Awesome
ViT-Adapter
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The official implementation of the paper "Vision Transformer Adapter for Dense Predictions".
Paper | Blog in Chinese | Slides | Poster | Video in English | Video in Chinese
{kind=link}
Segmentation Colab Notebook | Detection Colab Notebook (thanks @IamShubhamGupto, @dudifrid)
News
2024/01/19: Train ViT-Adapter with frozen InternViT-6B, see here!2023/12/23: 🚀🚀🚀 We release a ViT-based vision foundation model with 6B parameters, see here!2023/08/31: 🚀🚀 DINOv2 released the ViT-g-based segmentor with ViT-Adapter, see here.2023/07/10: 🚀 Support the weights of DINOv2 for object detection, see here!2023/06/26: ViT-Adapter is adopted by the champion solution NVOCC in Track 3 (3D Occupancy Prediction) of the CVPR 2023 Autonomous Driving Challenge.2023/06/07: ViT-Adapter is used by ONE-PEACE and they created new SOTA of 63.0 mIoU on ADE20K.2023/04/14: ViT-Adapter is used in EVA and DINOv2!2023/01/21: Our paper is accepted by ICLR 2023!2023/01/17: We win the champion of WSDM Cup 2023 Toloka VQA Challenge using ViT-Adapter.2022/10/20: ViT-Adapter is adopted by Zhang et al. and they ranked 1st in the UVO Challenge 2022.2022/08/22: ViT-Adapter is adopted by BEiT-3 and created new SOTA of 62.8 mIoU on ADE20K.2022/06/09: ViT-Adapter-L achieves 60.4 box AP and 52.5 mask AP on COCO test-dev without Objects365.2022/06/04: Code and models are released.2022/05/12: ViT-Adapter-L reaches 85.2 mIoU on Cityscapes test set without coarse data.2022/05/05: ViT-Adapter-L achieves the SOTA on ADE20K val set with 60.5 mIoU!
Highlights
- ViT-Adapter supports various dense prediction tasks, including
object detection,instance segmentation,semantic segmentation,visual grounding,panoptic segmentation, etc. - This codebase includes many SOTA detectors and segmenters to achieve top performance, such as
HTC++,Mask2Former,DINO.
Abstract
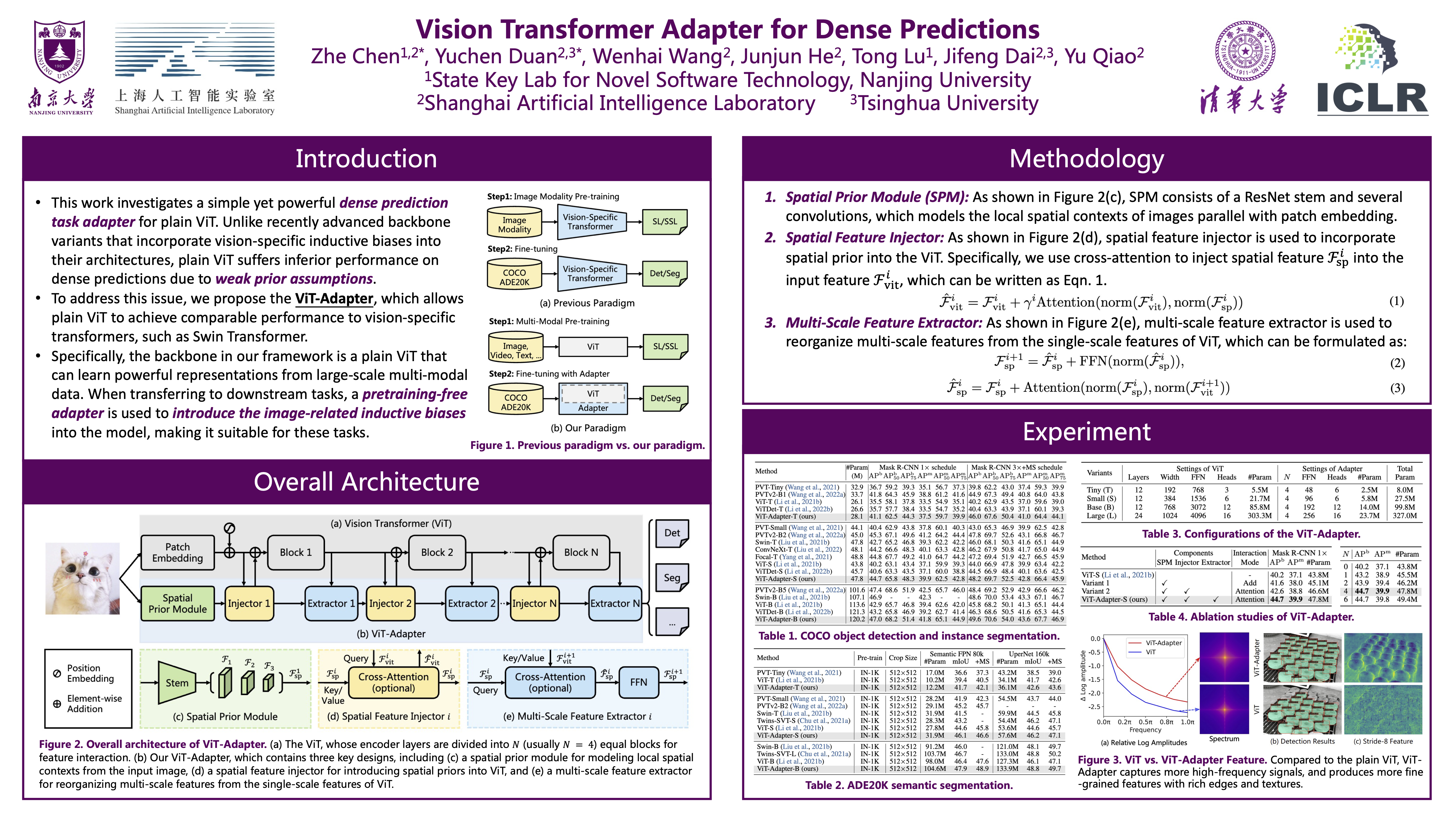
This work investigates a simple yet powerful dense prediction task adapter for Vision Transformer (ViT). Unlike recently advanced variants that incorporate vision-specific inductive biases into their architectures, the plain ViT suffers inferior performance on dense predictions due to weak prior assumptions. To address this issue, we propose the ViT-Adapter, which allows plain ViT to achieve comparable performance to vision-specific transformers. Specifically, the backbone in our framework is a plain ViT that can learn powerful representations from large-scale multi-modal data. When transferring to downstream tasks, a pre-training-free adapter is used to introduce the image-related inductive biases into the model, making it suitable for these tasks. We verify ViT-Adapter on multiple dense prediction tasks, including object detection, instance segmentation, and semantic segmentation. Notably, without using extra detection data, our ViT-Adapter-L yields state-of-the-art 60.9 box AP and 53.0 mask AP on COCO test-dev. We hope that the ViT-Adapter could serve as an alternative for vision-specific transformers and facilitate future research. The code and models will be released.
Method
<img width="810" alt="image" src="https://user-images.githubusercontent.com/23737120/217998186-8a37eacb-18f8-445a-8d92-0863e35712ab.png"> <img width="810" alt="image" src="https://user-images.githubusercontent.com/23737120/194904786-ea9c40a3-f6ac-4fe1-90ad-976e7b9e8f03.png">Catalog
- Support flash attention
- Support faster deformable attention
- Segmentation checkpoints
- Segmentation code
- Detection checkpoints
- Detection code
- Initialization
Awesome Competition Solutions with ViT-Adapter
1st Place Solution for the 5th LSVOS Challenge: Video Instance Segmentation
</br>
Tao Zhang, Xingye Tian, Yikang Zhou, Yuehua Wu, Shunping Ji, Cilin Yan, Xuebo Wang, Xin Tao, Yuanhui Zhang, Pengfei Wan
</br>
[Code]
 </br>
August 28, 2023
</br>
August 28, 2023
2nd place solution in Scene Understanding for Autonomous Drone Delivery (SUADD'23) competition
</br>
Mykola Lavreniuk, Nivedita Rufus, Unnikrishnan R Nair
</br>
[Code]
 </br>
July 18, 2023
</br>
July 18, 2023
Champion solution in Track 3 (3D Occupancy Prediction) of the CVPR 2023 Autonomous Driving Challenge
</br>
FB-OCC: 3D Occupancy Prediction based on Forward-Backward View Transformation
</br>
Zhiqi Li, Zhiding Yu, David Austin, Mingsheng Fang, Shiyi Lan, Jan Kautz, Jose M. Alvarez
</br>
[Code]
 </br>
June 26, 2023
</br>
June 26, 2023
3rd Place Solution for PVUW Challenge 2023: Video Panoptic Segmentation </br> Jinming Su, Wangwang Yang, Junfeng Luo, Xiaolin Wei </br> June 6, 2023
Champion solution in the Video Scene Parsing in the Wild Challenge at CVPR 2023 </br> Semantic Segmentation on VSPW Dataset through Contrastive Loss and Multi-dataset Training Approach </br> Min Yan, Qianxiong Ning, Qian Wang </br> June 3, 2023
2nd place in the Video Scene Parsing in the Wild Challenge at CVPR 2023 </br> Recyclable Semi-supervised Method Based on Multi-model Ensemble for Video Scene Parsing </br> Biao Wu, Shaoli Liu, Diankai Zhang, Chengjian Zheng, Si Gao, Xiaofeng Zhang, Ning Wang </br> June 2, 2023
Champion Solution for the WSDM2023 Toloka VQA Challenge
</br>
Shengyi Gao, Zhe Chen, Guo Chen, Wenhai Wang, Tong Lu
</br>
[Code]
</br>
January 9, 2023
1st Place Solutions for the UVO Challenge 2022 </br> Jiajun Zhang, Boyu Chen, Zhilong Ji, Jinfeng Bai, Zonghai Hu </br> October 9, 2022
Citation
If this work is helpful for your research, please consider citing the following BibTeX entry.
@article{chen2022vitadapter,
title={Vision Transformer Adapter for Dense Predictions},
author={Chen, Zhe and Duan, Yuchen and Wang, Wenhai and He, Junjun and Lu, Tong and Dai, Jifeng and Qiao, Yu},
journal={arXiv preprint arXiv:2205.08534},
year={2022}
}
License
This repository is released under the Apache 2.0 license as found in the LICENSE file.