Awesome
第四届魔镜杯资金流动性管理 建模分享
0. 其他解决方案链接
1. 项目背景
资金流动性管理迄今仍是金融领域的经典问题。在互联网金融信贷业务中,单个资产标的金额小且复杂多样,对于拥有大量出借资金的金融机构或散户而言,资金管理压力巨大,精准地预测出借资金的流动情况变得尤为重要。本次比赛以互联网金融信贷业务为背景,以《现金流预测》为题,希望选手能够利用我们提供的数据,精准地预测资产组合在未来一段时间内每日的回款金额。 本赛题涵盖了信贷违约预测、现金流预测等金融领域常见问题,同时又是复杂的时序问题和多目标预测问题。希望参赛者利用聪明才智把互联网金融的数据优势转化为行业解决方案。
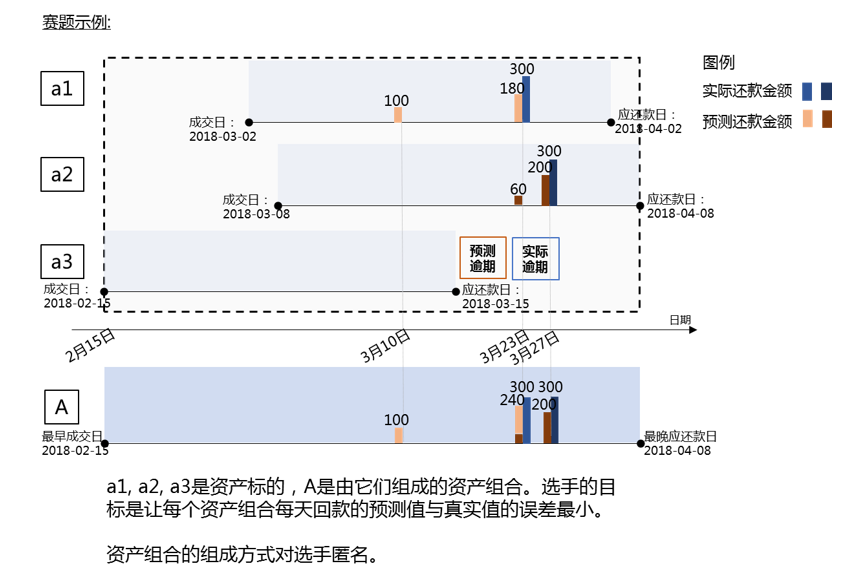
2. 数据介绍
本赛题对回款预测问题进行了简化,选手需要分别预测每个资产标的第一期从成交日期至第一期应还款日期每日的还款金额,并最终在整体上以资产组合每日还款的误差作为评价指标。
我们提供了2018年1月1日至2018年12月31日的标的第一期的还款数据作为训练集,需要选手预测2019年2月1日至2019年3月31日成交标的第一期的还款情况。同时还提供了相关的标的属性信息,借款用户基础信息、画像标签和行为日志等数据供选手使用。
注:为了保护用户隐私和比赛的公正性,数据经过脱敏处理,同时进行了必要过滤和有偏采样。
数据集描述
1. 样本集(train.csv和test.csv)
本赛题提供的样本集包含训练集(train.csv)和测试集(test.csv),它们的数据表结构基本一致,但测试集中不含实际还款信息。整个样本集共有约113万个标的和90万位借款用户,部分借款用户可能有多个标的记录,但在测试集时间范围内每位用户只有一条记录。
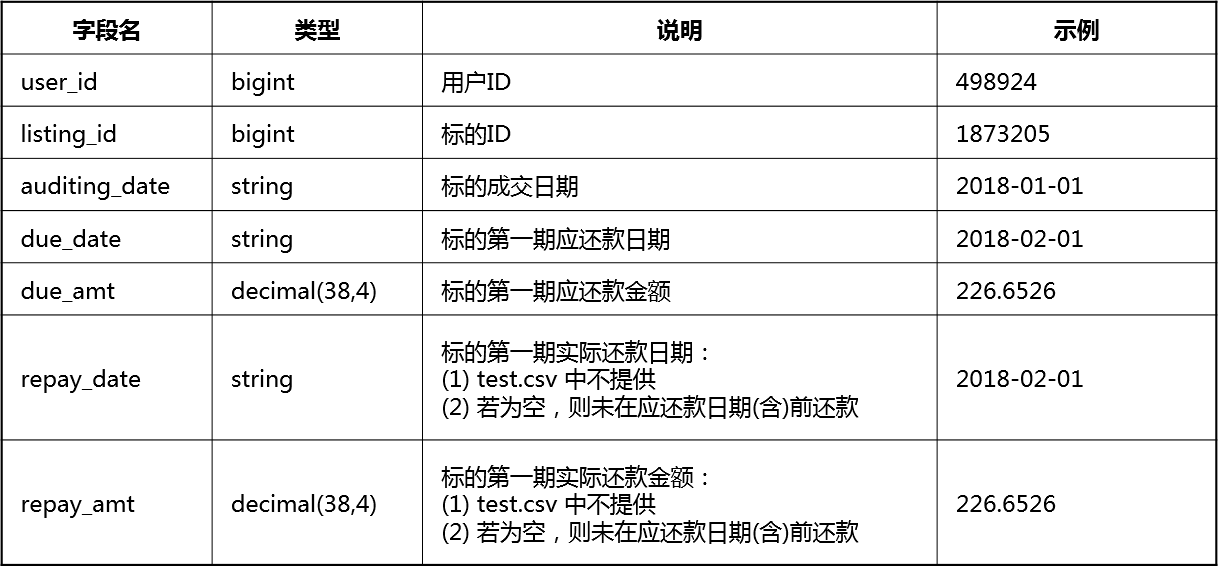
注:上述的数据都经过脱敏处理,脱敏后的数据分布和数值大小关系与脱敏前基本一致。
2. 标的属性表(listing_info.csv)
标的属性表包含了本赛题涉及的所有标的,包括:(1) 样本集中所有标的;(2) 样本集中所有借款用户在过去一段时间内成交和还款的标的。标的属性信息在成交时确定,后续不再变更。

注:上述的数据都经过脱敏处理,脱敏后的数据分布和数值大小关系与脱敏前基本一致。
3. 借款用户基础信息表(user_info.csv)
借款用户基础信息表包含了本赛题涉及的所有用户,用户信息可能发生变更,表中同一用户可能存在多条数据。
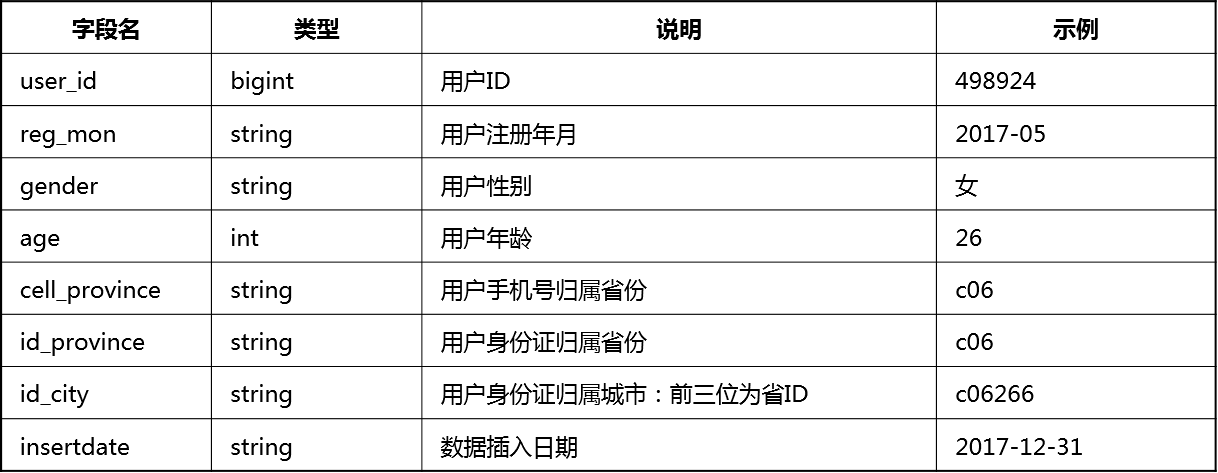
注:上述的数据都经过脱敏处理,地址类字段为编码数据,城市字段前三位为所属省份ID。
4. 用户画像标签列表(user_taglist.csv)
用户画像标签列表提供了用户的标签信息,用户标签可能发生变更,表中同一用户可能存在多条数据;若在表中无法查到用户标签信息,则表示该用户标签信息未知。

注:上述的数据都经过脱敏处理。
5. 借款用户操作行为日志表(user_behavior_logs.csv)
借款用户操作行为日志表提供了每位用户在过去一段时间内的操作行为日志数据,行为发生时间精确到秒级,相同用户的相同行为在同一秒内可能出现多条数据。

注:上述的数据都经过脱敏处理。
6. 用户还款日志表(user_repay_logs.csv)
借款用户还款日志表提供了每位用户在过去一段时期内的还款日志数据。
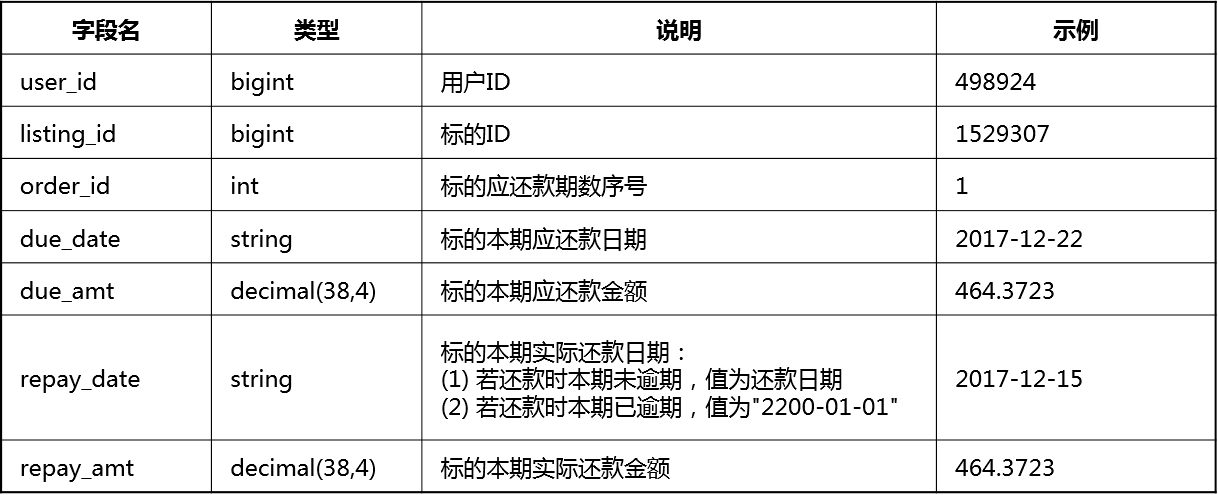
注1:上述的数据都经过脱敏处理,脱敏后的数据分布和数值大小关系与脱敏前基本一致;
注2:脱敏后,若还款时本期已逾期,repay_date(实际还款日期)字段默认值为“2200-01-01”,脱敏前实际还款日期一定早于用户最近一个新成交标的成交日期。
3. 简单数据分析
3.1 训练用户的每日还款量

不同时间的还款量存在差异,月初是还款高峰。具体可以做点分析。
3.2 用户的还款日志中的还款量统计

感觉比训练集中的数据来说,分布更加平滑,更加符合实际情况。
3.3 用户提前还款分布情况


该部分历史行为是强特。
4. 方案整理
规则学习
在做数据科学项目过程中,可以从规则学习起手。拿什么是规则,西瓜书中有规则学习的定义:规则学习是“符号主义学习”(symbolism learning)的主要代表,是最早开始研究的机器学习技术之一。机器学习中的“规则”(rule)通常是指语义明确、能描述数据分布所隐含的客观规律或领域概念、可写成“若…,则…”形式的逻辑规则。“规则学习”(rule learning)是从训练数据中学习出一组能用于对未见示例进行判别的规则。 为什么从规则起手比较好,我认为有两个原因:
- 找规则过程中往往是你熟悉数据,理解业务的过程,这过程是任何数据工程项目中必不可好并且极为关键的一部分。
- 规则通常意味着强特,意味着显著表现。一般规则都可以无缝切入到模型。 面对这个场景,我先提出的两个简单的规则:
- 假设用户都在到期日(due_date)准时还款。
- 为了最后的得分表现,我们选择根据还款距离due_date的日期分布情况,加权分配还款金额。 其他还有部分规则,可以进行探讨,比如逾期率经过成熟的业务控制在未来会降低,比如用户的还款行为各异,比如找到发工资集中的日子等。
回归算法
看一下该任务的评价指标:该任务需要预测测试集中所有标的在成交日至第1期应还款日内日的回款金额,预测金额数据应为非负数且保留四位小数。本次比赛主要期望选手对未知资产组合每日总回款金额数据预测得越准越好,因此,不会给出标的归属资产组合序号,并选用RMSE作为评估指标,计算公式如下:

很明显这是一个回归问题,所以我们可以作为回归问题来求解。样本设置为每一个标的在未来每个存在还款的日子里的还款金额。 在此基础上我训练了模型,效果一般。后来分析得出三个关键问题,并且没有很好的解答。
- 每一个标的会产生30个左右的样本,导致训练集扩大了30倍,这对训练的性能带来的挑战。
- 每一个标的生成的这30个样本强相关,并且这种相关性如何用特征区分开来 是一个挑战。
- 该问题跟问题2本质是一样的,就是该回归问题有约束,每个标的的回归值得和是一个定值,并且训练集中得目标值分布畸形,存在绝大多数的0. 因为是多任务学习的本质导致了这是一个畸形的回归问题,所以用传统的回归方法求解该问题,在实践上无法取得良好的表现,该问题这里也做一个记录,未来说不定会有新的IDEA产生。
多分类算法
最终选择了多分类算法作为求解,通过due_amt*该类概率获得最终的回归值,也就是预测结果。这样的话,没有给标的就是一个样本。类别label的定义,则是还款日到到期日(due_date)的距离.其中逾期设置为第32类。这里需要注意I的是可以设置所有的当天还款为31类。克服每个月的天数不一样带来的影响。
该方案也有不足:
- 未来每个还款日的特征无法加进去(或许有加进去的办法,但是我没有想到)。当然,该问题可以通过后续的规则进行解决。
- 最终计算的到的结果是概率,并且评价指标也是multi_logloss。这和最终结果的RMSE评价指标当中会有所差异。具体的差异刻画没有找到。
因为该方案线上表现最好,所以后续的工作在该方案上展开。
4. 特征工程
确定了目标方案为多分类,定义好了训练样本和测试样本后,开始进行特征工程。
基础特征
- 用户基础特征:性别,年龄,注册时间,地址信息
- 标的基础特征:期数,利率,借款本金,标的起始时间特征
用户还款特征
- 用户在历史n天之内的到期标的次数和金额(n=15,31,90,180)
- 用户在历史n天之内的实际还款的标的数量和金额(n=15,31,90,180)
- 用户在历史n天之内的还款时间统计特征(历史label的统计,包括mean,median,std,max,min)
- 用户在历史n天之内非首期标的提前还款的标的数量和金额(n=15,31,90,180)
- 用户在历史n天之内逾期的标的次数和金额(n=15,31,90,180)
- 用户最近一次还款时间到现在的距离,用户最早一次还款时间到现在的距离
- 用户最近一次借款时间到现在的距离,用户最早一次借款时间到现在的距离
- 用户的历史还款频率 (通过还款时间间隔的统计特征来刻画)
- 用户的历史借款频率 (通过标的借款时间间隔的统计特征来刻画)
- 用户尚未还清的标的中最近需要还的时间到现在的距离。
- 用户未来n天需要还款的标的数量和金额(n=30,60,90)
- 用户历史上还款行为在星期曜日上的分布比例
- 用户历史上还款行为在月初,月中,月末的分布比例
这部分是该项目最主要的特征,特征方面记录两点:
- 这里学到了通过时间窗口特征采用先join再filter最后groupby的顺序进行操作,能够快速获得,但是比较耗内存
- 各种比例特征最好进行平滑操作。
用户历史行为特征
- 用户行为(1,2,3 脱敏)在n个月(n=1,3,6)内的行为次数
- 用户历史行为在24个小时内的分布比例
- 用户历史行为在四个时间段内的分布比例(0-6,6-12,12-18,16-24)
- 用户历史上各行为(1,2,3)最近一次到当前的时间间隔
- 用户历史上各行为(1,2,3)的行为频率(通过行为顺序的时间间隔的统计特征表示)
用户标签特征
这里的用户标签是脱敏的,离散的并且是不等长的。通过Tfidf+TruncatedSVD的方式,抽象为文本主题模型,向量化到10维作为特征。
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(user_tag.taglist.values)
svd_enc = TruncatedSVD(n_components=10, n_iter=20, random_state=2019)
mode_svd = svd_enc.fit_transform(X)
mode_svd = pd.DataFrame(mode_svd)
mode_svd.columns = ['taglist_svd0','taglist_svd1','taglist_svd2','taglist_svd3','taglist_svd4','taglist_svd5','taglist_svd6','taglist_svd7','taglist_svd8','taglist_svd9']
user_tag = pd.concat([user_tag,mode_svd],axis=1)
最近了解了Graph Embedding的一些技术,DeepWalk等,但是没有整理好轮子(对的,是整理不是造),之后计划加入到自己的工具栈中)个人感觉,GraphEmbedding在这里向量化标签应该会取得更好的效果,但是本项目中缺乏业务解释,从实验中发现该特征重要性并不高。
贷款产品历史表现特征
项目中并没有明确指定贷款产品,但是对标的的属性给出了 利率,期限和本金三个特征。 假设这三个特征能够代表一个具体的产品。根据产品粒度做了历史的滑窗统计特征。
- 该产品在历史n天之内的到期标的次数(n=15,31,90,180)
- 该产品在历史n天之内的实际还款的标的数量(n=15,31,90,180)
- 该产品在历史n天之内覆盖的用户数和天数(n=15,31,90,180)
- 该产品在历史n天之内逾期的标的数量(n=15,31,90,180)
- 该产品在历史n天之内的还款时间统计特征(历史label的统计,包括mean,median,std,max,min)
用户粒度做的历史行为特征重要显著高于这里假设的产品粒度的历史行为,但是聊胜于无。
衍生特征
- 该产品在历史n天之内的平滑后的逾期率(n=15,31,90,180)
- 该用户在历史n天之内的平滑后的逾期率(n=15,31,90,180)
- 该用户在历史n天之内的平滑后的提前还款概率
- 通过年利率计算出的月利率特征
- 其他一些特征之间的四则运算(往往业务出发,可以探索强特)
5. 模型训练
基础版本
这部分直接上训练代码,其实没啥内容
train_sample = train_data[(train_data.auditing_date<'2018-10-01')]
testt_sample = train_data[train_data.auditing_date>='2018-11-01']
train_datas=lgb.Dataset(data=train_sample[features].values,label=train_sample.backward_days,feature_name=features,weight=train_sample.weights)
testt_datas=lgb.Dataset(data=testt_sample[features].values,label=testt_sample.backward_days,feature_name=features,weight=testt_sample.weights)
params = {
'nthread': 2, # 进程数
'max_depth': 4, # 最大深度
'learning_rate': 0.1, # 学习率
'bagging_fraction': 1, # 采样数
'num_leaves': 11, # 终点节点最小样本占比的和
'feature_fraction': 0.3, # 样本列采样
'objective': 'multiclass',
'lambda_l1': 10, # L1 正则化
'lambda_l2': 1, # L2 正则化
'bagging_seed': 100, # 随机种子,light中默认为100
'verbose': 0,
'num_class': 33,
'min_data_in_leaf':500
}
model1 = lgb.train(params,train_datas,num_boost_round=10000,valid_sets=[testt_datas,train_datas],early_stopping_rounds=20)
LightGBM的权重设置
因为样本的权重不一样,样本比例也不相同。本次学习到可以通过设置样本权重来影响损失函数的操作。 一般机器学习算法面对带权重的训练样本时,处理方式往往是权重乘该样本损失形式: final_loss = ∑w_i * L(x_i, y_i) 其中{(x_i, y_i)} 是样本集,w_i 是 (x_i, y_i) 的weight。也就是说,转化成了对Loss 的加权。 对于决策树,微软的lightGbm的实现也是体现了上述方式。lightGBM支持训练样本带权重,通过分析其源代码,发现是把 weight 乘上了 loss 函数的梯度及hessian(二阶导数)当做新的梯度与hessian。这时,pseudo-reponse就是改写后的了。
迁移学习实践
带有时间的数据分析项目中,因为随着时间变化特征和标签的分布都是随着时间变化而变化的。 可以参考ijcai-2018的迁移学习方案。那个比赛中他用第1到7天的数据,预测第8天上午和下午,两者一起预测。类比到这比赛中,前面n个月预测后面n个月和未来的2个月,然后基于此重新训练模型。至于预测的目标可以是逾期率,最后n天归还概率,提前还款的天数等。也可以理解为模型融合的方案。 这个项目中,该方案线下取得更好成绩,但是线上爆炸,故之后没有采纳。在此做记录。
6. 线下测评
线下单独的RMSE在106左右,但是线上得分为6000+,在线上标的组合没有明确的前提下,线下通过随机采样方式构建结果。再次基础上进行评测。 严格按照线上方式构建线下评测。 使用2018/01/01-2018/09/30的数据作为训练集,2018/11/01-2018/12/31的数据作为线下验证集。发现一共就几十个资产组合,大量的标的组合在一起,现在均分成30类时,成绩接近线上。
线下评测脚本
from sklearn.model_selection import KFold
kf = KFold(n_splits=30, shuffle=True, random_state=1)
idxs = []
for idx in kf.split(result_data):
idxs.append(idx[1])
i = 0
for idx in idxs:
result_data.loc[idx,'listing_group'] = i
i+=1
test_result = pd.merge(test_result[['listing_id','repay_date','repay_amt_predict','repay_amt']], result_data, on='listing_id',how='inner')
def rule(x):
rates = {
0:0.984977,
1:1.000038,
2:1.0185,
3:1.012136,
4:1.019214,
5:0.979497,
6:0.964942
}
return x['repay_amt_predict']*rates[ pd.to_datetime(x['repay_date']).weekday()]
test_result['repay_amt_predict_adjust'] = test_result.apply(lambda x:rule(x),axis=1)
result1 = test_result.groupby(['listing_group','repay_date'])['repay_amt_predict','repay_amt'].sum().reset_index()
result2 = test_result.groupby(['listing_group','repay_date'])['repay_amt_predict_adjust','repay_amt'].sum().reset_index()
from sklearn.metrics import mean_squared_error
print(mean_squared_error(test_result.repay_amt_predict,test_result.repay_amt))
print(math.sqrt(mean_squared_error(result1.repay_amt_predict,result1.repay_amt)))
print(math.sqrt(mean_squared_error(result2.repay_amt_predict_adjust,result2.repay_amt)))
误差结果分析
在2018年07月到12月作为验证集情况下,分析了模型预测结果和真实分布之间的差异。

可以发现因为模型特征没有刻画还款日信息,因为多分类的局限性,所以有些日子预测总体偏大(月末,双休日等),有些日子总体偏小(月初).可以通过后处理进行调整。
7. 建模感想
- 这是一个比较新颖的任务,也相对单一目的的机器学习场景更加复杂,本项目涵盖了信贷违约预测、现金流预测等金融领域常见问题,同时又是复杂的时序问题和多目标预测问题。最终通过多分类解决。还有更多的解题方案可以探讨,比如dnn+lstm
- 在建模过程中,因为数据量的问题,遇到了Pandas处理数据的优化问题。给出引用
- 如果模型优化目标和最终的评测指标有差异,一般需要经过后处理。
- 探索数据还是排在第一。
我们模型的优点:
- 模拟构建出了线下测试集,规则引入简单有效。
- 仅仅使用了训练集数据。特征简单高效(也有详细特征版本)