Awesome
spidy Web Crawler 
Spidy (/spˈɪdi/) is the simple, easy to use command line web crawler.<br>
Given a list of web links, it uses Python requests to query the webpages, and lxml to extract all links from the page.<br>
Pretty simple!
![]()
![]()

![]()
![]()
![]()
 <br>
<br>
![]()
![]()



 <br>
<br>



Created by rivermont (/rɪvɜːrmɒnt/) and FalconWarriorr (/fælcʌnraɪjɔːr/), and developed with help from these awesome people.<br>
Looking for technical documentation? Check out DOCS.md<br>
Looking to contribute to this project? Have a look at CONTRIBUTING.md, then check out the docs.
🎉 New Features!
Multithreading
Crawl all the things! Run separate threads to work on multiple pages at the same time.<br> Such fast. Very wow.
PyPI
Install spidy with one line: pip install spidy-web-crawler!
Automatic Testing with Travis CI
Release v1.4.0 - #31663d3
Contents
- spidy Web Crawler
- New Features!
- Contents
- How it Works
- Why It's Different
- Features
- Tutorial
- How Can I Support This?
- Contributors
- License
How it Works
Spidy has two working lists, TODO and DONE.<br>
'TODO' is the list of URLs it hasn't yet visited.<br>
'DONE' is the list of URLs it has already been to.<br>
The crawler visits each page in TODO, scrapes the DOM of the page for links, and adds those back into TODO.<br>
It can also save each page, because datahoarding 😜.
Why It's Different
What sets spidy apart from other web crawling solutions written in Python?
Most of the other options out there are not web crawlers themselves, simply frameworks and libraries through which one can create and deploy a web spider for example Scrapy and BeautifulSoup. Scrapy is a Web crawling framework, written in Python, specifically created for downloading, cleaning and saving data from the web whereas BeautifulSoup is a parsing library that allows a programmer to get specific elements out of a webpage but BeautifulSoup alone is not enough because you have to actually get the webpage in the first place.
But with Spidy, everything runs right out of the box. Spidy is a Web Crawler which is easy to use and is run from the command line. You have to give it a URL link of the webpage and it starts crawling away! A very simple and effective way of fetching stuff off of the web.
Features
We built a lot of the functionality in spidy by watching the console scroll by and going, "Hey, we should add that!"<br> Here are some features we figure are worth noting.
- Error Handling: We have tried to recognize all of the errors spidy runs into and create custom error messages and logging for each. There is a set cap so that after accumulating too many errors the crawler will stop itself.
- Cross-Platform compatibility: spidy will work on all three major operating systems, Windows, Mac OS/X, and Linux!
- Frequent Timestamp Logging: Spidy logs almost every action it takes to both the console and one of two log files.
- Browser Spoofing: Make requests using User Agents from 4 popular web browsers, use a custom spidy bot one, or create your own!
- Portability: Move spidy's folder and its contents somewhere else and it will run right where it left off. Note: This only works if you run it from source code.
- User-Friendly Logs: Both the console and log file messages are simple and easy to interpret, but packed with information.
- Webpage saving: Spidy downloads each page that it runs into, regardless of file type. The crawler uses the HTTP
Content-Typeheader returned with most files to determine the file type. - File Zipping: When autosaving, spidy can archive the contents of the
saved/directory to a.zipfile, and then clearsaved/.
Tutorial
Using with Docker
Spidy can be easily run in a Docker container.<br>
- First, build the
Dockerfile:docker build -t spidy .- Verify that the Docker image has been created:
docker images
- Verify that the Docker image has been created:
- Then, run it:
docker run --rm -it -v $PWD:/data spidy--rmtells Docker to clean up after itself by removing stopped containers.-ittells Docker to run the container interactively and allocate a pseudo-TTY.-v $PWD:/datatells Docker to mount the current working directory as/datadirectory inside the container. This is needed if you want Spidy's files (e.g.crawler_done.txt,crawler_words.txt,crawler_todo.txt) written back to your host filesystem.
Spidy Docker Demo

Installing from PyPI
Spidy can be found on the Python Package Index as spidy-web-crawler.<br>
You can install it from your package manager of choice and simple run the spidy command.<br>
The working files will be found in your home directory.
Installing from Source Code
Alternatively, you can download the source code and run it.
Python Installation
The way that you will run spidy depends on the way you have Python installed.<br>
Windows and Mac
There are many different versions of Python, and hundreds of different installations for each them.<br> Spidy is developed for Python v3.5.2, but should run without errors in other versions of Python 3.
Anaconda
We recommend the Anaconda distribution.<br>
It comes pre-packaged with lots of goodies, including lxml, which is required for spidy to run and not including in the standard Python package.
Python Base
You can also just install default Python, and install the external libraries separately.<br>
This can be done with pip:
pip install -r requirements.txt
Linux
Python 3 should come preinstalled with most flavors of Linux, but if not, simply run
sudo apt update
sudo apt install python3 python3-lxml python3-requests
Then cd into the crawler's directory and run python3 crawler.py.
Crawler Installation
If you have git or GitHub Desktop installed, you can clone the repository from here. If not, download the latest source code or grab the latest release.
Launching
Use cd to navigate to the directory that spidy is located in, then run:
python crawler.py
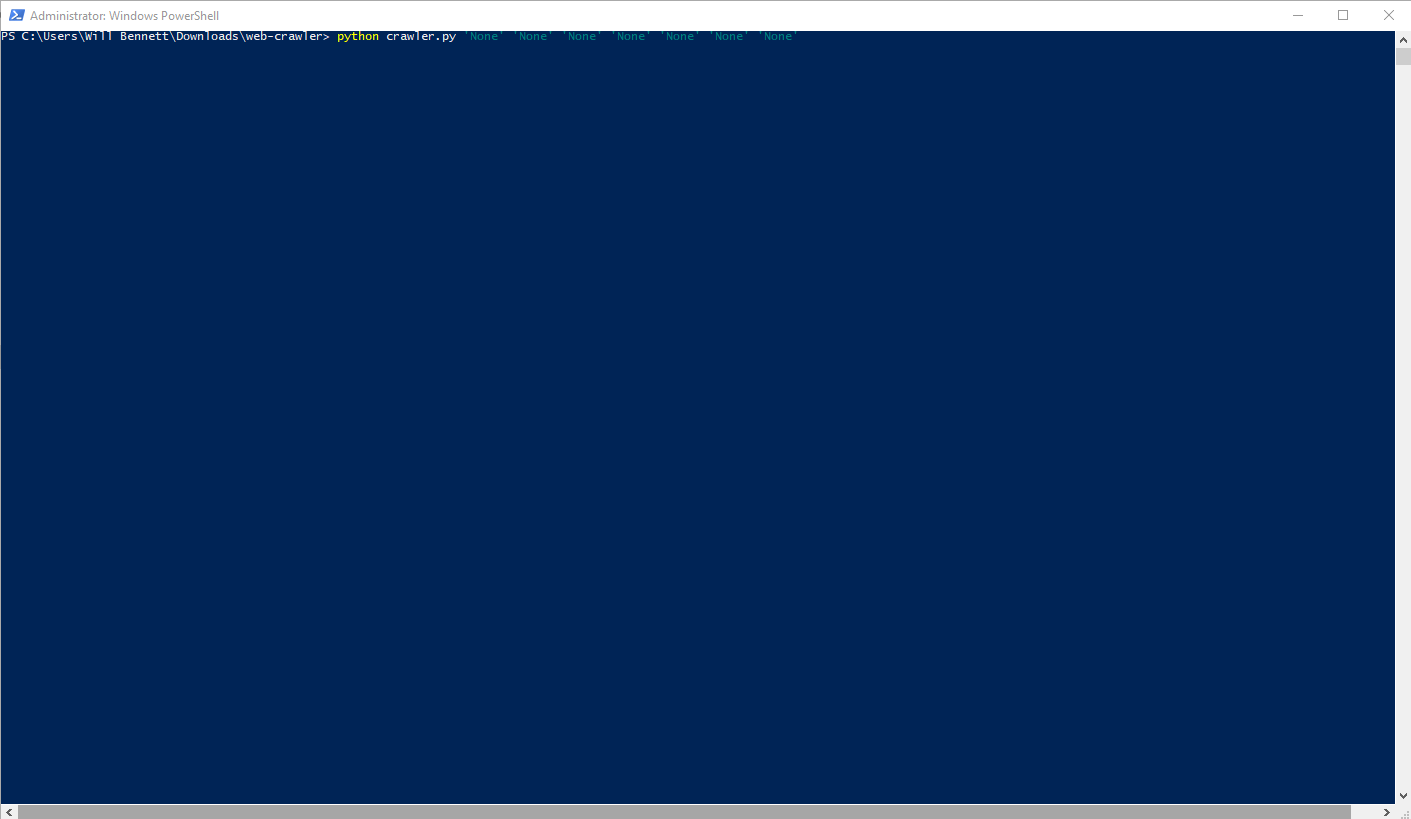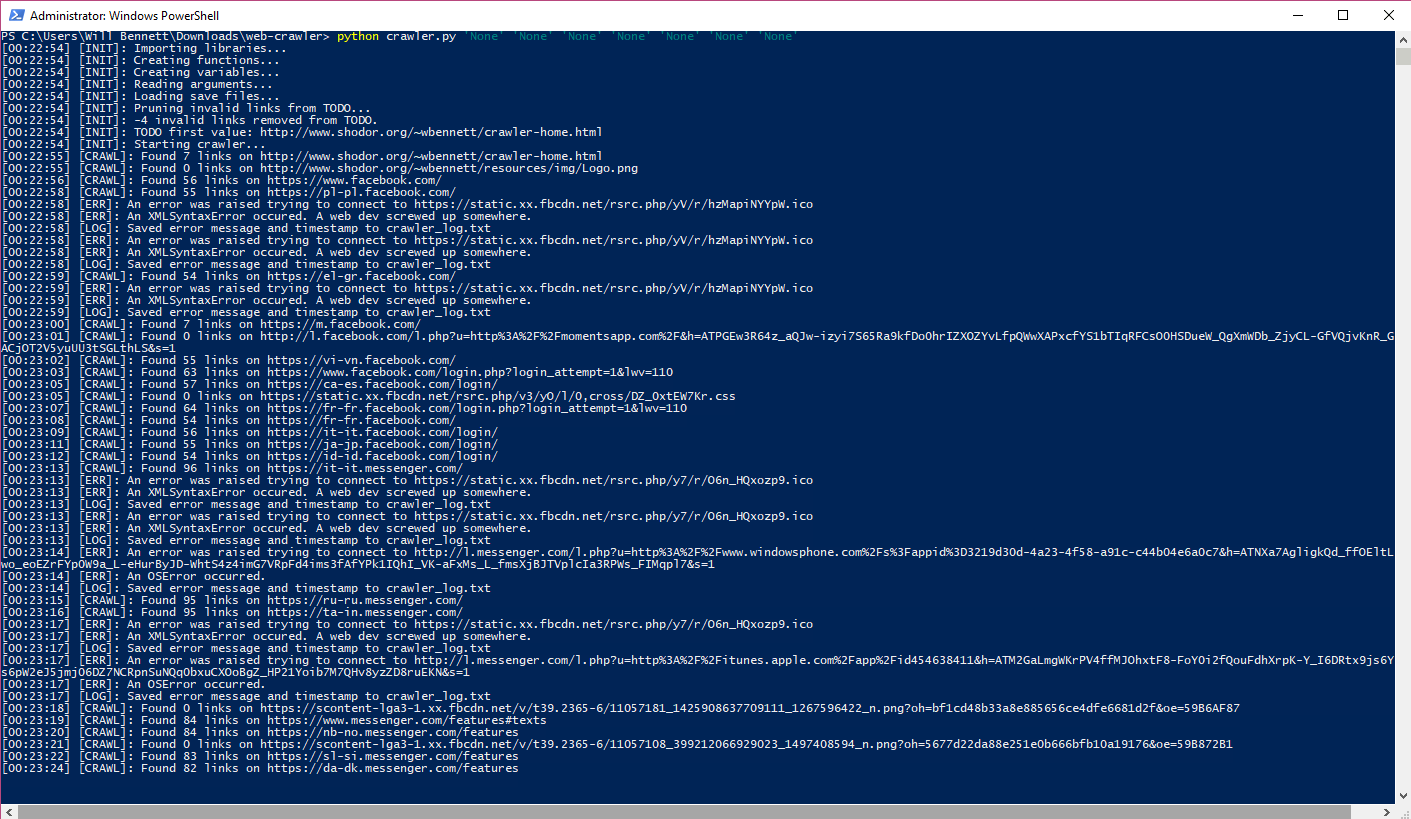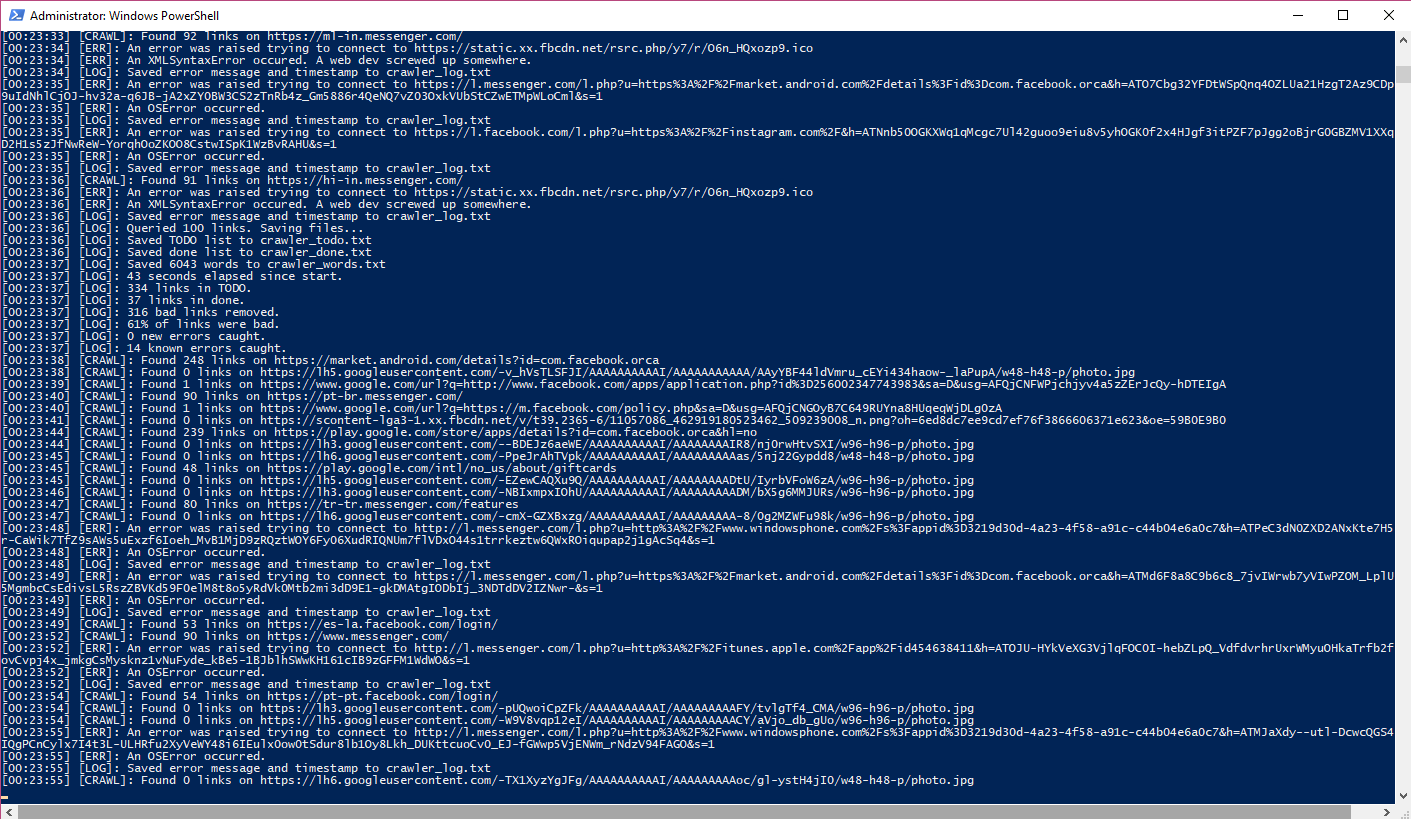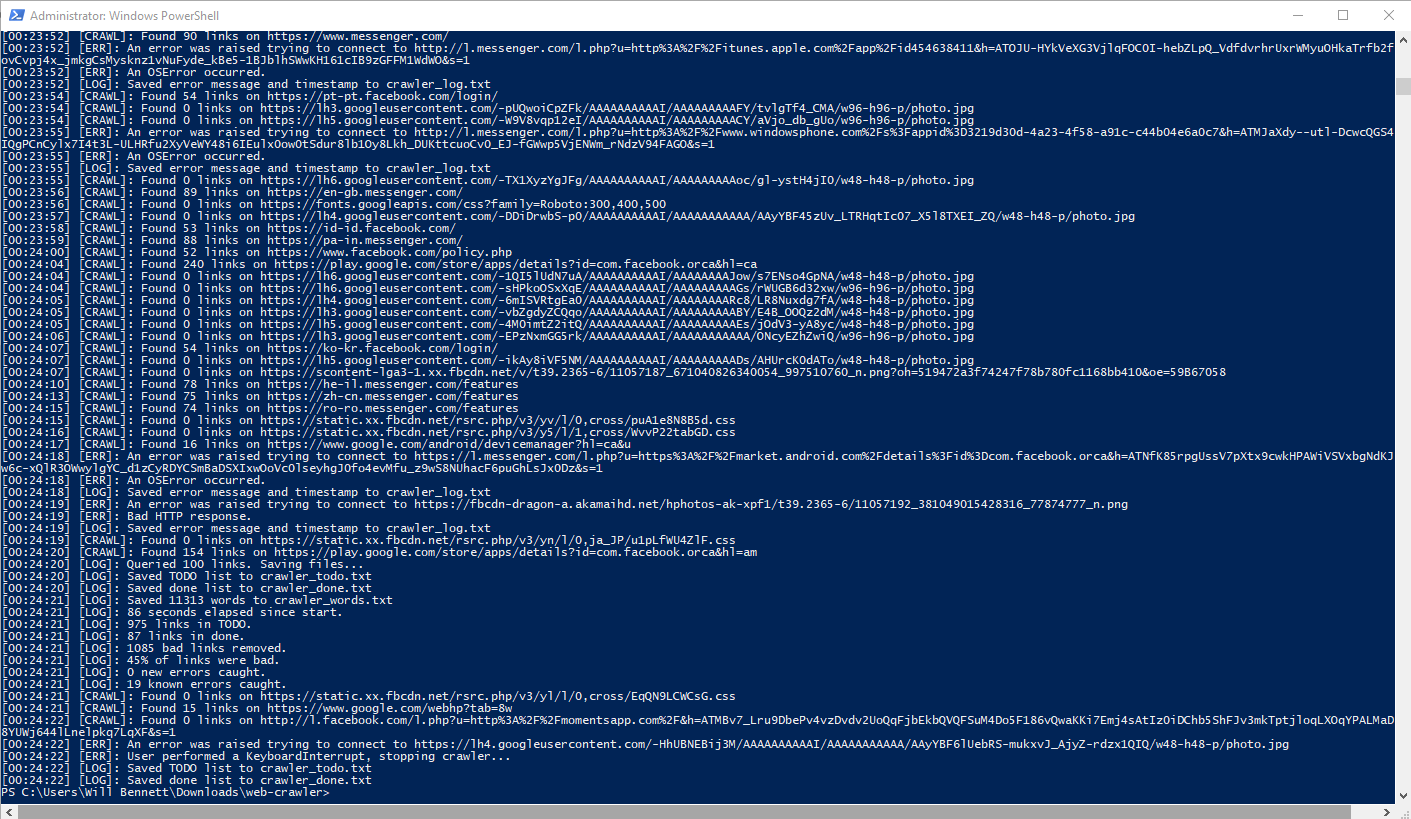
Running
Spidy logs a lot of information to the command line throughout its life.<br>
Once started, a bunch of [INIT] lines will print.<br>
These announce where spidy is in its initialization process.<br>
Config
On running, spidy asks for input regarding certain parameters it will run off of.<br> However, you can also use one of the configuration files, or even create your own.
To use spidy with a configuration file, input the name of the file when the crawler asks
The config files included with spidy are:
blank.txt: Template for creating your own configurations.default.cfg: The default version.heavy.cfg: Run spidy with all of its features enabled.infinite.cfg: The default config, but it never stops itself.light.cfg: Disable most features; only crawls pages for links.rivermont.cfg: My personal favorite settings.rivermont-infinite.cfg: My favorite, never-ending configuration.
Start
Sample start log.
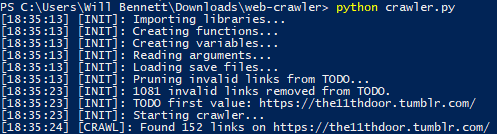
Autosave
Sample log after hitting the autosave cap.

Force Quit
Sample log after performing a ^C (CONTROL + C) to force quit the crawler.

How Can I Support This?
The easiest thing you can do is Star spidy if you think it's cool, or Watch it if you would like to get updates.<br>
If you have a suggestion, create an Issue or Fork the master branch and open a Pull Request.
Contributors
See the CONTRIBUTING.md
-
The logo was designed by Cutwell
-
3onyc - PEP8 Compliance.
-
DeKaN - Getting PyPI packaging to work.
-
esouthren - Unit testing.
-
Hrily - Multithreading.
-
j-setiawan - Paths that work on all OS's.
-
michellemorales - Confirmed OS/X support.
-
petermbenjamin - Docker support.
-
quatroka - Fixed testing bugs.
-
stevelle - Respect robots.txt.
-
thatguywiththatname - README link corrections.
License
We used the Gnu General Public License (see LICENSE) as it was the license that best suited our needs.<br>
Honestly, if you link to this repo and credit rivermont and FalconWarriorr, and you aren't selling spidy in any way, then we would love for you to distribute it.<br>
Thanks!