Awesome
Deep-Blind-VSR
![]()
Paper | Supplemental Material | Discussion
Deep Blind Video Super-resolution
By Jinshan Pan, Haoran Bai, Jiangxin Dong, Jiawei Zhang, and Jinhui Tang
Updates
[2021-11-25] Metrics(PSNR/SSIM) calculating codes are available [Here]!
[2021-11-25] Inference logs are available!
[2021-11-25] Training code is available!
[2021-11-25] Testing code is available!
[2021-7-3] Supplemental Material is available!
[2021-7-3] Paper is available!
Abstract
Existing video super-resolution (SR) algorithms usually assume that the blur kernels in the degradation process are known and do not model the blur kernels in the restoration. However, this assumption does not hold for blind video SR and usually leads to over-smoothed super-resolved frames. In this paper, we propose an effective blind video SR algorithm based on deep convolutional neural networks (CNNs). Our algorithm first estimates blur kernels from low-resolution (LR) input videos. Then, with the estimated blur kernels, we develop an effective image deconvolution method based on the image formation model of blind video SR to generate intermediate latent frames so that sharp image contents can be restored well. To effectively explore the information from adjacent frames, we estimate the motion fields from LR input videos, extract features from LR videos by a feature extraction network, and warp the extracted features from LR inputs based on the motion fields. Moreover, we develop an effective sharp feature exploration method which first extracts sharp features from restored intermediate latent frames and then uses a transformation operation based on the extracted sharp features and warped features from LR inputs to generate better features for HR video restoration. We formulate the proposed algorithm into an end-to-end trainable framework and show that it performs favorably against state-of-the-art methods.
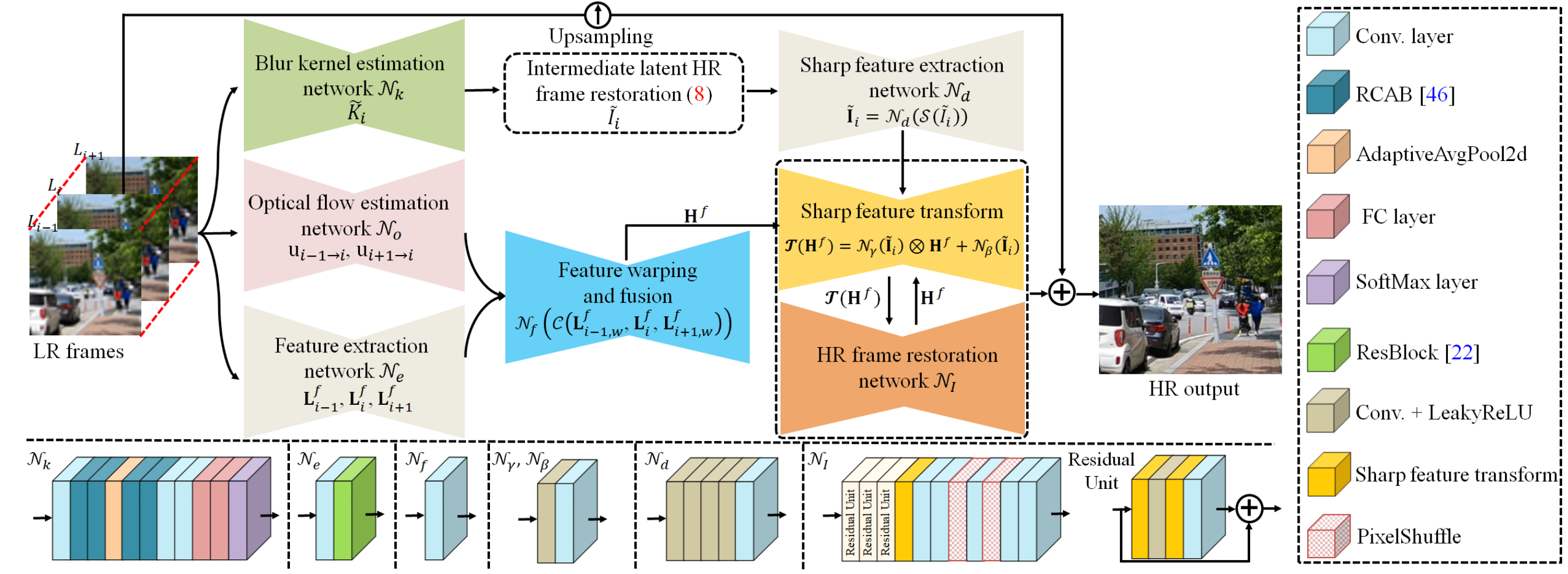
More detailed analysis and experimental results are included in [Paper] and [Supplemental Material].
Dependencies
- We use the implementation of PWC-Net by [sniklaus/pytorch-pwc]
- Linux (Tested on Ubuntu 18.04)
- Python 3 (Recommend to use Anaconda)
- PyTorch 0.4.1:
conda install pytorch=0.4.1 torchvision cudatoolkit=9.2 -c pytorch - numpy:
conda install numpy - matplotlib:
conda install matplotlib - opencv:
conda install opencv - imageio:
conda install imageio - skimage:
conda install scikit-image - tqdm:
conda install tqdm - cupy:
conda install -c anaconda cupy
Get Started
Download
- Pretrained models and Datasets can be downloaded from [Here].
- If you have downloaded the pretrained models,please put them to './pretrain_models'.
- If you have downloaded the datasets,please put them to './dataset'.
Dataset Organization Form
If you prepare your own dataset, please follow the following form:
|--dataset
|--sharp
|--video 1
|--frame 1
|--frame 2
:
|--video 2
:
|--video n
|--blurdown_x4
|--video 1
|--frame 1
|--frame 2
:
|--video 2
:
|--video n
Training
- Download the PWC-Net pretrained model from [Here].
- Download training dataset from [Here], or prepare your own dataset like above form.
- Run the following commands to pretrain the Kernel-Net:
cd ./code
python main.py --template KernelPredict
- After Kernel-Net pretraining is done, put the trained model to './pretrain_models' and name it as 'kernel_x4.pt'.
- Run the following commands to train the Video SR model:
python main.py --template VideoSR
Testing
Quick Test
- Download the pretrained models from [Here].
- Download the testing dataset from [Here].
- Run the following commands:
cd ./code
python inference.py --quick_test Gaussian_REDS4
# --quick_test: the results in Paper you want to reproduce, optional: Gaussian_REDS4, Gaussian_Vid4, Gaussian_SPMCS, NonGaussian_REDS4, NonGaussian_REDS4_L
- The SR result will be in './infer_results'.
Test Your Own Dataset
- Download the pretrained models from [Here].
- Organize your dataset like the above form.
- Run the following commands:
cd ./code
python inference.py --input_path path/to/LR/videos --gt_path path/to/GT/videos --model_path path/to/pretrained/model
# --input_path: the path of the LR videos in your dataset.
# --gt_path: the path of the GT videos in your dataset.
# --model_path: the path of the downloaded pretrained model.
- The SR result will be in './infer_results'.
Citation
@inproceedings{pan2021deep,
title = {Deep blind video super-resolution},
author = {Pan, Jinshan and Bai, Haoran and Dong, Jiangxin and Zhang, Jiawei and Tang, Jinhui},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages = {4811--4820},
year = {2021}
}