ABM, SNA, DM, ML, NLP, HI, Python, Java. Top percentile Kaggler/data scientist |
| Tasos Skarlatidis | Complex Event Processing, Big Data, Artificial Intelligence and Machine Learning. Passionate about programming and open-source. |
| Terry Timko | InfoGov; Bigdata; Data as a Service; Data Science; Open, Social & Business Data Convergence |
| Tony Baer | IT analyst with Ovum covering Big Data & data management with some systems engineering thrown in. |
| Tony Ojeda | Data Scientist , Author , Entrepreneur. Co-founder @DataCommunityDC. Founder @DistrictDataLab. #DataScience #BigData #DataDC |
| Vamshi Ambati | Data Science @ PayPal. #NLP, #machinelearning; PhD, Carnegie Mellon alumni (Blog: https://allthingsds.wordpress.com ) |
| Wes McKinney | Pandas (Python Data Analysis library). |
| WileyEd | Senior Manager - @Seagate Big Data Analytics @McKinsey Alum #BigData + #Analytics Evangelist #Hadoop, #Cloud, #Digital, & #R Enthusiast |
| WNYC Data News Team | The data news crew at @WNYC. Practicing data-driven journalism, making it visual, and showing our work. |
| Alexey Grigorev | Data science author |
| İlker Arslan | Data science author. Shares mostly about Julia programming |
| INEVITABLE | AI & Data Science Start-up Company based in England, UK |
Telegram Channels
- Open Data Science – First Telegram Data Science channel. Covering all technical and popular staff about anything related to Data Science: AI, Big Data, Machine Learning, Statistics, general Math and the applications of former.
- Loss function porn — Beautiful posts on DS/ML theme with video or graphic visualization.
- Machinelearning – Daily ML news.
Slack Communities
GitHub Groups
Data Science Competitions
Some data mining competition platforms
Fun
Infographics
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Datasets
- Academic Torrents
- ADS-B Exchange - Specific datasets for aircraft and Automatic Dependent Surveillance-Broadcast (ADS-B) sources.
- hadoopilluminated.com
- data.gov - The home of the U.S. Government's open data
- United States Census Bureau
- usgovxml.com
- enigma.com - Navigate the world of public data - Quickly search and analyze billions of public records published by governments, companies and organizations.
- datahub.io
- aws.amazon.com/datasets
- datacite.org
- The official portal for European data
- NASDAQ:DATA - Nasdaq Data Link A premier source for financial, economic and alternative datasets.
- figshare.com
- GeoLite Legacy Downloadable Databases
- Quora's Big Datasets Answer
- Public Big Data Sets
- Kaggle Datasets
- A Deep Catalog of Human Genetic Variation
- A community-curated database of well-known people, places, and things
- Google Public Data
- World Bank Data
- NYC Taxi data
- Open Data Philly Connecting people with data for Philadelphia
- grouplens.org Sample movie (with ratings), book and wiki datasets
- UC Irvine Machine Learning Repository - contains data sets good for machine learning
- research-quality data sets by Hilary Mason
- National Centers for Environmental Information
- ClimateData.us (related: U.S. Climate Resilience Toolkit)
- r/datasets
- MapLight - provides a variety of data free of charge for uses that are freely available to the general public. Click on a data set below to learn more
- GHDx - Institute for Health Metrics and Evaluation - a catalog of health and demographic datasets from around the world and including IHME results
- St. Louis Federal Reserve Economic Data - FRED
- New Zealand Institute of Economic Research – Data1850
- Open Data Sources
- UNICEF Data
- undata
- NASA SocioEconomic Data and Applications Center - SEDAC
- The GDELT Project
- Sweden, Statistics
- StackExchange Data Explorer - an open source tool for running arbitrary queries against public data from the Stack Exchange network.
- SocialGrep - a collection of open Reddit datasets.
- San Fransisco Government Open Data
- IBM Asset Dataset
- Open data Index
- Public Git Archive
- GHTorrent
- Microsoft Research Open Data
- Open Government Data Platform India
- Google Dataset Search (beta)
- NAYN.CO Turkish News with categories
- Covid-19
- Covid-19 Google
- Enron Email Dataset
- 5000 Images of Clothes
- IBB Open Portal
- The Humanitarian Data Exchange
Comics
Other Awesome Lists
- Other amazingly awesome lists can be found in the awesome-awesomeness
- Awesome Machine Learning
- lists
- awesome-dataviz
- awesome-python
- Data Science IPython Notebooks.
- awesome-r
- awesome-datasets
- awesome-Machine Learning & Deep Learning Tutorials
- Awesome Data Science Ideas
- Machine Learning for Software Engineers
- Community Curated Data Science Resources
- Awesome Machine Learning On Source Code
- Awesome Community Detection
- Awesome Graph Classification
- Awesome Decision Tree Papers
- Awesome Fraud Detection Papers
- Awesome Gradient Boosting Papers
- Awesome Computer Vision Models
- Awesome Monte Carlo Tree Search
- Glossary of common statistics and ML terms
- 100 NLP Papers
- Awesome Game Datasets
- Data Science Interviews Questions
- Awesome Explainable Graph Reasoning
- Top Data Science Interview Questions
- Awesome Drug Synergy, Interaction and Polypharmacy Prediction
- Deep Learning Interview Questions
- Top Future Trends in Data Science in 2023
- How Generative AI Is Changing Creative Work
- What is generative AI?
- Top 100+ Machine Learning Interview Questions (Beginner to Advanced)