Awesome
<!-- vim-markdown-toc GFM --> <!-- vim-markdown-toc -->introduction
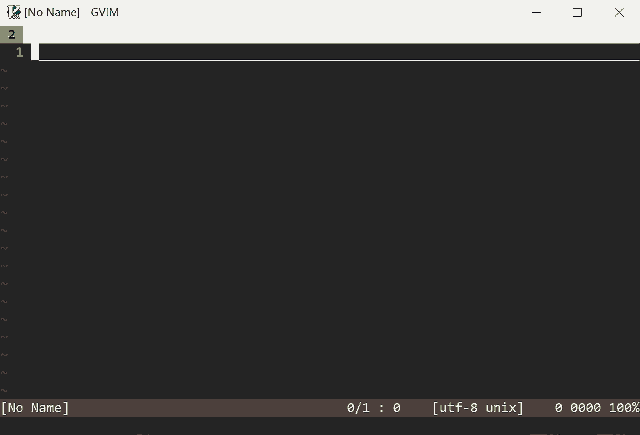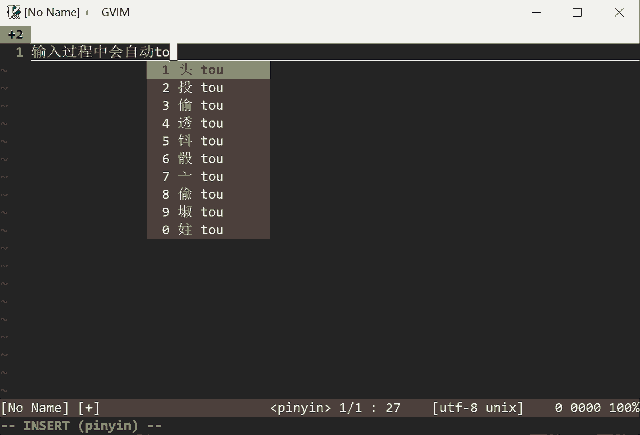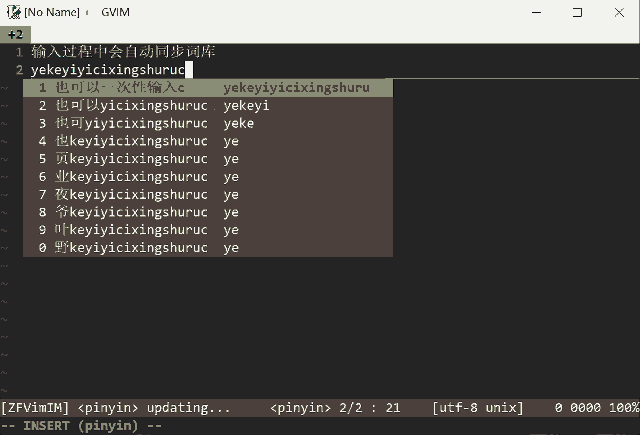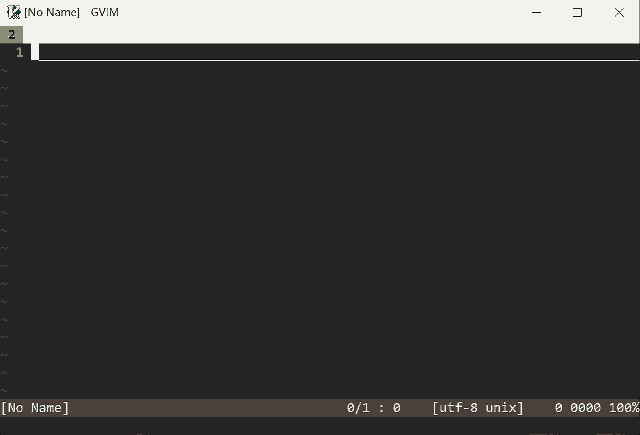
Input Method by pure vim script, inspired by VimIM
Outstanding features / why another remake:
- more friendly long sentence match and better predict logic
- predict from multiple db without switching dbs
- auto create user word and re-order word priority according to your input history
- cloud input, auto pull and push your db file from/to Github
- fetch words from 3rd openapi, asynchronously
- solve many VimIM's issues:
- better txt db load performance if
executable('python') - auto disable and re-enable complete engines when using input method
- sync input method state acrossing buffers
- better txt db load performance if
Why VimIM? Why not system IME?
- it's a pain to input CJK in ssh env
- I love
inoremap jk <esc>:)
if you like my work, check here for a list of my vim plugins, or buy me a coffee
how to use
minimal config (local db)
-
recommend env:
- (optional)
vim8withjoborneovim, for better db load performance - (optional)
executable('python')orexecutable('python3'), for better db load performance
- (optional)
-
use Vundle or any other plugin manager you like to install
Plugin 'ZSaberLv0/ZFVimIM' Plugin 'ZSaberLv0/ZFVimJob' " optional, for better db load performance -
prepare your db files, you may copy the txt db files from db samples to any location
-
config
function! s:myLocalDb() let db = ZFVimIM_dbInit({ \ 'name' : 'YourDb', \ }) call ZFVimIM_cloudRegister({ \ 'mode' : 'local', \ 'dbId' : db['dbId'], \ 'repoPath' : '/path/to/repo', " path to the db \ 'dbFile' : '/YourDbFile', " db file, relative to repoPath \ 'dbCountFile' : '/YourDbCountFile', " optional, db count file, relative to repoPath \ }) endfunction if exists('*ZFVimIME_initFlag') && ZFVimIME_initFlag() call s:myLocalDb() else autocmd User ZFVimIM_event_OnDbInit call s:myLocalDb() endif
recommend config (cloud db)
-
recommend env:
- (optional)
git, for db update - (optional)
vim8withjoborneovim, for better db load performance - (optional)
executable('python')orexecutable('python3'), for better db load performance
- (optional)
-
prepare your db repo according to db samples, or simply fork one of the db samples
-
go to access tokens to generate your Github access token, and make sure it has push permission to your db repo (check
repoinSelect scopes) -
config your access token according to your db repo, for example, for the db samples:
let g:zf_git_user_email='YourEmail' let g:zf_git_user_name='YourUserName' let g:zf_git_user_token='YourGithubAccessToken'please check the README of each db repo for detail
-
use Vundle or any other plugin manager you like to install
Plugin 'ZSaberLv0/ZFVimIM' Plugin 'ZSaberLv0/ZFVimJob' " optional, for better db load performance Plugin 'ZSaberLv0/ZFVimGitUtil' " optional, cleanup your db commit history when necessary Plugin 'YourUserName/ZFVimIM_pinyin_base' " your db repo Plugin 'ZSaberLv0/ZFVimIM_openapi' " optional, 3rd IME using Baidu
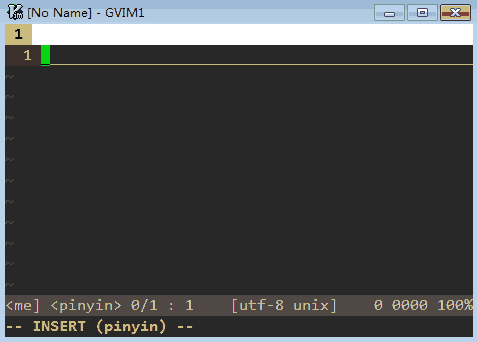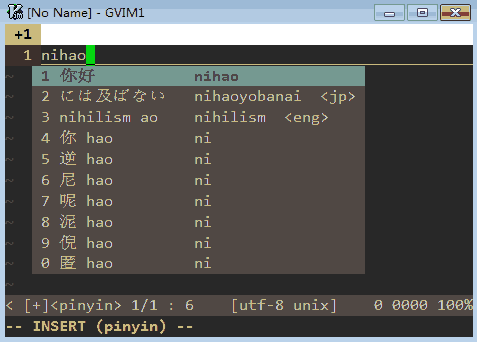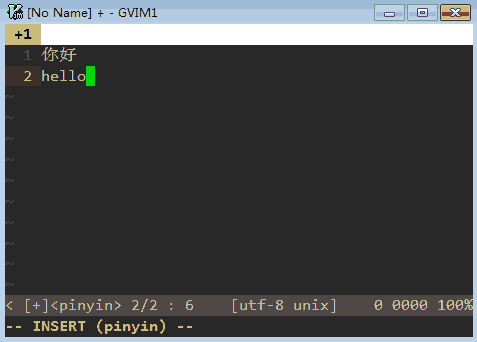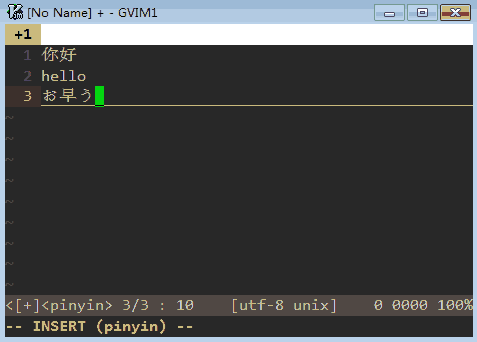
how to use
- use
;;to toggle input method, and;:to switch db - scroll page by
-or= - input and choose word by
<space>or0~9 - choose head or tail word by
[or] - your input history would be recorded locally or
push to github automatically,
you may use
;,or:IMAddto add user word,;.or:IMRemoveto remove user word
some tips
-
you may want to add a IME status tip to your
:h 'statusline'let &statusline='%{ZFVimIME_IMEStatusline()}'.&statusline -
if it's hard to support async mode, you may also:
- pull and push manually by
:call ZFVimIM_download()and:call ZFVimIM_upload() - automatically ask you to input git info to push before exit vim,
by
let g:ZFVimIM_cloudSync_enable=1
- pull and push manually by
-
since db files are pretty personal, the default db only contains single word, words would be created during your usage, if you prefer other choices, see db samples
-
your db repo may contain many commits after long time usage, which may cause a huge
.gitdir, it's recommended to clean up it occasionally, by:- delete and re-create the repo
- if you have
push --forcepermission, search and see theg:ZFVimIM_cloudAsync_autoCleanupdetail config below
detailed
configs
-
let g:ZFVimIM_autoAddWordLen=3*4when you choose word and the word's byte length less than this value, we would add the word to db file automatically (ignored when
g:ZFVimIM_autoAddWordCheckeris set) -
let g:ZFVimIM_autoAddWordChecker=[]list of function to check whether need to add user word
function! MyChecker(userWord) let needAdd = ... return needAdd endfunction let g:ZFVimIM_autoAddWordChecker=[function('MyChecker')]when any of checker returned
0, we won't add user word -
let g:ZFVimIM_symbolMap = {}used to transform unicode symbols during input
it's empty by default, typical config for Chinese:
let g:ZFVimIM_symbolMap = { \ ' ' : [''], \ '`' : ['·'], \ '!' : ['!'], \ '$' : ['¥'], \ '^' : ['……'], \ '-' : [''], \ '_' : ['——'], \ '(' : ['('], \ ')' : [')'], \ '[' : ['【'], \ ']' : ['】'], \ '<' : ['《'], \ '>' : ['》'], \ '\' : ['、'], \ '/' : ['、'], \ ';' : [';'], \ ':' : [':'], \ ',' : [','], \ '.' : ['。'], \ '?' : ['?'], \ "'" : ['‘', '’'], \ '"' : ['“', '”'], \ '0' : [''], \ '1' : [''], \ '2' : [''], \ '3' : [''], \ '4' : [''], \ '5' : [''], \ '6' : [''], \ '7' : [''], \ '8' : [''], \ '9' : [''], \ }-
if you want to change this setting at runtime, you should use
call ZFVimIME_stop() | call ZFVimIME_start()to restart to take effect, or, add autocmd toZFVimIM_event_OnEnableto setup this value -
it's recommended to add these configs to make vim recognize chinese chars
set encoding=utf-8 set fileencoding=utf-8 set fileencodings=utf-8,ucs-bom,chinese
-
-
keymaps:
let g:ZFVimIM_key_pageUp = ['-']let g:ZFVimIM_key_pageDown = ['=']let g:ZFVimIM_key_chooseL = ['[']let g:ZFVimIM_key_chooseR = [']']
-
let g:ZFVimIM_showKeyHint = 16whether show key hint after word
0: do not show1: show without length limit>1: show with specified length limit
-
let g:ZFVimIM_cachePath=$HOME.'/.vim_cache/ZFVimIM'cache path for temp files
-
let g:ZFVimIM_cloudAsync_outputTo={...}for async cloud input, output log to where (see ZFJobOutput), default:
let g:ZFVimIM_cloudAsync_outputTo = { \ 'outputType' : 'statusline', \ 'outputId' : 'ZFVimIM_cloud_async', \ } -
let g:ZFVimIM_cloudAsync_autoCleanup=30your db repo may contain many commits after long time usage, we would try to remove all history commits if:
-
have these optional plugins installed:
Plugin 'ZSaberLv0/ZFVimJob' Plugin 'ZSaberLv0/ZFVimGitUtil' -
ZFJobAvailable()returned 1 (i.e. async mode available)- we have bundled a default fallback for job,
which may cause some unexpected lag,
you may enable it by
let g:ZFVimIM_cloudAsync_jobFallback = 1
- we have bundled a default fallback for job,
which may cause some unexpected lag,
you may enable it by
-
g:ZFVimIM_cloudAsync_autoCleanupgreater than 0 -
your
git rev-list --count HEADexceedsg:ZFVimIM_cloudAsync_autoCleanup
NOTE:
- this require you have
git push --forcepermission, if not, please disable this feature, otherwise your commits may lost occasionally (each time when commits exceedsg:ZFVimIM_cloudAsync_autoCleanup)
-
-
let g:ZFVimIM_cloudAsync_autoInit=1for async cloud input only, when on, we would load db when
VimEnter, to reduce the time you firstZFVimIME_start()
functions
-
ZFVimIME_start()ZFVimIME_stop()ZFVimIME_toggle()ZFVimIME_next()start or stop, must called during Insert Mode, as
<c-r>=ZFVimIME_start()<cr> -
:IMAdd word keyorZFVimIM_wordAdd(db, word, key)manually add word
-
:IMRemove word [key]orZFVimIM_wordRemove(db, word [, key])manually remove word
-
:IMReorder word [key]orZFVimIM_wordReorder(db, word [, key])manually reorder word priority, by reducing it's input history count to a proper value
-
ZFVimIM_complete(key [, option])-
option
{ 'sentence' : '0/1, default to g:ZFVimIM_sentence', 'crossDb' : 'maxNum, default to g:ZFVimIM_crossDbLimit', 'predict' : 'maxNum, default to g:ZFVimIM_predictLimit', 'match' : '', // > 0 : limit to this num, allow sub match // = 0 : disable match // < 0 : limit to (0-match) num, disallow sub match // default to g:ZFVimIM_matchLimit 'db' : {...}, // which db to use, empty for current } -
return
[ { 'dbId' : 'match from which db', 'len' : 'match count in key', 'key' : 'matched full key', 'word' : 'matched word', 'type' : 'type of completion: sentence/match/predict/subMatchLongest/subMatch', 'sentenceList' : [ // (optional) for sentence type only, list of word that complete as sentence { 'key' : '', 'word' : '', }, ], }, ... ]
note, you may supply your own function named
ZFVimIM_completeto override the default one, and useZFVimIM_completeDefault(key, option)to achieve custom IME complete -
functions (for db repo)
-
ZFVimIM_dbInit(option)to register a db, option:
{ 'name' : '(required) name of your db', 'priority' : '(optional) priority of the db, smaller value has higher priority, 100 by default', 'switchable' : '(optional) 1 by default, when off, won't be enabled by ZFVimIME_keymap_next_n() series', 'editable' : '(optional) 1 by default, when off, no dbEdit would applied', 'crossable' : '(optional) g:ZFVimIM_crossable by default, whether to show result when inputing in other db', // 0 : disable // 1 : show only when full match // 2 : show and allow predict // 3 : show and allow predict and sub match 'crossDbLimit' : '(optional) g:ZFVimIM_crossDbLimit by default, when crossable, limit max result to this num', 'dbCallback' : '(optional) func(key, option), see ZFVimIM_complete', // when dbCallback supplied, words would be fetched from this callback instead 'menuLabel' : '(optional) string or function(item), when not empty, show label after key hint', // when not set, or set to number `0`, we would show db name if it's completed from crossDb 'implData' : { // extra data for impl }, }return db object which would stored in
g:ZFVimIM_db -
ZFVimIM_cloudRegister(cloudOption)register cloud info, when registered, we would try to pull/push from/to remote repo
cloudOption:
{ 'mode' : '(optional) git/local', 'cloudInitMode' : '(optional) forceAsync/forceSync/preferAsync/preferSync', 'dbId' : '(required) dbId generated by ZFVimIM_dbInit()' 'repoPath' : '(required) git/local repo path', 'dbFile' : '(required) db file path relative to repoPath, must start with /', 'dbCountFile' : '(optional) db count file path relative to repoPath, must start with /', 'gitUserEmail' : '(optional) git user email', 'gitUserName' : '(optional) git user name', 'gitUserToken' : '(optional) git access token or password', }
make your own db
-
supply your db file with this format:
a 啊 阿 a 锕 ai 爱 唉 ohayou お早う おはようございます tang _(:з」∠)_ haha ^\ ^key can be
a-z, word can be any string (if word contain space, you may escape it by\)save it as
utf-8encoding -
format the db file to ensure it's valid
call ZFVimIM_dbNormalize('/path/to/dbFile')this may take a long time, but for only once
-
put the db file to your git repo, according to the db samples below
db samples
-
ZSaberLv0/ZFVimIM_openapi : pinyin repo using thirdparty's openapi, recommended to install as default, and it shows the way to achieve complex async db logic
-
ZSaberLv0/ZFVimIM_pinyin_base : base pinyin repo that only contain single word, recommended if you care about performance or want to create personal user word during usage
-
ZSaberLv0/ZFVimIM_wubi_base : wubi converted from ywvim, I'm not familiar with wubi, just put it here in case you want to try
-
ZSaberLv0/ZFVimIM_english_base : english repo that contain common words
-
ZSaberLv0/ZFVimIM_japanese_base : japanese repo that contain common words
-
ZSaberLv0/ZFVimIM_pinyin : pinyin repo which I personally used, update frequently
-
ZSaberLv0/ZFVimIM_pinyin_huge : huge pinyin repo that contains many words, it's converted from other IME and haven't been daily used, which may contain many useless words, I put it here just in case you prefer huge db or want to test huge db's performance
FAQ
-
Q: strange complete popup?
A: we use
omnifuncto achieve IM popup, which would conflict with most of complete engines, by default, we would automatically disable complete engines when IM started, if your other plugins conflict with IM, you may disable it manually (see this)also, if any strange behaviors occurred,
:verbose set omnifunc?to check whether it's changed by other plugins -
Q: meet some weird problem, how to check log?
A: use
:IMCloudLogto check first, if not enough:- put this in your vimrc:
let g:ZFJobVerboseLogEnable = 1 - restart vim and reproduce your problem
- write log file by:
:call writefile(g:ZFJobVerboseLog, 'log.txt')
WARNING : the verbose log may contain your git access token or password, please verify before posting the log file to public
- put this in your vimrc:
-
Q: How to use in
Command-line(search or command) ?A: ZFVimIM can be used inside
command-line-window, you may:-
(in normal mode) use
q:orq/to entercommand-line-window -
(inside command line) use these keymaps to edit in
command-line-window:function! ZF_Setting_cmdEdit() let cmdtype = getcmdtype() if cmdtype != ':' && cmdtype != '/' return '' endif call feedkeys("\<c-c>q" . cmdtype . 'k0' . (getcmdpos() - 1) . 'li', 'nt') return '' endfunction cnoremap <silent><expr> ;; ZF_Setting_cmdEdit()to use it: press
;;while editing inCommand-line
-
-
Q: How to use in
:terminal?A: since
terminaldoes not supportomnifunc, there's no direct way to support in ita workaround by
command-line-window:if has('terminal') || has('nvim') function! PassToTerm(text) let @t = a:text if has('nvim') call feedkeys('"tpa', 'nt') else call feedkeys("a\<c-w>\"t", 'nt') endif redraw! endfunction command! -nargs=* PassToTerm :call PassToTerm(<q-args>) tnoremap ;; <c-\><c-n>q:a:PassToTerm<space> endifto use it: press
;;while inside:terminalwindow'sInsert-mode -
Q: external db source?
A: the ZSaberLv0/ZFVimIM_openapi is a good example, which achieves:
- using external source to supply db contents
- async mode
-
Q: lazy db load?
A: you may manually use these methods to achieve lazy load:
- register:
ZFVimIM_dbInit(...): register a empty db that can be toggle byZFVimIME_keymap_toggle_n()orZFVimIME_keymap_next_n()
- db load:
ZFVimIM_cloudRegister(...): (recommended) register cloud setting, and would load db content when calledZFVimIM_dbLoad(...): to load actual db content, can be called separately for split db, new data would be merged to old datag:ZFVimIM_db: (not recommended) manually modify internal db data
- register:
-
Q: arrow keys not work?
A: see this
known issue
-
too slow
check first:
executable('python')orexecutable('python3')andZFVimJobis installed and available (you may check them bycall ZFVimIM_DEBUG_checkHealth()), without them, the pure vim script fallback is always very slow (about 2 seconds for 200KB db file)if your db file is very large, it's slow to save and load db even if
executable('python'), because reading and processing large files also takes a long timethis plugin is designed lightweight that can fallback to pure vimscript, so, there's no plan to completely move db data to python side (further more, async complete popup would break
:lmaplogic, and require features like LSP plugins, no plan to achieve this too)PS: you may want to check ZSaberLv0/ZFVimIM_openapi for how to use external tool to supply db contents
if you want to benchmark:
let g:ZFVimIM_DEBUG_profile = 1- input freely
call ZFVimIM_DEBUG_profileInfo()to check which step consumed most time
if issue still occurs, please supply log file before opening issue:
call ZFVimIM_DEBUG_start('/path/to/log')- input freely
call ZFVimIM_DEBUG_stop()- open issue and supply the log file
-
use with LSP plugins
it's possible, but it's a better design to make a external executable for LSP plugins, not some vimscript like this plugin, so, no plan on this
if you really want to hack, there's two idea:
- use
ZFVimIM_complete()to get word completion, and supply things likeomnifuncfor LSP plugins - use python or other tools to parse db files and supply LSP plugins
- use
-
can not use in
input()unfortunately, I've no idea how to make
lmapwork ininput(), and there's no plan to make complexcmapto achieve thisof course, if you have better solution, PR is always welcomed