Awesome
Curvature
Find roads that are the most curved or twisty based on Open Street Map (OSM) data.
The goal of this program is to help those who enjoy twisty roads (such as motorcycle or driving enthusiasts) to find promising roads that are not well known. It works by calculating a synthetic "curvature" parameter for each road segment (known as a "way" in OSM parlance) that represents how twisty that segment is. These twisty segments can then be output as KML files that can be viewed in Google Earth or viewed in tabular form.
Project website and downloads: roadcurvature.com
About the "curvature" parameter:
The "curvature" of a way is determined by iterating over every set of three points in the line. Each set of three points form a triangle and that triangle has a circumcircle whose radius corresponds to the radius of the curve for that set. Since every line segment (between two points) is part of two separate triangles, the radius of the curve at that segment is considered to be the smaller, larger, or average of the radii for its member sets. Now that we have a curve radius for each segment we can categorize each segment into ranges of radii from very tight (short radius turn) to very broad or straight (long radius turn). Once each segment is categorized its length can be multiplied by a weight to increase the influence of the most curvy segments. By default a weight of 0 is given for straight segments, 1 for broad curves, and up to 2 for the tightest curves. The sum of all of the weighted lengths gives us a number for the curvature of the whole line that corresponds proportionally to the distance (in meters) that you will be in a turn.*
* If all weights are 1 then the curvature parameter will be exactly the distance in turns. The goal of this project however is to prefer tighter turns, so sharp corners are given an increased weight.
About & License
Author: Adam Franco
https://github.com/adamfranco/curvature
roadcurvature.com
Copyright 2012 Adam Franco
License: GNU General Public License Version 3 or later
Rendered Data
Rendered curvature files generated with this program can be dowloaded from kml.roadcurvature.com. Files are available for the entire world and are automatically updated approximately every two weeks.
Examples
Below are links to some example KML files generated with Curvature. Additional files can be found at kml.roadcurvature.com/.
-
Pre-processing the vermont-latest.osm.pbf file.
bin/curvature-collect -v --highway_types 'motorway,trunk,primary,secondary,tertiary,unclassified,residential,service,motorway_link,trunk_link,primary_link,secondary_link,service' vermont-latest.osm.pbf \ | bin/curvature-collect $verbose $input_file \ | bin/curvature-pp filter_out_ways_with_tag --tag surface --values 'unpaved,dirt,gravel,fine_gravel,sand,grass,ground,pebblestone,mud,clay,dirt/sand,soil' \ | bin/curvature-pp filter_out_ways_with_tag --tag service --values 'driveway,parking_aisle,drive-through,parking,bus,emergency_access' \ | bin/curvature-pp add_segments \ | bin/curvature-pp add_segment_length_and_radius \ | bin/curvature-pp add_segment_curvature \ | bin/curvature-pp filter_segment_deflections \ | bin/curvature-pp split_collections_on_straight_segments --length 2414 \ | bin/curvature-pp roll_up_length \ | bin/curvature-pp roll_up_curvature \ | bin/curvature-pp filter_collections_by_curvature --min 300 \ | bin/curvature-pp sort_collections_by_sum --key curvature --direction DESC \ > vermont.msgpack -
A basic KML file generated with a minimum curvature of 300 using the pre-processed vermont-latest.osm.pbf file (above).
This file includes all ways in the input file that have a curvature value greater than 300 and are not marked as unpaved. As mentioned above, a curvature of 300 this means that these ways have at least 150 meters of tight curves with a radius of less than 30 meters, 300 meters of gentle curves with a radius less than 175 meters, or a combination thereof.
In practice, a curvature of 300 is useful for finding roads that might be a bit fun in a sea of otherwise bland options. While more curvy roads will also be included, roads in the 300-600 range tend to be pleasant rather than exciting.
cat vermont.msgpack \ | bin/curvature-pp filter_collections_by_curvature --min 300 \ | bin/curvature-output-kml --min_curvature 300 --max_curvature 20000 \ > vermont.c_300.kmlAn additional note: Vermont has approximately 8,000 miles of dirt roads and only 6,000 miles of paved roads. At the time of this writing most of the dirt roads were not tagged as such in Open Street Map, leading to the inclusion of many dirt roads in the KML file above. I have tagged many of the roads in my region with appropriate 'surface' tags, but there is more to be done. Head to openstreetmap.org and help tag roads with appropriate surfaces so that we can better filter our results.
-
A basic KML file generated with a minimum curvature of 1000 using the pre-processed vermont-latest.osm.pbf file (above).
This file includes all ways in the input file that have a curvature value greater than 1000 and are not marked as unpaved. As mentioned above, a curvature of 1000 this means that these ways have at least 500 meters of tight curves with a radius of less than 30 meters, 1000 meters of gentle curves with a radius less than 175 meters, or a combination thereof.
In practice a minimum curvature of 1000 is useful for finding the best roads in a region. There will be many roads that are quite fun but don't quite make the cut, but all of the roads listed will be very curvy.
cat vermont.msgpack \ | bin/curvature-pp filter_collections_by_curvature --min 1000 \ | bin/curvature-output-kml --min_curvature 1000 --max_curvature 20000 \ > vermont.c_1000.kml -
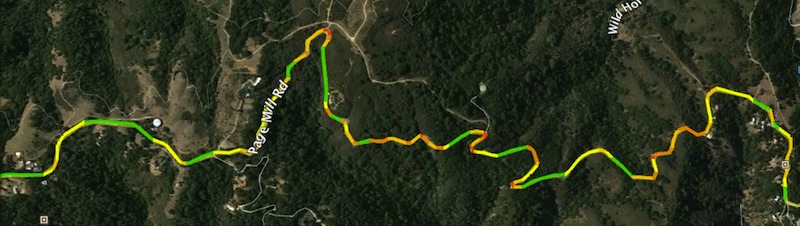
Multi-colored KML files generated with a minimum curvature of 1000 using the pre-processed vermont-latest.osm.pbf file (above).
This file colors the ways listed in the second example based on curve radius. Zoom on corners to see the shading. Green segments do not contribute to the 'curvature' value while yellow, orange, and red segments do.
cat vermont.msgpack \ | bin/curvature-pp filter_collections_by_curvature --min 1000 \ | bin/curvature-output-kml-curve-radius \ > vermont.c_1000.curves.kml -
All of the commands above, combined into a single script
processing_chains/adams_defaults.sh:mv vermont-latest.osm.pbf vermont.osm.pbf processing_chains/adams_defaults.sh -v vermont.osm.pbf -
More examples can be seen at roadcurvature.com
Installation
Prerequisites
Python This is a Python script, therefore you need a functional Python 3 or later environment on your computer. This program has been tested on Python 3.5. See http://python.org/
Boost.Python Boost is system for providing C++ libraries (like libosmium) to Python
libosmium http://osmcode.org/libosmium/manual.html#building-libosmium
The sparsehash package will also be needed for the following to work.
wget https://github.com/osmcode/libosmium/archive/v2.10.2.tar.gz
tar xzf v2.10.2.tar.gz
cd libosmium-2.10.2/
mkdir build
cd build
cmake -g INSTALL_PROTOZERO ../
make && make install
pyosmium
After libosmium is available on your system, you should be able to use pip to
install the python osmium bindings.
pip install osmium
Issues: On my system (OS X 10.10.5 with most packages installed via MacPorts) I
had to take two additional steps to fix errors in building osmium with pip.
-
MacPorts put the boost.python installation in
/opt/local/include/boost/while osmium is looking for it in/opt/local/lib/boost/. Making a symbolic link solved this.cd /opt/local/lib ln -s ../include/boost boost -
I was seeing the following error:
In file included from lib/osmium.cc:5: In file included from /usr/local/include/osmium/area/assembler.hpp:62: /usr/local/include/osmium/tags/filter.hpp:41:10: fatal error: 'boost/iterator/filter_iterator.hpp' file not found #include <boost/iterator/filter_iterator.hpp>
I fixed this by ensuring that a BOOST_PREFIX variable was in my shell environment
before running pip:
export BOOST_PREFIX=/opt/local/
pip install osmium
msgpack
curvature makes use of msgpack which you can find at
python.org and installed
with pip or easy_install:
pip install msgpack-python
Optional dependencies
psycopg2 Needed if you want to load Curvature output into a PostGIS database.
Curvature Installation
Once your Python environment set up and the imposm.parser and msgpack-python modules are installed, just download
Curvature and run one of the provided processing chains:
git clone https://github.com/adamfranco/curvature.git
cd curvature
./processing_chains/adams_default.sh -h
Running tests
You can run the unit tests for curvature by running the following from the project directory:
py.test
Usage
Curvature works with Open Street Map (OSM) XML data files. While you can export these from a small area directly from openstreetmap.org , you are limited to a small area with a limited number of points so that you don't overwhelm the OSM system. A better alternative is to download daily exports of OSM data for your region from Planet.osm.
This script was developed using downloads of the US state OSM data provided at: download.geofabrik.de/openstreetmap
Once you have downloaded a .osm or .osm.pbf file that you wish to work with, you can run one of the the predefined processing changes with their default options:
./processing_chains/adams_defaults.sh -v vermont.osm.pbf
This will generate a set of compressed KMZ files that includes lines for all of the matched segments.
Use
./processing_chains/adams_defaults.sh -h
for more options.
Basic KML Output
Open the KML files in Google Earth. GoogleEarth can become overloaded with giant KML files, so the default mode is to generate a single placemark for each matching way that has a single-color line-string. On a reasonably modern computer even large files such as roads with curvature greater than 300 in California can be rendered when formatted in this way.
Colored-curves KML Output
Additionally, this script allows rendering of ways as a sequence of segments color-coded based on the curvature of each segment. These 'colorized' KML files provide a neat look at the radius of turns and are especially useful when tuning the radii and weights for each level to adjust which ways are matched. The color-coding is as follows: straight segments are green and the four levels of curves are color-coded from yellow to red with decreasing turn radii.
Unfortunately, these multi-colored ways are significantly more difficult for GoogleEarth to render than the longer single-color segments, so try to avoid files larger than about 40MB. Google Earth can easily handle smaller areas like Vermont with a curvature of 300, but larger regions (like California) may need to be trimmed down with a bounding box if you wish to make usable multicolor KML files.
Building your own processing scripts
The processing-chains in curvature/processing_chains/ are just a few examples of ways to use this
program. You can easily pipe output from one filter to the next to modify the data stream to your liking.
The easiest way to create your own processing chain is to copy adams_default.sh and edit the
sequence of steps to filter more or fewer road segments.
Collecting
Usually, any processing-chain will start with a call to the bin/curvature-collect script to take
the input .osm.pbf data and convert it to a stream of collections. Each collection is an
ordered sequence of one or more Open Street Map ways. Where possible, ways are joined end to end
into long sequences that all share the same name tag or ref tag (used for routes, like US 7).
This collecting process gives us the most complete linear "roads" it is possible to extract from the
data and allows us to look at a long shape of a road as a unit even if it is broken up into many
different ways to account for changing speed-limit tags, bridge tags, etc.
The input of the collecting process is an osm-xml file or an .osm.pbf file. The output is
a MessagePack stream written to STDOUT, which can then either be piped to another script or
written to a file.
Example, writing to a file:
bin/curvature-collect -v ~/Downloads/vermont.osm.pbf > vermont.msgpack
Example, piping to other scripts:
bin/curvature-collect -v ~/Downloads/vermont.osm.pbf | bin/msgpack-reader
Note the binary MessagePack format is very fast to read/write, but it is not particularly space-efficient. When writing to disk (instead of piping between scripts) it may be faster (and is definitely more space-efficient) to pipe the MessagePack data through GZIP:
bin/curvature-collect -v ~/Downloads/vermont.osm.pbf | gzip > vermont.msgpack.gz
cat vermont.msgpack.gz | gunzip | bin/msgpack-reader | head -n 50
Reading the MessagePack stream
When developing processing-chains, it is sometimes helpful to get a human-readable
view of the output at each stage. The bin/msgpack-reader program takes a MessagePack
stream on STDIN and writes a human-readable version of the data on STDOUT. Example:
bin/curvature-collect -v ~/Downloads/vermont.osm.pbf | bin/msgpack-reader | head -n 50
{ 'join_type': 'none',
'ways': [ { 'coords': [ [43.6371221, -72.33376860000001],
[43.6372364, -72.33391470000001],
[43.6375166, -72.33431750000001],
[43.6376378, -72.33447530000001],
[43.6378658, -72.3347415],
[43.6379279, -72.33480050000001],
[43.6380124, -72.33487350000001],
[43.6381617, -72.33499220000002],
[43.6382817, -72.33507130000001],
[43.6384463, -72.33515430000001],
[43.638724499999995, -72.33528830000002],
[43.639139199999995, -72.33549630000002],
[43.63962419999999, -72.33573870000002],
[43.640433299999984, -72.33617290000034],
[43.64048309999998, -72.33620290000033],
[43.640566299999996, -72.33625740000002]],
'id': 4217987,
'refs': [ 25060849,
25060861,
25060855,
25060841,
25060845,
25060835,
25062311,
25062317,
25062321,
25062326,
25062331,
25062337,
25062343,
652095695,
652095698,
25062350],
'tags': { 'destination:ref': 'I 91 North',
'highway': 'motorway_link',
'oneway': 'yes',
'surface': 'asphalt',
'tiger:cfcc': 'A63',
'tiger:county': 'Windsor, VT'}}]}
The head post processor is also helpful for viewing output as it will truncate
the output to just the first n collections (whereas the POSIX head command
works on number of lines).
Example:
bin/curvature-collect -v ~/Downloads/vermont.osm.pbf | bin/curvature-pp head -n 2 | bin/msgpack-reader
Calculating
The filter, splitting, sorting, and modifying operations are handled by a set of post processors
found at curvature/cuvature/post_processors/. Post processors are called by piping the
MessagePack stream to the bin/curvature-pp program with the post-processor desired as
the first argument.
The add_segments, add_segment_length_and_radius, add_segment_curvature, and
filter_segment_deflections post processors are generally used together to
analyze the geometry of each way.
-
add_segmentsconverts the sequence of coordinates that make up a way into pairs of coordinates that make up a line-segment. This new segment object in the data stream can then have additional calculations performed on it. -
add_segment_length_and_radiuscalculates the length of the segment as well as the curve-radius for that segment. -
add_segment_curvaturemultiplies a radius-classified weight by the segment-length to give us the cuvature value for the segment. -
filter_segment_deflectionslooks for jiggles in otherwise straight ways and filters out the curvature value for these segments to prevent noisy data from being interpreted the same as hairpin curves.
Other calculating post-processors are roll_up_length, roll_up_curvature, and
remove_way_properties.
Filtering and splitting
The filter_xxxx_ways_xxxx, filter_collections_by_xxxx and split_collections_on_xxxx
post processors allow you to remove collections (or portions of collections) that
don't meet your criteria.
For example, you may only want to include roads that are paved, so you might use the
filter_out_ways_with_tag post processor to remove ways that have surface tags that
indicate an unpaved road-surface.
cat vermont.msgpack | bin/curvature-pp filter_out_ways_with_tag --tag surface --values 'unpaved,dirt,gravel,fine_gravel,sand,grass,ground,pebblestone,mud,clay,dirt/sand,soil' | bin/msgpack-reader
You can also filter on complex boolean expressions using the filter_out_ways post processor, such
as all of the driveways in the US that were incorrectly imported as unnamed 'residential' ways:
cat vermont.msgpack | bin/curvature-pp filter_out_ways --match 'And(TagEmpty("name"), TagEmpty("ref"), TagEquals("highway", "residential"), TagEquals("tiger:reviewed", "no"))' | bin/msgpack-reader
The filter_xxxx_ways_xxxx and split_collections_on_xxxx post processors will break
apart collections into multiple resulting collections, so if you ran the above example
on an input file that had a road that started paved, became gravel, then became paved again,
the output would have 2 collections (one for each paved portion) and the gravel portion would be dropped.
The filter_collections_by_xxxx post processors simply drop entire collections without
modifying them. For example, you could exclude road-sections shorter than 1 mile (1609 meters) with:
cat vermont.msgpack | bin/curvature-pp filter_collections_by_length --min 1609 | bin/msgpack-reader
Output
After you have massaged the data to your liking, you can then pipe the MessagePack stream
to one of the output programs like bin/curvature-output-kml or bin/curvature-output-tab
to write a data-file. Example:
cat vermont.msgpack | curvature-output-kml > doc.kml
GeoJSON Output
Use the curvature-output-geojson script to export results as a GeoJSON file that
can be used in many GIS programs.
cat vermont.msgpack | curvature-output-geojson > veromnt.geojson
PostGIS Output
In addition to writing KML and text files, Curvature can also insert each segment into a PostGIS database.
You will need a PostGIS database server and account credentials to access it.
The database schema expected can be found in output-master/curvature.sql.
Once your database is set up and the schema created you can insert batches of curvature
data using the curvature-output-postgis output. For example:
cat vermont.msgpack | bin/curvature-output-postgis -v \
--source north_america/us/vermont --clear \
--database curvature --user curvatureuser --password curvaturepassword
The --source option provides a shared key for this working data set to allow you
to build up and refresh a world-wide database one region at a time. The --clear
option tells the output to clear existing values associated with the source before
inserting the new ones. --host and --port options are also available.
Change Log
2.5.0 - 2021-03-24
- Postgres output now only stores highway, surface, smoothness, and maxspeed at the way-level rather than summed at the segment level. This dramatically reduces the number of tags stored in the database. Way-level details can also be more easily summed with statistics client-side.
- In addition to
ref, way-joining now will useofficial_ref,admin_ref,highway_ref, orhighway_authority_refas the joining key. This fixes #65. Thanks to Pink Duck for reporting this issue affecting UK county roads.
Upgrade note: This release requires updating the PostGIS database structure
to remove the fk_highway, fk_surface, fk_maxspeed, and fk_smoothness columns
and their associated constraints from the curvature_segments table.
See output-master/curvature.sql for the new schema.
2.4.0 - 2021-03-17
- Add support for storing maxspeed tags in postgres output.
- Add support for storing smoothness tags in postgres output.
Upgrade note: This release requires updating the PostGIS database structure to support new fk_maxspeed and fk_smoothness columns.
Release contributors: Adam Franco
2.3.0 - 2020-12-02
- PostGIS output can now record the extent affected by updates.
- Now squashing curvature values for ways with certain tags (e.g. junction roundabout), near changes in oneway tags (to avoid "chained" modeling of roads from registering as curvy), and near nodes with certain tags (e.g. crossings, stop/yield signs, traffic signals, traffic-calming, etc)
Release contributors: Adam Franco
2.2.1 - 2020-10-08
- Many fixes to get tests working again. (Thanks, Daryl Matuszak)
- updates args to unpacker to comply with msgpack 1.0
- Use '{}'.format(x) instead of f'{x}' for compat. with Python 3.5 & 3.6.
Release contributors: Adam Franco, Daryl Matuszak
2.2.0 - 2017-02-06
- Add PostGIS output
- Fix string replace syntax in Python 3.5.
- Fix edge case where highway & surface tags contain non-ascii characters.
- Add post processors to setup.py
- Fix type error in Python 3.5. Wouldn't allow comparing
None > 0. - Update the tab-delimited output to work again after much neglect.
- Refactored AddSegmentLengthAndRadius to make the code more readable.
- Skip nodes with invalid location rather than failing.
Release contributors: Adam Franco, Fonsan
2.1.0 - 2016-12-07
Updated from Python 2.7 to Python 3.5. Also removed the dependency on the Python27-only imposom.parser library in favor of the well-maintained Osmium PBF parsing library. Python 2.7 is no longer supported by Curvature.
Release contributors: Adam Franco, Fonsan
2.0.0 - 2016-11-04
Curvature 2 is a complete rewrite of the program with a new stream-based processing model. Curvature 1 was a single large Python program with many, many options. To add flexibility, Curvature 2 is a collection of very small programs that each can modify the data-stream in a limited way. These small programs can then be linked together in complex processing chains that can be easily customized or reordered for performance or to achieve different results.
The piped MessagePack streams are the recommended way to build processing chains using this release of Curvature. Additional pure-Python processing-chains are included as experimental examples, however the API for configuring these may change in future releases.
For end-users, Curvature 2 now has improved KML output that distinguishes between
primary/secondary/motorway/known-paved roads and roads whose surface is unknown.
Tertiary/residential/unclassified roads without a surface tag will now render as
thinner and less opaque. These might be excellent roads, but if you like to stick to
asphalt, you might need to do some additional checking for these roads.