Awesome
![]()
Looking for a person who would like to help me maintain this repository! Contact me on LN or simply add a PR!
Data augmentation
List of useful data augmentation resources. You will find here some links to more or less popular github repos :sparkles:, libraries, papers :books: and other information.
Do you like it? Feel free to :star: ! Feel free to make a pull request!
Featured ⭐
Data augmentation for bias mitigation?
- Targeted Data Augmentation for bias mitigation; Agnieszka Mikołajczyk-Bareła, Maria Ferlin, Michał Grochowski; The development of fair and ethical AI systems requires careful consideration of bias mitigation, an area often overlooked or ignored. In this study, we introduce a novel and efficient approach for addressing biases called Targeted Data Augmentation (TDA), which leverages classical data augmentation techniques to tackle the pressing issue of bias in data and models. Unlike the laborious task of removing biases, our method proposes to insert biases instead, resulting in improved performance. (...)
Introduction
Data augmentation can be simply described as any method that makes our dataset larger by making modified copies of the existing dataset. To create more images for example, we could zoom in and save the result, we could change the brightness of the image or rotate it. To get a bigger sound dataset we could try to raise or lower the pitch of the audio sample or slow down/speed up. Example data augmentation techniques are presented in the diagram below.

DATA AUGMENTATION
-
Images augmentation
- Affine transformations
- Rotation
- Scaling
- Random cropping
- Reflection
- Elastic transformations
- Contrast shift
- Brightness shift
- Blurring
- Channel shuffle
- Advanced transformations
- Random erasing
- Adding rain effects, sun flare...
- Image blending
- Neural-based transformations
- Adversarial noise
- Neural Style Transfer
- Generative Adversarial Networks
- Affine transformations
-
Audio augmentation
- Noise injection
- Time shift
- Time stretching
- Random cropping
- Pitch scaling
- Dynamic range compression
- Simple gain
- Equalization
- Voice conversion (Speech)
-
Natural Language Processing augmentation
- Thesaurus
- Text Generation
- Back Translation
- Word Embeddings
- Contextualized Word Embeddings
- Paraphrasing
- Text perturbation
-
Time Series Data Augmentation
- Basic approaches
- Warping
- Jittering
- Perturbing
- Advanced approaches
- Embedding space
- GAN/Adversarial
- RL/Meta-Learning
- Basic approaches
-
Graph Augmentation
- Node/edge dropping
- Node/edge addition (graph modification)
- Edge perturbation
-
Gene expression Augmentation
- Data generation with GANs
- Mixing observations
- Random variable insertion
-
Automatic Augmentation (AutoAugment)
- Other
- Keypoints/landmarks Augmentation - usually done with image augmentation (rotation, reflection) or graph augmentation methods (node/edge dropping)
- Spectrograms/Melspectrograms - usually done with time series data augmentation (jittering, perturbing, warping) or image augmentation (random erasing)
If you wish to cite us, you can cite the following paper of your choice: Style transfer-based image synthesis as an efficient regularization technique in deep learning or Data augmentation for improving deep learning in image classification problem.
Repositories
Computer vision
- albumentations  is a Python library with a set of useful, large, and diverse data augmentation methods. It offers over 30 different types of augmentations, easy and ready to use. Moreover, as the authors prove, the library is faster than other libraries on most of the transformations.
is a Python library with a set of useful, large, and diverse data augmentation methods. It offers over 30 different types of augmentations, easy and ready to use. Moreover, as the authors prove, the library is faster than other libraries on most of the transformations.
Example Jupyter notebooks:
- All in one showcase notebook
- Classification,
- Object detection, image segmentation and keypoints
- Others - Weather transforms , Serialization, Replay/Deterministic mode, Non-8-bit images
Example transformations:
- imgaug  - is another very useful and widely used Python library. As the author describes: it helps you with augmenting images for your machine learning projects. It converts a set of input images into a new, much larger set of slightly altered images. It offers many augmentation techniques such as affine transformations, perspective transformations, contrast changes, gaussian noise, dropout of regions, hue/saturation changes, cropping/padding, and blurring.
- is another very useful and widely used Python library. As the author describes: it helps you with augmenting images for your machine learning projects. It converts a set of input images into a new, much larger set of slightly altered images. It offers many augmentation techniques such as affine transformations, perspective transformations, contrast changes, gaussian noise, dropout of regions, hue/saturation changes, cropping/padding, and blurring.
Example Jupyter notebooks:
- Load and Augment an Image
- Multicore Augmentation
- Augment and work with: Keypoints/Landmarks, Bounding Boxes, Polygons, Line Strings, Heatmaps, Segmentation Maps
Example transformations:

- Kornia  - is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.
- is a differentiable computer vision library for PyTorch. It consists of a set of routines and differentiable modules to solve generic computer vision problems. At its core, the package uses PyTorch as its main backend both for efficiency and to take advantage of the reverse-mode auto-differentiation to define and compute the gradient of complex functions.
At a granular level, Kornia is a library that consists of the following components:
| Component | Description |
|---|---|
| kornia | a Differentiable Computer Vision library, with strong GPU support |
| kornia.augmentation | a module to perform data augmentation in the GPU |
| kornia.color | a set of routines to perform color space conversions |
| kornia.contrib | a compilation of user contributed and experimental operators |
| kornia.enhance | a module to perform normalization and intensity transformation |
| kornia.feature | a module to perform feature detection |
| kornia.filters | a module to perform image filtering and edge detection |
| kornia.geometry | a geometric computer vision library to perform image transformations, 3D linear algebra and conversions using different camera models |
| kornia.losses | a stack of loss functions to solve different vision tasks |
| kornia.morphology | a module to perform morphological operations |
| kornia.utils | image to tensor utilities and metrics for vision problems |

- UDA  - a simple data augmentation tool for image files, intended for use with machine learning data sets. The tool scans a directory containing image files, and generates new images by performing a specified set of augmentation operations on each file that it finds. This process multiplies the number of training examples that can be used when developing a neural network, and should significantly improve the resulting network's performance, particularly when the number of training examples is relatively small.
- a simple data augmentation tool for image files, intended for use with machine learning data sets. The tool scans a directory containing image files, and generates new images by performing a specified set of augmentation operations on each file that it finds. This process multiplies the number of training examples that can be used when developing a neural network, and should significantly improve the resulting network's performance, particularly when the number of training examples is relatively small.
The details are available here: UNSUPERVISED DATA AUGMENTATION FOR CONSISTENCY TRAINING
- Data augmentation for object detection  - Repository contains a code for the paper space tutorial series on adapting data augmentation methods for object detection tasks. They support a lot of data augmentations, like Horizontal Flipping, Scaling, Translation, Rotation, Shearing, Resizing.
- Repository contains a code for the paper space tutorial series on adapting data augmentation methods for object detection tasks. They support a lot of data augmentations, like Horizontal Flipping, Scaling, Translation, Rotation, Shearing, Resizing.

- FMix - Understanding and Enhancing Mixed Sample Data Augmentation  This repository contains the official implementation of the paper 'Understanding and Enhancing Mixed Sample Data Augmentation'
This repository contains the official implementation of the paper 'Understanding and Enhancing Mixed Sample Data Augmentation'

- Super-AND  - This repository is the Pytorch implementation of "A Comprehensive Approach to Unsupervised Embedding Learning based on AND Algorithm.
- This repository is the Pytorch implementation of "A Comprehensive Approach to Unsupervised Embedding Learning based on AND Algorithm.

- vidaug  - This Python library helps you with augmenting videos for your deep learning architectures. It converts input videos into a new, much larger set of slightly altered videos.
- This Python library helps you with augmenting videos for your deep learning architectures. It converts input videos into a new, much larger set of slightly altered videos.

- Image augmentor  - This is a simple Python data augmentation tool for image files, intended for use with machine learning data sets. The tool scans a directory containing image files, and generates new images by performing a specified set of augmentation operations on each file that it finds. This process multiplies the number of training examples that can be used when developing a neural network, and should significantly improve the resulting network's performance, particularly when the number of training examples is relatively small.
- This is a simple Python data augmentation tool for image files, intended for use with machine learning data sets. The tool scans a directory containing image files, and generates new images by performing a specified set of augmentation operations on each file that it finds. This process multiplies the number of training examples that can be used when developing a neural network, and should significantly improve the resulting network's performance, particularly when the number of training examples is relatively small.
- torchsample  - this python package provides High-Level Training, Data Augmentation, and Utilities for Pytorch. This toolbox provides data augmentation methods, regularizers and other utility functions. These transforms work directly on torch tensors:
- this python package provides High-Level Training, Data Augmentation, and Utilities for Pytorch. This toolbox provides data augmentation methods, regularizers and other utility functions. These transforms work directly on torch tensors:
- Compose()
- AddChannel()
- SwapDims()
- RangeNormalize()
- StdNormalize()
- Slice2D()
- RandomCrop()
- SpecialCrop()
- Pad()
- RandomFlip()
- Random erasing  - The code is based on the paper: https://arxiv.org/abs/1708.04896. The Abstract:
- The code is based on the paper: https://arxiv.org/abs/1708.04896. The Abstract:
In this paper, we introduce Random Erasing, a new data augmentation method for training the convolutional neural network (CNN). In training, Random Erasing randomly selects a rectangle region in an image and erases its pixels with random values. In this process, training images with various levels of occlusion are generated, which reduces the risk of over-fitting and makes the model robust to occlusion. Random Erasing is parameter learning free, easy to implement, and can be integrated with most of the CNN-based recognition models. Albeit simple, Random Erasing is complementary to commonly used data augmentation techniques such as random cropping and flipping, and yields consistent improvement over strong baselines in image classification, object detection and person re-identification. Code is available at: this https URL.

- data augmentation in C++ -  Simple image augmnetation program transform input images with rotation, slide, blur, and noise to create training data of image recognition.
Simple image augmnetation program transform input images with rotation, slide, blur, and noise to create training data of image recognition.
- Data augmentation with GANs  - This repository contains files with Generative Adversarial Network, which can be used to successfully augment the dataset. This is an implementation of DAGAN as described in https://arxiv.org/abs/1711.04340. The implementation provides data loaders, model builders, model trainers, and synthetic data generators for the Omniglot and VGG-Face datasets.
- This repository contains files with Generative Adversarial Network, which can be used to successfully augment the dataset. This is an implementation of DAGAN as described in https://arxiv.org/abs/1711.04340. The implementation provides data loaders, model builders, model trainers, and synthetic data generators for the Omniglot and VGG-Face datasets.
- Joint Discriminative and Generative Learning  - This repo is for Joint Discriminative and Generative Learning for Person Re-identification (CVPR2019 Oral). The author proposes an end-to-end training network that simultaneously generates more training samples and conducts representation learning. Given N real samples, the network could generate O(NxN) high-fidelity samples.
- This repo is for Joint Discriminative and Generative Learning for Person Re-identification (CVPR2019 Oral). The author proposes an end-to-end training network that simultaneously generates more training samples and conducts representation learning. Given N real samples, the network could generate O(NxN) high-fidelity samples.
 [Project] [Paper] [YouTube] [Bilibili] [Poster]
[Supp]
[Project] [Paper] [YouTube] [Bilibili] [Poster]
[Supp]
- White-Balance Emulator for Color Augmentation  - Our augmentation method can accurately emulate realistic color constancy degradation. Existing color augmentation methods often generate unrealistic colors which rarely happen in reality (e.g., green skin or purple grass). More importantly, the visual appearance of existing color augmentation techniques does not well represent the color casts produced by incorrect WB applied onboard cameras, as shown below. [python] [matlab]
- Our augmentation method can accurately emulate realistic color constancy degradation. Existing color augmentation methods often generate unrealistic colors which rarely happen in reality (e.g., green skin or purple grass). More importantly, the visual appearance of existing color augmentation techniques does not well represent the color casts produced by incorrect WB applied onboard cameras, as shown below. [python] [matlab]

- DocCreator (OCR)  - is an open source, cross-platform software allowing to generate synthetic document images and the accompanying ground truth. Various degradation models can be applied on original document images to create virtually unlimited amounts of different images.
- is an open source, cross-platform software allowing to generate synthetic document images and the accompanying ground truth. Various degradation models can be applied on original document images to create virtually unlimited amounts of different images.
A multi-platform and open-source software able to create synthetic image documents with ground truth.

- OnlineAugment  - implementation in PyTorch
- implementation in PyTorch
- More automatic than AutoAugment and related
- Towards fully automatic (STN and VAE, No need to specify the image primitives).
- Broad domains (natural, medical images, etc).
- Diverse tasks (classification, segmentation, etc).
- Easy to use
- One-stage training (user-friendly).
- Simple code (single GPU training, no need for parallel optimization).
- Orthogonal to AutoAugment and related
- Online v.s. Offline (Joint optimization, no expensive offline policy searching).
- State-of-the-art performance (in combination with AutoAugment).

- Augraphy (OCR)  - is a Python library that creates multiple copies of original documents through an augmentation pipeline that randomly distorts each copy -- degrading the clean version into dirty and realistic copies rendered through synthetic paper printing, faxing, scanning and copy machine processes.
- is a Python library that creates multiple copies of original documents through an augmentation pipeline that randomly distorts each copy -- degrading the clean version into dirty and realistic copies rendered through synthetic paper printing, faxing, scanning and copy machine processes.

- Data Augmentation optimized for GAN (DAG)  - implementation in PyTorch and Tensorflow
- implementation in PyTorch and Tensorflow
DAG-GAN provides simple implementations of the DAG modules in both PyTorch and TensorFlow, which can be easily integrated into any GAN models to improve the performance, especially in the case of limited data. We only illustrate some augmentation techniques (rotation, cropping, flipping, ...) as discussed in our paper, but our DAG is not limited to these augmentations. The more augmentation to be used, the better improvements DAG enhances the GAN models. It is also easy to design your augmentations within the modules. However, there may be a trade-off between the numbers of many augmentations to be used in DAG and the computational cost.
- Unsupervised Data Augmentation (google-research/uda) - implementation in Tensorflow.
Unsupervised Data Augmentation or UDA is a semi-supervised learning method which achieves state-of-the-art results on a wide variety of language and vision tasks. With only 20 labeled examples, UDA outperforms the previous state-of-the-art on IMDb trained on 25,000 labeled examples.
They are releasing the following:
- Code for text classifications based on BERT.
- Code for image classifications on CIFAR-10 and SVHN.
- Code and checkpoints for our back translation augmentation system.
- AugLy  - AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations.
- AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations.
Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
AugLy is a great library to utilize for augmenting your data in model training, or to evaluate the robustness gaps of your model! We designed AugLy to include many specific data augmentations that users perform in real life on internet platforms like Facebook's -- for example making an image into a meme, overlaying text/emojis on images/videos, reposting a screenshot from social media. While AugLy contains more generic data augmentations as well, it will be particularly useful to you if you're working on a problem like copy detection, hate speech detection, or copyright infringement where these "internet user" types of data augmentations are prevalent.
- Data-Efficient GANs with DiffAugment  - contains implementation of Differentiable Augmentation (DiffAugment) in both PyTorch and TensorFlow.
- contains implementation of Differentiable Augmentation (DiffAugment) in both PyTorch and TensorFlow.
It can be used to significantly improve the data efficiency for GAN training. We have provided DiffAugment-stylegan2 (TensorFlow) and DiffAugment-stylegan2-pytorch, DiffAugment-biggan-cifar (PyTorch) for GPU training, and DiffAugment-biggan-imagenet (TensorFlow) for TPU training.
project | paper | datasets | video | slides

Natural Language Processing
- nlpaug  - This Python library helps you with augmenting nlp for your machine learning projects. Visit this introduction to understand about Data Augmentation in NLP.
- This Python library helps you with augmenting nlp for your machine learning projects. Visit this introduction to understand about Data Augmentation in NLP. Augmenter is the basic element of augmentation while Flow is a pipeline to orchestra multi augmenter together.
Features:
- Generate synthetic data for improving model performance without manual effort
- Simple, easy-to-use and lightweight library. Augment data in 3 lines of code
- Plug and play to any neural network frameworks (e.g. PyTorch, TensorFlow)
- Support textual and audio input


- AugLy - AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations.
Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
AugLy is a great library to utilize for augmenting your data in model training, or to evaluate the robustness gaps of your model! We designed AugLy to include many specific data augmentations that users perform in real life on internet platforms like Facebook's -- for example making an image into a meme, overlaying text/emojis on images/videos, reposting a screenshot from social media. While AugLy contains more generic data augmentations as well, it will be particularly useful to you if you're working on a problem like copy detection, hate speech detection, or copyright infringement where these "internet user" types of data augmentations are prevalent.
- TextAttack 🐙  - TextAttack is a Python framework for adversarial attacks, data augmentation, and model training in NLP.
- TextAttack is a Python framework for adversarial attacks, data augmentation, and model training in NLP.
Many of the components of TextAttack are useful for data augmentation. The textattack.Augmenter class
uses a transformation and a list of constraints to augment data. We also offer five built-in recipes
for data augmentation source:QData/TextAttack:
textattack.WordNetAugmenteraugments text by replacing words with WordNet synonymstextattack.EmbeddingAugmenteraugments text by replacing words with neighbors in the counter-fitted embedding space, with a constraint to ensure their cosine similarity is at least 0.8textattack.CharSwapAugmenteraugments text by substituting, deleting, inserting, and swapping adjacent characterstextattack.EasyDataAugmenteraugments text with a combination of word insertions, substitutions and deletions.textattack.CheckListAugmenteraugments text by contraction/extension and by substituting names, locations, numbers.textattack.CLAREAugmenteraugments text by replacing, inserting, and merging with a pre-trained masked language model.
- EDA NLP  - EDA is an easy data augmentation techniques for boosting performance on text classification tasks. These are a generalized set of data augmentation techniques that are easy to implement and have shown improvements on five NLP classification tasks, with substantial improvements on datasets of size
- EDA is an easy data augmentation techniques for boosting performance on text classification tasks. These are a generalized set of data augmentation techniques that are easy to implement and have shown improvements on five NLP classification tasks, with substantial improvements on datasets of size N < 500. While other techniques require you to train a language model on an external dataset just to get a small boost, we found that simple text editing operations using EDA result in good performance gains. Given a sentence in the training set, we perform the following operations:
- Synonym Replacement (SR): Randomly choose n words from the sentence that are not stop words. Replace each of these words with one of its synonyms chosen at random.
- Random Insertion (RI): Find a random synonym of a random word in the sentence that is not a stop word. Insert that synonym into a random position in the sentence. Do this n times.
- Random Swap (RS): Randomly choose two words in the sentence and swap their positions. Do this n times.
- Random Deletion (RD): For each word in the sentence, randomly remove it with probability p.
- NL-Augmenter 🦎 → 🐍  - The NL-Augmenter is a collaborative effort intended to add transformations of datasets dealing with natural language. Transformations augment text datasets in diverse ways, including: randomizing names and numbers, changing style/syntax, paraphrasing, KB-based paraphrasing ... and whatever creative augmentation you contribute. We invite submissions of transformations to this framework by way of GitHub pull requests, through August 31, 2021. All submitters of accepted transformations (and filters) will be included as co-authors on a paper announcing this framework.
- The NL-Augmenter is a collaborative effort intended to add transformations of datasets dealing with natural language. Transformations augment text datasets in diverse ways, including: randomizing names and numbers, changing style/syntax, paraphrasing, KB-based paraphrasing ... and whatever creative augmentation you contribute. We invite submissions of transformations to this framework by way of GitHub pull requests, through August 31, 2021. All submitters of accepted transformations (and filters) will be included as co-authors on a paper announcing this framework.
- Contextual data augmentation  - Contextual augmentation is a domain-independent data augmentation for text classification tasks. Texts in the supervised dataset are augmented by replacing words with other words which are predicted by a label-conditioned bi-directional language model.
- Contextual augmentation is a domain-independent data augmentation for text classification tasks. Texts in the supervised dataset are augmented by replacing words with other words which are predicted by a label-conditioned bi-directional language model.
This repository contains a collection of scripts for an experiment of Contextual Augmentation.

- Wiki Edits  - A collection of scripts for automatic extraction of edited sentences from text edition histories, such as Wikipedia revisions. It was used to create the WikEd Error Corpus --- a corpus of corrective Wikipedia edits. The corpus has been prepared for two languages: Polish and English. Can be used as a dictionary-based augmentation to insert user-induced errors.
- A collection of scripts for automatic extraction of edited sentences from text edition histories, such as Wikipedia revisions. It was used to create the WikEd Error Corpus --- a corpus of corrective Wikipedia edits. The corpus has been prepared for two languages: Polish and English. Can be used as a dictionary-based augmentation to insert user-induced errors.
- Text AutoAugment (TAA)  - Text AutoAugment is a learnable and compositional framework for data augmentation in NLP. The proposed algorithm automatically searches for the optimal compositional policy, which improves the diversity and quality of augmented samples.
- Text AutoAugment is a learnable and compositional framework for data augmentation in NLP. The proposed algorithm automatically searches for the optimal compositional policy, which improves the diversity and quality of augmented samples.
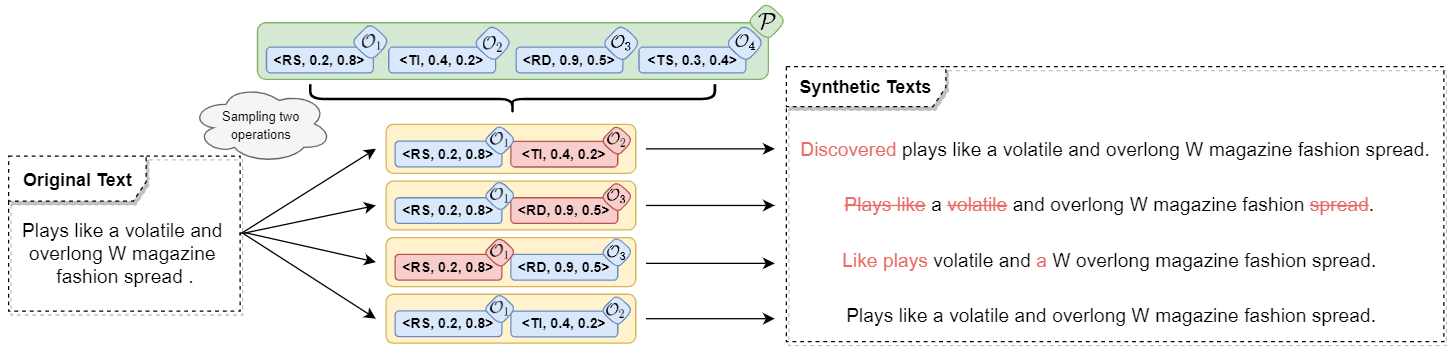
- Unsupervised Data Augmentation (google-research/uda) - implementation in Tensorflow.
Unsupervised Data Augmentation or UDA is a semi-supervised learning method that achieves state-of-the-art results on a wide variety of language and vision tasks. With only 20 labeled examples, UDA outperforms the previous state-of-the-art on IMDb trained on 25,000 labeled examples.
They are releasing the following:
- Code for text classifications based on BERT.
- Code for image classifications on CIFAR-10 and SVHN.
- Code and checkpoints for our back translation augmentation system.
Audio
- SpecAugment with Pytorch  - (https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html) is a state of the art data augmentation approach for speech recognition. It supports augmentations such as time wrap, time mask, frequency mask or all above combined.
- (https://ai.googleblog.com/2019/04/specaugment-new-data-augmentation.html) is a state of the art data augmentation approach for speech recognition. It supports augmentations such as time wrap, time mask, frequency mask or all above combined.


- Audiomentations  - A Python library for audio data augmentation. Inspired by albumentations. Useful for machine learning. It allows to use effects such as: Compose, AddGaussianNoise, TimeStretch, PitchShift and Shift.
- A Python library for audio data augmentation. Inspired by albumentations. Useful for machine learning. It allows to use effects such as: Compose, AddGaussianNoise, TimeStretch, PitchShift and Shift.
- MUDA  - A library for Musical Data Augmentation. Muda package implements annotation-aware musical data augmentation, as described in the muda paper.
- A library for Musical Data Augmentation. Muda package implements annotation-aware musical data augmentation, as described in the muda paper.
The goal of this package is to make it easy for practitioners to consistently apply perturbations to annotated music data for the purpose of fitting statistical models.
- tsaug  -
-
is a Python package for time series augmentation. It offers a set of augmentation methods for time series, as well as a simple API to connect multiple augmenters into a pipeline. Can be used for audio augmentation.
- wav-augment  - performs data augmentation on audio data.
- performs data augmentation on audio data.
The audio data is represented as pytorch tensors. It is particularly useful for speech data. Among others, it implements the augmentations that we found to be most useful for self-supervised learning (Data Augmenting Contrastive Learning of Speech Representations in the Time Domain, E. Kharitonov, M. Rivière, G. Synnaeve, L. Wolf, P.-E. Mazaré, M. Douze, E. Dupoux. [arxiv]):
- Pitch randomization,
- Reverberation,
- Additive noise,
- Time dropout (temporal masking),
- Band reject,
- Clipping
- AugLy - AugLy is a data augmentations library that currently supports four modalities (audio, image, text & video) and over 100 augmentations.
Each modality’s augmentations are contained within its own sub-library. These sub-libraries include both function-based and class-based transforms, composition operators, and have the option to provide metadata about the transform applied, including its intensity.
AugLy is a great library to utilize for augmenting your data in model training, or to evaluate the robustness gaps of your model! We designed AugLy to include many specific data augmentations that users perform in real life on internet platforms like Facebook's -- for example making an image into a meme, overlaying text/emojis on images/videos, reposting a screenshot from social media. While AugLy contains more generic data augmentations as well, it will be particularly useful to you if you're working on a problem like copy detection, hate speech detection, or copyright infringement where these "internet user" types of data augmentations are prevalent.
Time series
- tsaug 
is a Python package for time series augmentation. It offers a set of augmentation methods for time series, as well as a simple API to connect multiple augmenters into a pipeline.
Example augmenters:
- random time warping 5 times in parallel,
- random crop subsequences with length 300,
- random quantize to 10-, 20-, or 30- level sets,
- with 80% probability, random drift the signal up to 10% - 50%,
- with 50% probability, reverse the sequence.
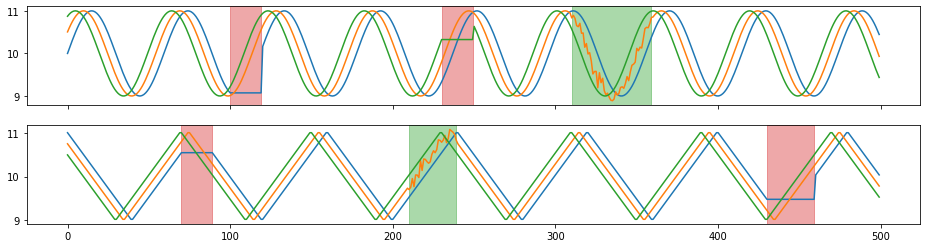
- Data Augmentation For Wearable Sensor Data  - a sample code of data augmentation methods for wearable sensor data (time-series data) based on the paper below:
- a sample code of data augmentation methods for wearable sensor data (time-series data) based on the paper below:
T. T. Um et al., “Data augmentation of wearable sensor data for parkinson’s disease monitoring using convolutional neural networks,” in Proceedings of the 19th ACM International Conference on Multimodal Interaction, ser. ICMI 2017. New York, NY, USA: ACM, 2017, pp. 216–220.

AutoAugment
Automatic Data Augmentation is a family of algorithms that searches for the policy of augmenting the dataset for solving the selected task.
Github repositories:
- Text AutoAugment (TAA)
- Official Fast AutoAugment implementation in PyTorch

- AutoCLINT - Automatic Computationally LIght Network Transfer (A specially designed light version of Fast AutoAugment is implemented to adapt to various tasks under limited resources)

- Population Based Augmentation (PBA)

- AutoAugment: Learning Augmentation Policies from Data (Keras and Tensorflow)

- AutoAugment: Learning Augmentation Policies from Data (PyTorch)

- AutoAugment: Learning Augmentation Policies from Data (PyTorch, another implementation)

Other
Challenges
- AutoDL 2019 (NeurIPS AutoDL challenges - includes AutoAugment) - Machine Learning and in particular Deep Learning has achieved considerable successes in recent years and an ever-growing number of disciplines rely on it. However, this success crucially relies on human intervention in many steps (data pre-processing, feature engineering, model selection, hyper-parameter optimization, etc.). As the complexity of these tasks is often beyond non-experts, the rapid growth of machine learning applications has created a demand for off-the-shelf or reusable methods, which can be used easily and without expert knowledge. The objective of AutoML (Automated Machine Learning) challenges is to provide "universal learning machines" (deep learning or others), which can learn and make predictions without human intervention (blind testing).
Workshops
- Interactive Labeling and Data Augmentation for Vision ICCV 2021 Workshop - The workshop on Interactive Labeling and Data Augmentation for Vision (ILDAV) wishes to address novel ways to solve computer vision problems where large quantities of labeled image data may not be readily available. It is important that datasets of sufficient size can be quickly and cheaply acquired and labeled. More specifically, we are interested in solutions to this problem that make use of (i) few-click and interactive data annotation, where machine learning is used to enhance human annotation skill, (ii) synthetic data generation, where one uses artificially generated data to augment real datasets, and (iii) weak supervision, where auxiliary or weak signals are used instead of (or to complement) manual labels.
More broadly, we aim at fostering a collaboration between academia and industry in terms of leveraging machine learning research and human-in-the-loop, interactive labeling to quickly build datasets that will enable the use of powerful deep models in all problems of computer vision.
The workshop topics include (but are not limited to):
- Interactive and Few-click annotation
- Data augmentation
- Synthetic data for training models
- Weak supervision
- Human-in-the-loop learning