Awesome
EDIT (AS OF 4th NOVEMBER 2019):
-
This implementation has multiple errors and as of the date 4th, November 2019 is insufficient to be utilized as a resource to understanding the architecture of Mask R-CNN. It has been pointed out to me through multiple emails and comments on HackerNews that such a faulty implementation is to the detriment of the research endeavors in the deep learning community. It was a project that I had put together quite early in my academic career and I did not realize the scale of my mistake
-
I intend to take care of the issues (the issues filed in this repository are representative) and make this code more "readable" and embellish it with better documentation so that it fulfills the purpose for which it was made. Unfortunately, as of right now, I am busy with my academics and cannot attend to this project. I shall start working on bettering this repository by mid-January to early February 2020. Until then, I have provided links to other implementations of Mask R-CNN that I think could help serve your purpose
-
PR's fixing any one of the issues listed are always welcome and will allow me to get a headstart on this particular task of making this repository more presentable.
Once again I would like to apologize for any inconvenience caused
<a name="someid"></a> LINKS
- https://github.com/facebookresearch/detectron2 (PyTorch implementation)
- https://github.com/matterport/Mask_RCNN (Tensorflow implementation). Much of this repository was built using this repository as a reference
Mask-RCNN
A PyTorch implementation of the architecture of Mask RCNN
Decription of folders
- model.py includes the models of ResNet and FPN which were already implemented by the authors of the papers and reproduced in this implementation
- nms and RoiAlign are taken from Robb Girshick's implementation of faster RCNN
- Focal loss has been added to this implementtaion on lieu of better results as evidenced by the paper on RetinaNets
Mask-RCNN model:
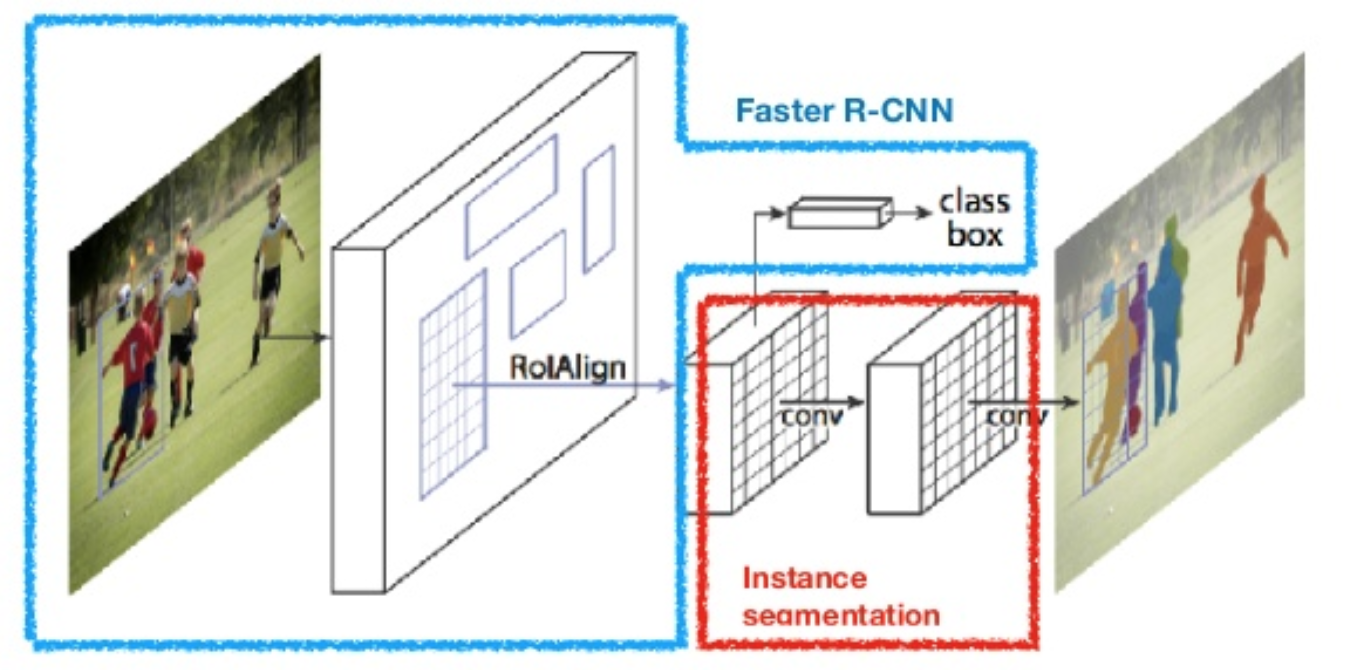
Features:
- The part of the network responsible for bounding box detection derives it's inspiration from the faster RCNN model having a RPN working in tandem with a ConvNet
- The pooling layers present in the ConvNet round down or round up to the nearest integer when the stride is not a divisor of the receptive field, which tends to either lose or assume "information" from the image respectively at the non integral points.
- ROI align was proposed to deal with this, wherein bilinear interpolation is used to detect the values at the non integral values of the pixels
- Using a more complex interpolation scheme( cubic interpolation -> 16 additional features) offers a slightly better result when this model was tested, however not enough to justify the additional complexity
- Cross entropy loss when summed over a huge number of proposals tends to take a huge value for proposals that have a high confidence metric thereby dwarfing the contribution from the proposals of interest. Focal Loss was proposed to do away with this problem
- However Focal loss gives much better results with single stage networks. This is because a two stage network has some discriminative policy to deal with this class imbalance something which the single stage networks don't enjoy.
If you find any issue in this repsoritory, feel free to fork this repository and submit a PR with the necessary changes