Awesome
xtypes
Fast and lightweight C++17 header-only implementation of OMG DDS-XTYPES standard.
Getting Started
Given the following IDL,
struct Inner {
long a;
};
struct Outer {
long b;
Inner c;
};
you can create the representative C++ code defining this IDL's types using xtypes API:
StructType inner("Inner");
inner.add_member("a", primitive_type<int32_t>());
StructType outer("Outer");
outer.add_member("b", primitive_type<int32_t>());
outer.add_member("c", inner);
or by parsing the IDL:
idl::Context context = idl::parse(my_idl);
const StructType& inner = context.module().structure("Inner");
const StructType& outer = context.module().structure("Outer");
Once these types have been defined, you can instantiate them and access their data:
//create the DynamicData accordingly with the recently created "Outer" DynamicType
DynamicData data(outer);
//write value
data["c"]["a"] = 42;
// read value
int32_t my_value = data["c"]["a"];
Why should you use eProsima xtypes?
- OMG standard: eProsima xtypes is based on the DDS-XTYPES standard from the OMG.
- C++17 API: eProsima xtypes uses C++17 latest features, providing an easy-to-use API.
- Memory lightweight: data instances use the same memory as types built by the compiler. No memory penalty is introduced by using eProsima xtypes in relation to compiled types.
- Fast: Accessing to data members is swift and quick.
- Header only library: avoids the linking problems.
- No external dependency: eProsima xtypes's only dependencies are from std and
cpp-peglib(which is downloaded automatically). - Easy to use: Comprehensive API and intuitive concepts.
Build
eprosima xtypes is a header-only library: in order to use it you simply have to copy the files located in the include folder into your project and include them.
For a better management and version control, we recommend to make use of the CMake project that xtypes offers. Although there is no library generated by xtypes, you can do the linking with its target as following. This will enable the inclusion of xtypes headers:
target_link_libraries(${PROJECT_NAME} xtypes)
cpp-peglib library version
To link xtypes to a specific version of the cpp-peglib a CMake
cache variable is provided: XTYPES_PEGLIB_VERSION. If not specified defaults to master.
$ cmake .. -DXTYPES_PEGLIB_VERSION="v1.8.2"
$ make
Examples
To compile the examples located in the examples/ folder, enable the XTYPES_BUILD_EXAMPLES cmake flag.
Supposing you are in a build folder inside of xtypes top folder, you can run the following to compile the examples.
$ cmake .. -DXTYPES_BUILD_EXAMPLES=ON
$ make
Tests
xtypes uses GTest framework for testing.
The CMake project will download this internally if you compile with the XTYPES_BUILD_TESTS flag enabled.
Supposing you are in a build folder inside of xtypes top folder, you can run the following to compile the tests.
$ cmake .. -DXTYPES_BUILD_TESTS=ON
$ make
Tests are automatically deployed and executed via GitHub Actions each time new changes are introduced to the master branch or when a pull request is created.
By default, Valgrind tests will be omitted; if the introduced changes are considered to be deep enough to need a complete memcheck, please name your branch using the pattern valgrind/<branch_name>, so that GitHub Action step for Valgrind does not get bypassed and the memory check tests are executed.
API usage
Examples can be found in example folder.
The API is divided into two different and yet related concepts.
- Type definition: classes and methods needed for your runtime type definition.
- Data instance: set of values organized accordingly with its own type definition.
Type definition
All types inherit from the base abstract type DynamicType as shown in the following diagram:
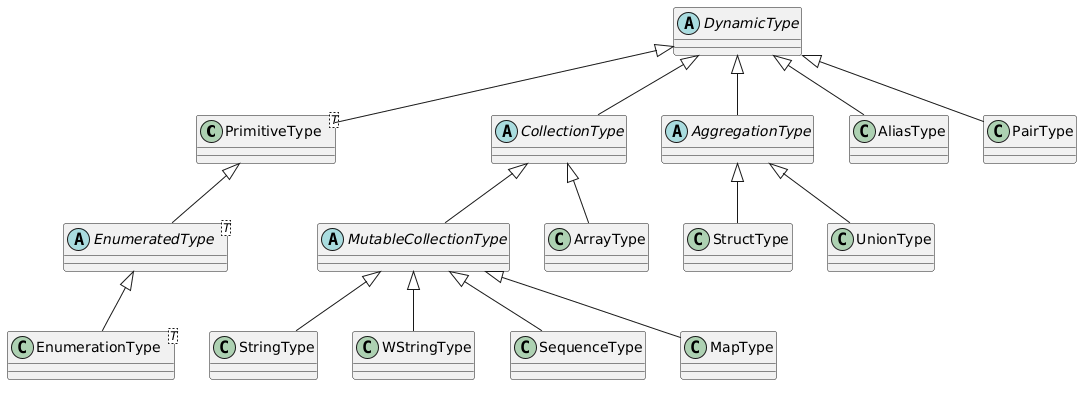
PrimitiveType
Represents the system's basic types.
In order to create a PrimitiveType, a helper function must be used:
const DynamicType& t = primitive_type<T>();
with T being one of the following basic types:
bool char wchar_t uint8_t int16_t uint16_t int32_t uint32_t int64_t uint64_t float double
long double
Enumerated Type
EnumeratedTypes are a special kind of PrimitiveTypes. They are internally represented by a PrimitiveType, but only allows a user-defined subset of values.
EnumerationType
Similar to C++ enum, enumerations are the most basic kind of EnumeratedTypes.
It can be bound to three different PrimitiveTypes, uint8_t, uint16_t, and uint32_t.
The possible values for the enumeration are defined adding them as identifiers.
The value can be explicitly specified or auto-assigned. Once an identifier is added, the next identifier's value must
be greater than the previous one. By default, the first added value is zero (0).
EnumerationType<uint32_t> my_enum("MyEnum");
my_enum.add_enumerator("A"); // The value of MyEnum::A is 0. The default initial value.
my_enum.add_enumerator("B", 10); // The value of MyEnum::B is 10. Explicitely defined.
my_enum.add_enumerator("C"); // The value of MyEnum::C is 11. Implicitely assigned.
DynamicData enum_data(my_enum); // DynamicData of type "MyEnum".
enum_data = my_enum.value("C"); // Assign to the data the value of MyEnum::C.
uint32_t value = enum_data; // Retrieve the data as its primitive type.
DynamicData enum_data2 = enum_data; // Copy the DynamicData.
enum_data2 = uint32_t(10); // Assign to the copy, a raw value from its primitive type.
Assign or retrieve enumeration data of a different primitive type isn't allowed, so the user should cast the value by himself.
Assign a value that doesn't belong to the enumeration isn't supported.
Collection Type
As pointed by the self-explanatory name, CollectionTypes provide a way to create the most various collections. There are several collection types:
ArrayType: fixed-size set of elements. Similar to C-like arrays.SequenceType: variable-size set of elements. Equivalent to C++std::vectorStringType: variable-size set of char-type elements. Similar to C++std::stringWStringType: variable-size set of wchar-type elements. Similar to C++std::wstringMapType: variable-size set of pairs. Equivalent to C++std::map.
ArrayType a1(primitive_type<int32_t>(), 10); //size 10
ArrayType a2(structure, 10); //Array of structures (structure previously defined as StructType)
SequenceType s1(primitive<float>()); //unbounded sequence
SequenceType s2(primitive<float>(),30); //bounded sequence, max size will be 30
SequenceType s3(SequenceType(structure), 20); //bounded sequence of unbounded sequences of structures.
StringType str1; //unbounded string
StringType str2(50); //bounded string
WStringType wstr(); //unbounded wstring
MapType m1(StringType(), primitive_type<float>()); // unbounded map, key of type string, value of type float.
MapType m2(primitive_type<uint32_t>(), structure, 10); // bounded map, max size of 10, key as uint32_t, value as struct.
size_t a1_bounds = a1.bounds(); // As a1 is an ArrayType, its bounds are equal to its size.
size_t s1_bounds = s1.bounds(); // As s1 is an unbounded sequence, its bounds are 0.
size_t s2_bounds = s2.bounds(); // As s2 is a bounded sequence, its bounds are 30.
size_t s3_bounds = s3.bounds(); // As s3 is a bounded sequence, its bounds are 20.
size_t str1_bounds = str1.bounds(); // As str1 is an unbounded string, its bounds are 0.
size_t str2_bounds = str2.bounds(); // As str2 is a bounded string, its bounds are 50.
size_t m1_bounds = m1.bounds(); // As m1 is an unbounded map, its bounds are 0.
size_t m2_bounds = m2.bounds(); // As m2 is a bounded map, its bounds are 10.
PairType
MapType is a specialization of CollectionType which content is a set of pairs.
These pairs are represented internally by an auxiliar type named PairType.
PairType pair(StringType(), primitive_type<uint32_t>);
std::cout << pair.first().name() << std::endl; // Prints "std::string".
std::cout << pair.second().name() << std::endl; // Prints "uint32_t".
Multidimensional ArrayType
In a C-like language, the programmer can define multidimensional arrays as an array of array. For example:
int array[2][3];
Using ArrayType, the same can be achieved just creating an array, and then using it as the content of the outer array:
ArrayType array(ArrayType(primitive_type<int32_t>(), 3), 2); // Conceptually equivalent to "int array[2][3];"
Note that the dimensions are swapped, because the inner array is the second index.
To ease this kind of type definition, ArrayType provides a constructor that receives an std::vector of dimensions (uint32_t).
This constructor receives the indexes in the natural order, like in the C-like example:
ArrayType array(primitive_type<int32_t>, {2, 3});
StructType
Similarly to a C-like struct, a StructType represents an aggregation of members.
You can specify a StructType given the type name of the structure.
StructType my_struct("MyStruct");
Once the StructType has been declared, any number of members can be added.
my_struct.add_member(Member("m_a", primitive_type<int32_t>()));
my_struct.add_member(Member("m_b", StringType()));
my_struct.add_member(Member("m_c", primitive_type<double>().key().id(42))); //with annotations
my_struct.add_member("m_d", ArrayType(25)); //shortcut version
my_struct.add_member("m_e", other_struct); //member of structs
my_struct.add_member("m_f", SequenceType(other_struct)); //member of sequence of structs
Note: once a DynamicType is added to an struct, a copy is performed.
This allows modifications to DynamicType to be performed without side effects.
It also and facilitates the user's memory management duties.
StructType inheritance
A StructType can inherit from another StructType by using a pointer to the parent structure in the
constructor of the child struct.
The child struct will contain all the members defined by its parent, followed by its own members.
A struct can check if inherit from another struct by calling the has_parent() method.
The child struct can access to its parent using the parent() method, which should be called only if
has_parent() returns true.
StructType parent("ParentStruct");
parent.add_member(Member("parent_uint32", primitive_type<uint32_t>()));
parent.add_member(Member("parent_string", StringType()));
StructType child("ChildStruct", &parent);
child.add_member(Member("child_string", StringType()));
StructType grand_child("GrandChildStruct", &child);
grand_child.add_member(Member("grand_child_float", primitive_type<float>()));
grand_child.add_member(Member("grand_child_double", primitive_type<double>()));
if (grand_child.has_parent())
{
std::cout << "Inherits from: " << grand_child.parent().name() << std::endl;
}
UnionType
Similar to a C-like union or a StructType but with only one member active at the same time. It is defined by a discriminator and a list of labels allowing to identify the current active member.
UnionType my_union("MyUnion", primitive_type<char>());
The allowed discriminator types are all the no floating point primitives, EnumerationType, and AliasType that solves (directly or indirectly) to any other allowed type.
Once the UnionType has been declared, any number of case members can be added, defining the labels that
belong to the case member.
It is possible to define a default case for one member, which will be selected when the DynamicData is built.
This can be done setting the flag is_default to true in the add_case_member method (false by default), or
defining a label named default when using a list of strings as labels.
my_union.add_case_member<char>({'a', 'b'}, Member("m_ab", StringType());
std::vector<char> label_list = {'c', 'd', 'e'};
my_union.add_case_member(label_list, Member("m_cde", primitive_type<float>());
my_union.add_case_member<char>({}, Member("m_default", primitive_type<uint32_t>()), true);
This code is equivalent to the following one:
my_union.add_case_member<std::string>({"a", "b"}, Member("m_ab", StringType());
std::vector<std::string> label_list = {"c", "d", "e"};
my_union.add_case_member(label_list, Member("m_cde", primitive_type<float>());
my_union.add_case_member<std::string>({"default"}, Member("m_default", primitive_type<uint32_t>()));
A case member without labels must be default.
AliasType
Acts as a C-like typedef, allowing to specify a custom name for an already existing type. They can be used as any other DynamicType. Recursive aliasing is supported, meaning you can assign a new alias to an already existing alias. When a DynamicData is created using an AliasType as its type specificator, the inner type pointed by the alias is retrieved and used to create the DynamicData field.
AliasType my_alias(primitive_type<uint32_t>(), "unsigned32"); // As in C "typedef uint32_t unsigned32;"
AliasType my_alias2(my_alias, "u32"); // As in C "typedef unsigned32 u32;"
StructType my_struct("MyStruct");
my_struct.add_member("m_al", my_alias);
DynamicData struct_data(my_struct);
struct_data["m_al"] = 20u; // Internal uint32_t primitive type is accessed
DynamicData alias_data(my_alias2);
alias_data = 30u; // Internal uint32_t primitive type is accessed
Type Consistency (QoS policies)
Any pair of DynamicTypes can be checked for their mutual compatibility.
TypeConsistency consistency = tested_type.is_compatible(other_type);
This line will evaluate consistency levels among the two types.
The returned TypeConsistency is going to be a subset of the following QoS policies:
NONE: Unknown way to interpret both types as equivalents.EQUALS: The evaluation is analogous to an equal evaluation.IGNORE_TYPE_SIGN: the evaluation will be true independently of the sign.IGNORE_TYPE_WIDTH: the evaluation will be true if the width of the some primitive types are less or equals than the other type.IGNORE_SEQUENCE_BOUNDS: the evaluation will be true if the bounds of the some sequences are less or equals than the other type.IGNORE_ARRAY_BOUNDS: same asIGNORE_SEQUENCE_BOUNDSbut for the case of arrays.IGNORE_STRING_BOUNDS: same asIGNORE_SEQUENCE_BOUNDSbut for the case of string.IGNORE_MEMBER_NAMES: the evaluation will be true if the names of some members differs (but no the position).IGNORE_MEMBERS: the evaluation will be true if some members ofother_typeare ignored.
Note: TypeConsistency is an enum with | and & operators overriden to manage it as a set of QoS policies.
Module
Modules are equivalent to C++ namespaces. They can store sets of StructType, Constants and other Modules (as submodules). They allow organizing types into different scopes, allowing scope solving when accessing the stored types.
Module root;
Module& submod_a = root.create_submodule("a");
Module& submod_b = root.create_submodule("b");
Module& submod_aa = submod_a.create_submodule("a");
root.structure(inner);
submod_aa.structure(outer);
std::cout << std::boolalpha;
std::cout << "Does a::a::OuterType exists?: " << root.has_structure("a::a::OuterType") << std::endl; // true
std::cout << "Does ::InnerType exists?: " << root.has_structure("::InnerType") << std::endl; // true
std::cout << "Does InnerType exists?: " << root.has_structure("InnerType") << std::endl; // true
std::cout << "Does OuterType exists?: " << root.has_structure("OuterType") << std::endl; // false
DynamicData module_data(root["a"]["a"].structure("OuterType")); // ::a::a::OuterType
module_data["om3"] = "This is a string.";
As can be seen in the example, a module allows the user to access their internal definitions in two ways:
Accessing directly using a scope name (root.structure("a::a::OuterType")), or navigating manually through the
inner modules (root["a"]["a"].structure("OuterType")).
Data instance
Initialization
To instantiate a data, only is necessary a DynamicType:
DynamicData data(my_defined_type);
This line allocates all the memory necessary to hold the data defined by my_defined_type
and initializes their content to 0 or to the corresponding default values.
Please, note that the type must have a higher lifetime than the DynamicData,
since DynamicData only saves a reference to it.
Other ways to initialize a DynamicData are respectively copy and compatible copy.
DynamicData data1(type1); //default initalization
DynamicData data2(data1); //copy initialization
DynamicData data3(data1, type2); //compatible copy initialization
The last line creates a compatible DynamicData with the values of data1 that can be accessed being a type2.
To achieve this, type2 must be compatible with type1.
This compatibility can be checked with is_compatible function.
Internal data access
Depending on the type, the DynamicData will behave in different ways.
The following methods are available when:
-
DynamicDatarepresents aPrimitiveType,StringTypeorWStringType(ofint32_tas example):data.value(42); //sets the value to 42 data = 23; // Analogous to the one above, assignment from primitive, sets the value to 23 int32_t value = data.value<int32_t>(); //read the value int32_t value = data; //By casting operator data = "Hello again!"; // set string value data = L"Hello again! \u263A"; // set string value -
DynamicDatarepresents aPairType. Similar to C++std::pair, but usingoperator[](size_t)to access each member, using 0 to accessfirstand 1 to accesssecond.data[0] = first_value; // set "first" member value to "first_value". data[1] = second_value; // set "second" member value to "second_value". -
DynamicDatarepresents anAggregationTypedata["member_name"] = 42; //set value 42 to the int member called "member_name" data[2] = 42; //set value 42 to the third int member. int32_t value = data["member_name"]; // get the value from member_name member. int32_t value = data[2]; // get the value from third member. data["member_name"].value(dynamic_data_representing_a_value); WritableDynamicDataRef ref = data["member_name"]; size_t size = data.size(); //number of members for (ReadableDynamicDataRef::MemberPair&& elem : data.items()) // Iterate through its members. { if (elem.kind() == TypeKind::INT_32_TYPE) { std::cout << elem.type().name() << " " << elem.name() << ": " << elem.value<int32_t>() << std::endl; } } -
DynamicDatarepresents anUnionTypeSame asAggregationTypebut:- Doesn't allow accessing members by index.
- Accessing a member by name sets it as the active member. And plus:
DynamicData disc = data.d(); // Access to the current discriminator value. data.d(disc); // Modifies the discriminator value accordingly the CPP11 mapping for IDL (https://www.omg.org/spec/CPP11/1.4/PDF) DynamicData member_data = data.get_member("member_name"); // Retrieves the member only if is the active member (checks are applied). -
DynamicDatarepresents aCollectionType(except a MapType)data[2] = 42; // set value 42 to position 2 of the collection. int32_t value = data[2]; // get value from position 2 of the collection data[2] = dynamic_data_representing_a_value; WritableDynamicDataRef ref = data[2]; //references to a DynamicData that represents a collection size_t size = data.size(); //size of collection for (WritableDynamicDataRef&& elem : data) // Iterate through its contents. { elem = 0; } -
DynamicDatarepresents aMapType. The map must be accessed by its key (using always a DynamicData instance of the key type) or iterated through its pairs. Accessing the map using the index is forbidden because if the map's key is a numeral type, this may lead to confusion to the user. For example, does the user want to access the value associated with that index value, or access to the pair stored at the index position? These pairs are ordered internally using a hashing the key's value, so the order while iterating may change after any modification of the map.IMPORTANT: Don't modify the key value while iterating the pairs of a map, it probably makes the map unusable.
StringType key_type; MapType map_type(key_type, primitive_type<uint64_t>()); DynamicData data(map_type); DynamicData key(key_type); key = "First"; data[key] = 55; // Adds the value 55 associated to the key "First". key = "Second"; data[key] = 42; // Adds the value 42 associated to the key "Second". key = "First"; data[key] = 1000; // Modifies the value associated to the key "First" to 1000. uint64_t value = data.at(key); // Retrieves the value associated to the key "First", failing if it doesn't exists. key = "Third"; value = data[key]; // Adds a new entry for the key "Third", returning a default-initialized value. key = "First"; value = data[key]; // As "First" already exists, returns it associated value. WritableDynamicDataRef ref = data[key]; //references to a DynamicData representing the value associated to "Third". size_t size = data.size(); // size of the map (number of pairs). for (WritableDynamicDataRef&& elem : data) // Iterate through its pairs. { elem[1] = 23; // Values associated to all keys will be set to 23. //elem[0] = "Don't do this"; // Never modify the key in this way, or the map may become unusable. } -
DynamicDatarepresents aStringType. Same asCollectionTypeplus:data = "Hello again!"; // set string value const std::string& s1 = data.value<std::string>(); //read the string value const std::string& s2 = data.string(); // shortcut version for string for (WritableDynamicDataRef&& elem : data) // Iterate through its contents. { elem = 'A'; } -
DynamicDatarepresents aWStringType. Same asCollectionTypeplus:data = L"Hello again! \u263A"; // set string value const std::wstring& s1 = data.value<std::wstring>(); //read the string value const std::wstring& s2 = data.wstring(); // shortcut version for string for (WritableDynamicDataRef&& elem : data) // Iterate through its contents. { elem = L'A'; } -
DynamicDatarepresents aSequenceType. Same asCollectionTypeplus:data.push(42); // push back new value to the sequence. data.push(dynamic_data_representing_a_value); data.resize(20); //resize the vector (same behaviour as std::vector::resize()) size_t max_size = data.bounds(); // Maximum size of the sequence for (WritableDynamicDataRef&& elem : data) // Iterate through its contents. { elem = 0; }
References to DynamicData
There are two ways to obtain a reference to a DynamicData:
ReadableDynamicDataReffor constant references.WritableDynamicDataReffor mutable references.
A reference does not contain any value and only points to an already existing DynamicData, or to part of it.
You can obtain a reference by accessing data with [] operator or by calling ref() and cref().
Depending on whether the reference comes from a const DynamicData or a DynamicData, a ReadableDynamicDataRef
or a WritableDynamicDataRef is returned.
== function of DynamicData
A DynamicData can be compared in depth with another one.
The type should be the same.
for_each function of DynamicData
This function provides an easy way to iterate the DynamicData tree.
for_each receive a visitor callback that will be called for each node of the tree.
data.for_each([&](const DynamicData::ReadableNode& node)
{
switch(node.type().kind())
{
case TypeKind::STRUCTURE_TYPE:
case TypeKind::SEQUENCE_TYPE:
case TypeKind::ARRAY_TYPE:
case TypeKind::STRING_TYPE:
case TypeKind::UINT_32_TYPE:
case TypeKind::FLOAT_32_TYPE:
//...
}
});
The node callback parameters can be either ReadableNode or WritableNode, depending on DynamicData mutability,
and provides the following methods for introspection
node.data() // for a view of the data
node.type() // related type
node.deep() // nested deep
node.parent() // parent node in the data tree
node.from_index() // index used when accessed from parent to this node
node.from_member() // member used when accessed from parent to this node
Note: node.data() will return a ReadableDynamicDataRef or a WritableDynamicDataRef depending of the node type.
In order to break the tree iteration, the user can throw a boolean value.
For example:
case TypeKind::FLOAT_128_TYPE: // The user app does not support 128 float values
throw false; // Break the tree iteration
The boolean exception value will be returned by for_each function call.
If the visitor callback implementation does not call an exception, for_each function returns true by default.
Operators of DynamicData
The most common operators can be used with DynamicData instances, as long as they represent primitive
values. The same rules that are applicable for these operators apply to DynamicData; for instance, the
% operator cannot be used in operations between floating-point values.
Available operators are:
-
Unary operators: applied to the DynamicData itself.
- Logical:
!(additionally, checks for emptiness in (W)StringType datatypes). - Increment/decrement:
++data,--data,data++,data--. - Arithmetic:
-(sign change),~(bitwise complement).
- Logical:
-
Binary operators: between two DynamicData; return a new DynamicData with the operation result.
- Arithmetic:
+,-,*,/,%,&,|,^,<<,>>. - Logical:
&&,||. - Comparison:
==,!=,<,>,<=,>=.
- Arithmetic:
-
Self-assign operators: perform same operations as binary operators, but the result is assigned to left-side operand, overriding its current value:
+=,-=,*=,/=,%=,&=,|=,^=,<<=,>>=.
Iterators of DynamicData
There exists two kinds of iterators:
-
Collection iterators: Allows to iterate through collections (
ArrayType,SequenceType, andMapType) in the same way of native C++17 types. They can be accessed fromReadableDynamicDataRef::Iterator(for read-only operations) orWritableDynamicDataRef::Iterator(for read-write operations).ReadableDynamicDataRef::Iterator it = data.begin(); WritableDynamicDataRef::Iterator wit = data.begin(); for (ReadableDynamicDataRef&& elem : data) { [...] } for (WritableDynamicDataRef&& elem : data) { [...] }While iterating a
MapType, similarly as in the C++17 map iterator, aPairTypeinstance is returned. To access the elements of the pair (the map's key) theoperator[](size_t)must be used. Only indexes0and1are allowed.DynamicData map(MapType(key_type, value_type); map[key_type_data] = value_type_data; ReadableDynamicDataRef::Iterator it = map.begin(); std::cout << "Key: " << (*it)[0].cast<std::string>() << std::endl; std::cout << "Value: " << (*it)[1].cast<std::string>() << std::endl; -
Aggregation iterator: Allows to iterate through members of an aggregation. They make use of an auxiliary class MemberPair to allow access both, data and member information such as name. They can be accessed from
ReadableDynamicDataRef::MemberIterator(read-only) orWritableDynamicDataRef::MemberIterator(read-write), through theitems()orcitems()methods.// Explicit request for ReadableDynamicDataRef using citems(). ReadableDynamicDataRef::MemberIterator it = my_data.citems().begin(); // Typically items() is enough WritableDynamicDataRef::MemberIterator it = my_data.items().begin(); for (ReadableDynamicDataRef::MemberPair&& elem : my_data.items()) { [...] } for (WritableDynamicDataRef::MemberPair&& elem : my_data.items()) { [...] }
Performance
The DynamicData instance uses the minimal allocations needed to store any data.
If its associated type only contains the following (nested) types: PrimitiveType, StructType, or ArrayType;
the memory required can be allocated with only one allocation during the creation phase of the DynamicData.
On the other hand, each inner MutableCollectionType will trigger a further allocation.
Let see an example:
StructType inner("Inner");
inner.add_member("m_int", primitive_type<int32_t>());
inner.add_member("m_float", primitive_type<float>());
inner.add_member("m_array", ArrayType(primitive_type<uint16_t>(), 4));
DynamicData data(inner);
Such data will be represented in memory as follows. Only one memory allocation is needed:

The next complex type:
StructType outer("Outer");
outer.add_member("m_inner", inner);
outer.add_member("m_array_inner", ArrayType(inner, 4));
outer.add_member("m_sequence_inner", SequenceType(inner, 4));
outer.add_member("m_string", StringType());
DynamicData data(outer);
In this case, two more allocations will be needed: one for the sequence, and a second one for the string:

IDL module
Parser
xtypes comes with a runtime IDL parser. This parser is able to translate an IDL 4.2 (most used features already implemented and growing!) file into xtypes. The parser allows a path to a file or a raw IDL string as input.
std::string idl = R"~~~(
struct Inner
{
uint32_t my_uint32;
};
struct Outer
{
Inner my_inner;
};
)~~~";
// Parse a raw string.
idl::Context context = idl::parse(my_idl);
const StructType& inner = context.module().structure("Inner");
const StructType& outer = context.module().structure("Outer");
//Parse an IDL file.
idl::Context context_file = idl::parse_file(my_idl_file);
In both cases, an idl::Context object can be used to configure and retrieve the parser results.
The available configuration options are:
ignore_caseWhen enabled, the parser isn't case sensitive (defaultfalse).clearWhen enabled, following calls toparsewill clean up previous results (defaulttrue).preprocessWhen enabled, the preprocessor will be called before start parsing (defaulttrue).allow_keyword_identifiersWhen enabled, the parser will allow identifiers to be named as keywords (defaultfalse) for example:Struct Struct { ... };.ignore_redefinitionWhen enabled, the parser will ignore type redefinitions (defaultfalse).char_translationTells the parser how to interpret the keywordchar. Possible values are:CHAR,UINT8, andINT8(defaultCHAR).preprocessor_execSpecifies the preprocessor executable to launch (default "cpp"`).include_pathsList of paths where the preprocessor should look for included idl files.
Other Log related options are explained in the Log section.
The results of the parsing are mainly two:
successBoolean value with the result of the parsing.moduleAccess to the root module of the parsed IDL. It will contain defined types and submodules.name: Retrieves the name of the module. It is empty for the root module.scope: Retrieves the full scope of the module. It is empty for the root module.submodule: Allows access to a submodule by name.operator[]is available for the same purpose.has_submodule: Checks the existence of a module by name.structure: Allows access to a defined structure by name.has_structure: Checks for the existence of a structure by name.constant: Allows access to a defined constant by name.has_constant: Checks for the existence of a constant by name.enum_32: Allows access to a defined enumeration by name (only 32 bits enumeration is supported currently).has_enum_32: Check for the existence of a numeration by name.alias: Allows access to a defined alias by name.has_alias: Checks for the existence of an alias by name.get_all_types: Retrieves a map with all the defined types.fill_all_types: Fills an existant map with all the defined types.
It has, two helper functions to ease the retrieval of all types:
get_all_types: Retrieves a map with all the defined types.get_all_scoped_types: Retrieves a map with all the defined types, whose key is with the scoped name.
Log
The parser comes with a Log utility. The parser will log automatically different kind of events happened while
parsing an IDL. Using the Context the user can customize the Log behavior and retrieve its results:
log_level(LogLevel)This method sets up the verbosity level (or severity) of the log. The available options areDEBUG,INFO,WARNING, andERROR(by defaultWARNING).log_level()Retrieves the current verbosity level.print_log(enable)When enabled, it prints each log event to the standard output when parsing.log()Retrieves the complete list of LogEvent created during the parsing.log(LogLevel, strict)Retrieves a subset of LogEvent created during the parsing filtering by LogLevel. Ifstrictis set to true, then it will return only LogEvents with the same LogLevel. Else (default), it will return LogEvents with the same or higher severity.
Generator
Analogous but in the opposite direction of the parse() method, you can generate IDL content from your defined types.
Exists two methods to archive this.
generator(const StructType& type), that generates the corresponding IDL for the given structure (and all its dependencies).generator(const Module& module), that generates the corresponding IDL of the entire module.
Debugging DynamicData
As a DynamicData is fully built at runtime, no static checks can ensure its correct behaviour.
As an attempt to solve this, asserts have been placed across various methods to avoid the overload of checks in
release mode.
We strongly recommend to compile in debug mode during developing phase: this will allow xtypes library to
perform all possible checks.
Following the same line of thoughts, in order to improve the performance the final product should be compiled in
release mode. In this case, no checks will be performed.
Reminder: assert function from std emit an abort signal.
If you need more information about why a concrete assert was reached, the stacktrace is really useful.
Exceptions
If this approach doesn't meet the security expectations, runtime exceptions (std::runtime_error) can be enabled
by defining the preprocessor variable XTYPES_EXCEPTIONS at compile time.
Take into account that throwing exceptions adds a small performance penalty.
StructType outer("Outer");
outer.add_member("m_inner", inner);
DynamicData data(outer);
try
{
data["invalid_name"] = 55; // data doesn't have a member named so, a runtime_error will be throw.
}
catch(const std::runtime_error& e)
{
std::cout << "Exception: " << e.what() << std::endl;
}
The exceptions will be thrown both in debug mode and in release mode.