Awesome
Revisiting Data-Free Knowledge Distillation with Poisoned Teachers
This repository implements the paper: "Revisiting Data-Free Knowledge Distillation with Poisoned Teachers." Junyuan Hong*, Yi Zeng*, Shuyang Yu*, Lingjuan Lyu, Ruoxi Jia and Jiayu Zhou. ICML 2023. (*equal contribution)
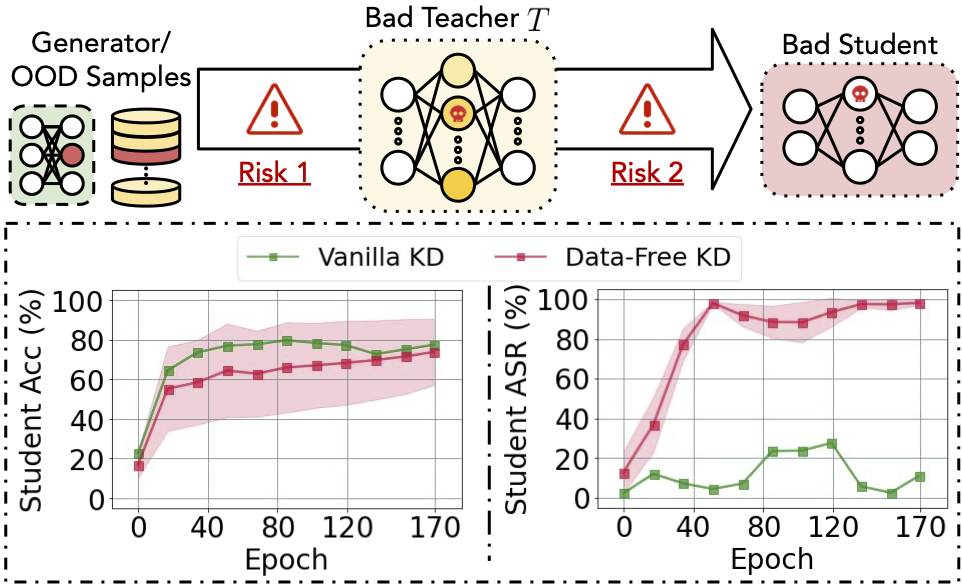
Data-free knowledge distillation (KD) helps transfer knowledge from a pre-trained model (known as the teacher model) to a smaller model (known as the student model) without access to the original training data used for training the teacher model. However, the security of the synthetic or out-of-distribution (OOD) data required in data-free KD is largely unknown and under-explored. In this work, we make the first effort to uncover the security risk of data-free KD w.r.t. untrusted pre-trained models. We then propose Anti-Backdoor Data-Free KD (ABD), the first plug-in defensive method for data-free KD methods to mitigate the chance of potential backdoors being transferred. We empirically evaluate the effectiveness of our proposed ABD in diminishing transferred backdoor knowledge while maintaining compatible downstream performances as the vanilla KD. We envision this work as a milestone for alarming and mitigating the potential backdoors in data-free KD.
Getting Started
Prepare for running.
- Install python env.
conda env create -f env.yml - Download pretrained models to
~/backdoor_zskt/which are trained using codes of Trap-and-Replace-Backdoor-Defense. Download GTSR dataset from here to./data/GTSRB. - Specify the root to pretrained models at utils/config.py. Change root paths where
TODOis noted.# TODO set up root to data. data_root = './data' ... # TODO specify your path root to pretrained models. BDBlocker_path = os.path.expanduser('~/backdoor_zskt/') ... - Signup wandb and set up by running
wandb loginwith your API from the website. Detailed instruction. - Check ZSKT or CMI (including OoD distillation) folders for running experiments.
Customization
Attack Data-free KD
Attacking is done by (1) pre-training a poisoned teacher on a poisoned dataset and (2) distill a student using the teacher model. Our repo provides datasets: CIFAR10, and GTSRB. CIFAR10 models are pre-trained by the codebase. Check ZSKT or CMI (including OoD) for attack runs and customization with your own data and model.
Defense by ABD
ABD includes two components. To use ABD your own data-free KD, refer to cmi/datafree_kd.py for examples of ABD. Below are key steps.
- Shuffling Vaccine (SV):
BackdoorSuspectLossin cmi/datafree/synthesis/syn_vaccine.py.from datafree.synthesis import BackdoorSuspectLoss # init suspect_loss = BackdoorSuspectLoss(teacher, coef=shufl_coef) suspect_loss.prepare_select_shuffle() # Add SV loss to yoour distillation loss. t_out = teacher(syn_images) loss = loss + suspect_loss.loss(t_out, syn_images) - Self-Retrospection (SR):
UnlearnOptimizerin cmi/datafree/unlearn/UnlearnOptimizer.pyfrom datafree.unlearn import UnlearnOptimizer from datafree.criterions import KLDiv # init unlearner = UnlearnOptimizer(KLDiv()) # Replace the distillation optimizer.step() with below unlearner.step(student, teacher, optimizer, syn_images, distill_criterion)
Citation
@inproceedings{hong2023abd,
title={Revisiting Data-Free Knowledge Distillation with Poisoned Teachers},
author={Hong, Junyuan and Zeng, Yi and Yu, Shuyang and Lyu, Lingjuan and Jia, Ruoxi and Zhou, Jiayu},
booktitle={ICML},
year={2023}
}
Acknowledgments
This work is supported partially by Sony AI, NSF IIS-2212174 (JZ), IIS-1749940 (JZ), NIH 1RF1AG072449 (JZ), ONR N00014-20-1-2382 (JZ), a gift and a fellowship from the Amazon-VT Initiative. We also thank anonymous reviewers for providing constructive comments. In addition, we want to thank Haotao Wang from UT Austin for his valuable discussion when developing the work.