Awesome
Revisiting the "Video" in Video-Language Understanding
Welcome to the official repo for our paper:
Revisiting the "Video" in Video-Language Understanding<br/> <b>CVPR 2022 (Oral)</b><br/> <b>Shyamal Buch, Cristóbal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, Juan Carlos Niebles</b><br/>
<b>Quick Links:</b> [paper] [project website] [video] [supplementary] [code] [bibtex]
Overview
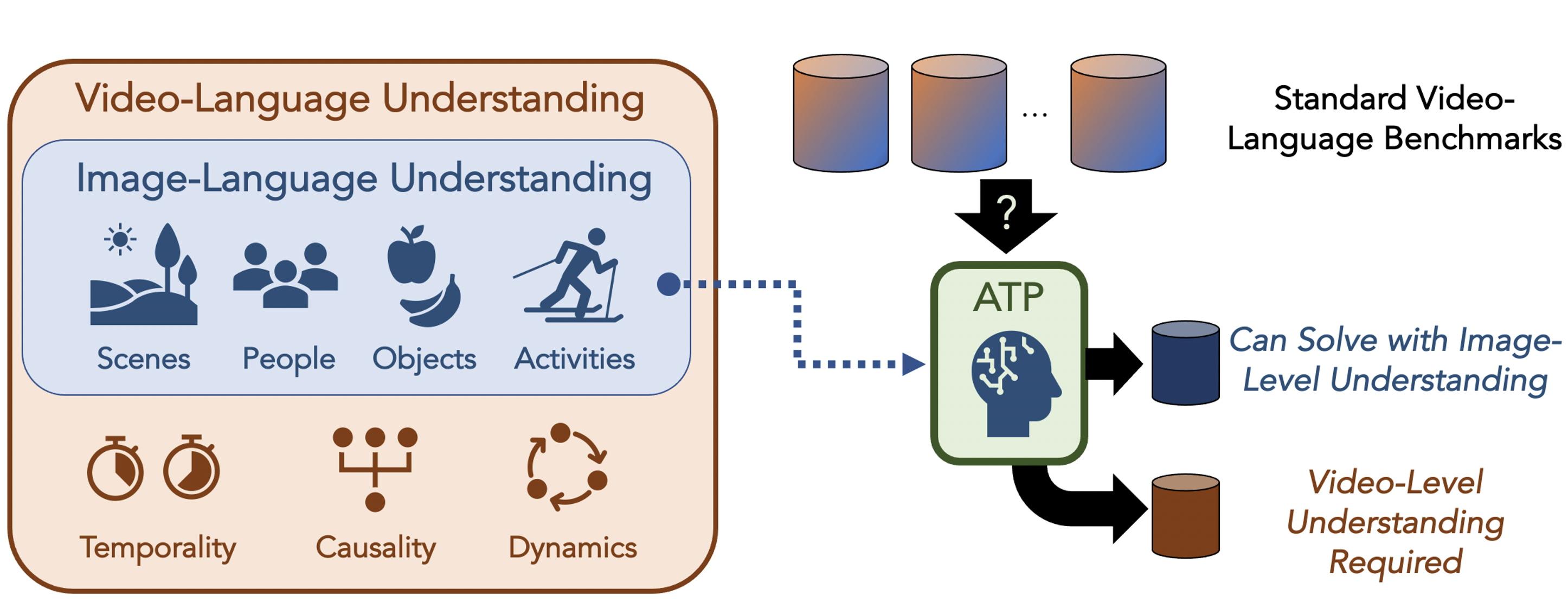
What makes a video task uniquely suited for videos, beyond what can be understood from a single image? Building on recent progress in self-supervised image-language models, we revisit this question in the context of video and language tasks. We propose the atemporal probe (ATP), a new model for video-language analysis which provides a stronger bound on the baseline accuracy of multimodal models constrained by image-level understanding. By applying this model to standard discriminative video and language tasks, such as video question answering and text-to-video retrieval, we characterize the limitations and potential of current video-language benchmarks. We find that understanding of event temporality is often not necessary to achieve strong or state-of-the-art performance, even compared with recent large-scale video-language models and in contexts intended to benchmark deeper video-level understanding. We also demonstrate how ATP can improve both video-language dataset and model design. We describe a technique for leveraging ATP to better disentangle dataset subsets with a higher concentration of temporally challenging data, improving benchmarking efficacy for causal and temporal understanding. Further, we show that effectively integrating ATP into full video-level temporal models can improve efficiency and state-of-the-art accuracy.
</details>Atemporal Probe (ATP): Code and Set-up
In this repo, we release the code for our atemporal probe (ATP) model for video-language analysis, designed to help identify cases of single frame or "atemporal" bias in discriminative video-language task settings. This code is tested with:
- Ubuntu 18.04
- PyTorch >= 1.8
- CUDA >= 10.1
# create your virtual environment
conda create --name atp python=3.7
conda activate atp
# dependencies
conda install pytorch==1.8.0 torchvision==0.9.0 cudatoolkit=10.1 -c pytorch
conda install pandas
# optional (for feature extraction); see also data/DATA.md
pip install git+https://github.com/openai/CLIP.git
Please look at src/ for more details on the provided code in this repo.
In our paper, ATP operates on top of (frozen) CLIP features for image and text encodings (ViT-B/32). For more info on dataset and feature processing please refer to data/DATA.md. The code in this repo is intended to be non-specific to any one encoder: feel free to try/modify for your own features and datasets!
Citation
<!--- If you find this code useful, please cite our CVPR paper: -->@inproceedings{buch2022revisiting,
title={ {Revisiting the ``Video'' in Video-Language Understanding} },
author={Shyamal Buch and Cristobal Eyzaguirre and Adrien Gaidon and Jiajun Wu and Li Fei-Fei and Juan Carlos Niebles},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2022}
}
LICENSE / Contact
We release this repo under the open MIT License. For any questions, please reach out to shyamal@cs.stanford.edu.
Acknowledgements
This work is in part supported by Toyota Research Institute (TRI), the Stanford Institute for Human-Centered AI (HAI), Samsung, and Salesforce. The authors also acknowledge fellowship support. Please refer to the paper for full acknowledgements, thank you!
We also reference the excellent repos of NeXT-QA, CLIP, VALUE-How2QA, ClipBERT, in addition to other specific repos to the datasets/baselines we examined (see paper). We also thank Linjie Li and the authors of benchmarks examined here for their help towards enabling more direct comparisons with prior work. If you build on this work, please be sure to cite these works/repos as well.