Awesome
<div align="center"> <br> <image src="./imgs/teaser.png", width="600px", height="287px"> <br> </div> <!--  -->Awesome Segment Anything 
Segment Anything has led to a new breakthrough in the field of Computer Vision (CV), and this repository will continue to track and summarize the research progress of Segment Anything in various fields, including Papers/Projects, etc.
If you find this repository helpful, please consider Stars ⭐ or Sharing ⬆️. Thanks.
News
- 2024.8.16 Add Segment Anything2 and SaLIP.
- 2023.8.29: Update some recent works.
- 2023.5.20: Update document structure and add a robotic-related article. Happy 520 Day!
- 2023.5.4: Add SEEM.
- 2023.4.18: Add job Inpainting Anything and SAM-Track.
- 2023.4.12: An initial version of recent papers or projects.
Contents
Papers/Projects
Basemodel Papers
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| CLIP |  | arXiv | Colab | Code | OpenAI | Contrastive Language-Image Pre-Training. |
| OWL-ViT |  | ECCV2022 | - | Code | A open-vocabulary object detector. | |
| OvSeg |  | CVPR2023 | Project | Code | META | Segment an image into semantic regions according to text descriptions. |
| Painter |  | CVPR2023 | - | Code | BAAI | A Generalist Painter for In-Context Visual Learning. |
| Grounding DINO |  | arXiv | Colab &Huggingface | Code | IDEA | A stronger open-set object detector |
| Segment Anything |   | arXiv | Project page | Code | Meta | A stronger Large model which can be used to generate masks for all objects in an image. |
| SegGPT |  | arXiv | Project page | Code | BAAI | Segmenting Everything In Context based on Painter. |
| Segment Everything Everywhere All at Once (SEEM) |  | arXiv | Project Page | Code | Microsoft | Semantic Segmentation with various prompt types. |
| Segment Everything2 | Paper | Project Page | Code | Meta | A foundation model towards solving promptable visual segmentation in images and videos.. |
Derivative Papers
Analysis and Expansion of SAM
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| CLIP_Surgery |  | arXiv | Demo | Code | HKUST | This work about SAM based on CLIP's explainability to achieve text to mask without manual points. |
| GenSAM |  | arXiv | Project Page | Code | QMUL | This work relaxes the requirement for instance-specific prompts in SAM. |
| Segment Anything Is Not Always Perfect |  | arXiv | - | - | Samsung | This paper analyzes and discusses the benefits and limitations of SAM. |
| PerSAM |  | arXiv | Project Page | Code | - | Segment Anything with specific concepts. |
| Matcher: Segment Anything with One Shot Using All-Purpose Feature Matching |  | arXiv | - | Code | - | One shot semantic segmentation by integrating an all-purpose feature extraction model and a class-agnostic segmentation model. |
| Segment Anything in High Quality |  | arXiv | Project Page | - | ETH Zürich & HKUST | HQ-SAM: improve segmentation quality of SAM using learnable High-Quality Output Token. |
| Detect Any Shadow: Segment Anything for Video Shadow Detection |  | arXiv | - | Code | University of Science and Technology of China | Use SAM to detect initial frames then use an LSTM network for subsequent frames. |
| Fast Segment Anything |  | arXiv | Project Page | Code | - | Reformulate the architecture and improve the speed of SAM. |
| MobileSAM (Faster Segment Anything) |  | arXiv | Project Page | Code | Kyung Hee University | make SAM mobile-friendly by replacing the heavyweight image encoder with a lightweight one. |
| FoodSAM (Any Food Segmentation) |  | arxiv | Project Page | Code | UCAS | semantic, instance, panoptic, interactive segmentation on food image. |
| DefectSAM |  | arxiv | - | Code | ZJU, Westlake, UESTC, etc. | infrared thermal images, defect detection. |
| SlimSAM |  | arxiv | - | Code | NUS | 0.1% Data Makes Segment Anything Slim. |
Medical Image Segmentation
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Segment Anything Model (SAM) for Digital Pathology |  | arXiv | - | - | - | SAM + Tumor segmentation/Tissue segmentation/Cell nuclei segmentation. |
| Segment Anything in Medical Images |  | arXiv | - | Code | - | A step-by-step tutorial with a small dataset to help you quickly utilize SAM. |
| SAM Fails to Segment Anything? | arXiv | - | Code | - | SAM-adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation, and More. | |
| Segment Anything Model for Medical Image Analysis: an Experimental Study |  | arXiv | - | - | - | Thorough experiments evaluating how SAM performs on 19 medical image datasets. |
| Medical-SAM-Adapter |  | arXiv | - | Code | - | A project to finetune SAM using Adaption for the Medical Imaging. |
| SAM-Med2d |  | arXiv | - | Code | Sichuan University & Shanghai AI Laboratory | The most comprehensive studies on applying SAM to medical 2D images |
| ScribblePrompt-SAM |  | arXiv | Project Page | Code | MIT & MGH | Fine-tuned SAM on 65 biomedical imaging datasets with scribble, click, and bounding box inputs |
| SaLIP | - | arXiv | Project Page | Code | - | Test-Time Adaptation with SaLIP: A Cascade of SAM and CLIP for Zero-shot |
| Medical Image Segmentation. |
Bioimage Analysis
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Segment Anything for Microscopy |  | bioRxiv | Demo | Code | University of Göttingen, Germany | Segment Anything for Microscopy implements automatic and interactive annotation for microscopy data. It is built on top of Segment Anything and specializes it for microscopy and other bio-imaging data. Its core components are: <ul><li>The micro_sam tools for interactive data annotation with napari.</li><li>The micro_sam library to apply Segment Anything to 2d and 3d data or fine-tune it on your data.</li><li>The micro_sam models that are fine-tuned on publicly available microscopy data.</li> Our goal is to build fast and interactive annotation tools for microscopy data |
Inpainting
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Inpaint Anything |  | arXiv | - | Code | USTC & EIT | SAM + Inpainting, which is able to remove the object smoothly. |
| SAM + Stable Diffusion for Text-to-Image Inpainting | 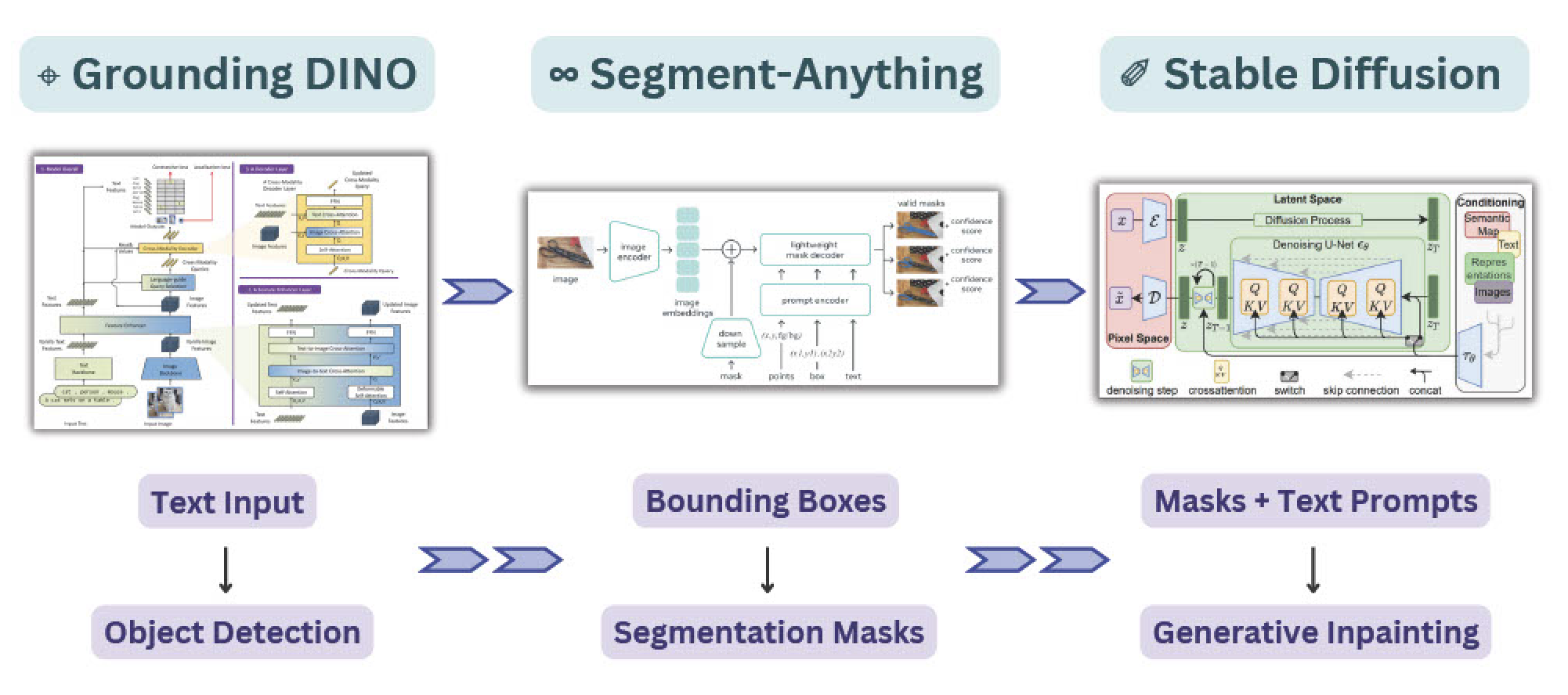 | - | Project | Code | comet | Grounding DINO + SAM + Stable Diffusion |
Camouflaged Object Detection
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| SAMCOD | - | arXiv | - | Code | - | SAM + Camouflaged object detection (COD) task. |
Video Frame Interpolation
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Clearer Frames, Anytime: Resolving Velocity Ambiguity in Video Frame Interpolation | arXiv | Project Page & Interactive Demo | Code | Shanghai AI Laboratory & Snap Inc. | Editable video frame interpolation with SAM. |
Low Level Vision
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Segment Anything in Video Super-resolution |  | arXiv | - | - | - | The first step to use SAM for low-level vision. |
| SAM-IQA |  | arXiv | - | Code | Megvii | The first to introduce the SAM in IQA and demonstrate its strong generalization ability in this domain. |
Image Matting
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Matte Anything |   | arXiv | - | Code | HUST Vision Lab | An interactive natural image matting system with excellent performance for both opaque and transparent objects |
| Matting Anything |  | arXiv | Project page | Code | SHI Labs | Leverage feature maps from SAM and adopts a Mask-to-Matte module to predict the alpha matte. |
Robotic
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Instruct2Act |  | arXiv | - | Code | OpenGVLab | A SAM application in the Robotic field. |
Bioinformatics
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| IAMSAM |  | bioRxiv | - | Code | Portrai Inc. | A SAM application for the analysis of Spatial Transcriptomics. |
3D
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Point-SAM |  | arXiv | Page | Code | UCSD | An open-world 3D native promptable point-cloud segmentation method. |
| SAMPro3D |  | arXiv | Page | Code | CUHKSZ, MSRA | A novel method to segment any 3D indoor scenes by applying the SAM to 2D frames, without need any training, tuning, distillation or 3D pretrained networks. |
| Seal |  | arXiv | Page | Code | - | A framework capable of leveraging 2D vision foundation models for self-supervised learning on large-scale 3D point clouds. |
| TomoSAM |  | arXiv | Video Tutorial | Code | - | An extension of 3D Slicer using the SAM to aid the segmentation of 3D data from tomography or other imaging techniques. |
| SegmentAnythingin3D |  | arXiv | Project | Code | - | A novel framework to Segment Anything in 3D, named SA3D. |
Remote Sensing
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| RSPrompter |  | arXiv | Project Page | Code | Beihang University | An automated instance segmentation approach for remote sensing images based on the SAM. |
| SAM-CD |  | arXiv | - | Code | PLA Information Engineering University | A sample-efficient change detection framework that employs SAM as the visual encoder. |
| SAM-Road: Segment Anything Model for Road Network Graph Extraction |  | arXiv | - | Code | Carnegie Mellon University | A simple and fast method applying SAM for vectorized large-scale road network graph extraction. It reaches state-of-the-art accuracy while being 40 times faster. |
Tracking
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Follow Anything |  | arXiv | Page | Code | MIT, Harvard University | an open-vocabulary and multimodal model to detects, tracks, and follows any objects in real-time. |
| Track-Anything | Video | arXiv | - | Code | MIT, Harvard University | an open-vocabulary and multimodal model to detects, tracks, and follows any objects in real-time. |
| SAM-Track | Video | arXiv | - | Code | MIT, Harvard University | A framework called Segment And Track Anything (SAMTrack) that allows users to precisely and effectively segment and track any object in a video. |
{kind=link}
Audio-visual Localization and Segmentation
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| AV-SAM |  | arXiv | - | Code | CMU | A simple yet effective audio-visual localization and segmentation framework based on the SAM. |
Adversarial Attacks
| Title | Presentation | Paper page | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|---|
| Attack-SAM | - | arXiv | - | - | KAIST | The |
| first work of conduct a comprehensive investigation on how to attack SAM with adversarial | ||||||
| examples. |
Derivative Projects
Image Segmentation task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| Grounded Segment Anything |  | Colab & Huggingface | Code | - | Combining Grounding DINO and Segment Anything |
| GroundedSAM Anomaly Detection |  | - | Code | - | Grounding DINO + SAM to segment any anomaly. |
| Semantic Segment Anything |  | - | Code | Fudan | A dense category annotation engine. |
| Magic Copy |  | - | Code | - | Magic Copy is a Chrome extension that uses SAM. |
| YOLO-World + EfficientViT SAM | 🤗 HuggingFace Space | Code | - | Efficient open-vocabulary object detection and segmentation with YOLO-World + EfficientViT SAM | |
| Segment Anything with Clip |  | 🤗 HuggingFace Space | Code | - | SAM + CLIP |
| SAM-Clip |  | - | Code | - | SAM + CLIP. |
| Prompt Segment Anything |  | - | Code | - | SAM + Zero-shot Instance Segmentation. |
| RefSAM | - | - | Code | - | Evaluating the basic performance of SAM on the Referring Image segmentation task. |
| SAM-RBox |  | - | Code | - | An implementation of SAM for generating rotated bounding boxes with MMRotate. |
| Open Vocabulary Segment Anything |  | - | Code | - | An interesting demo by combining OWL-ViT of Google and SAM. |
| SegDrawer |   | - | Code | - | Simple static web-based mask drawer, supporting semantic drawing with SAM. |
| AnyLabeling | 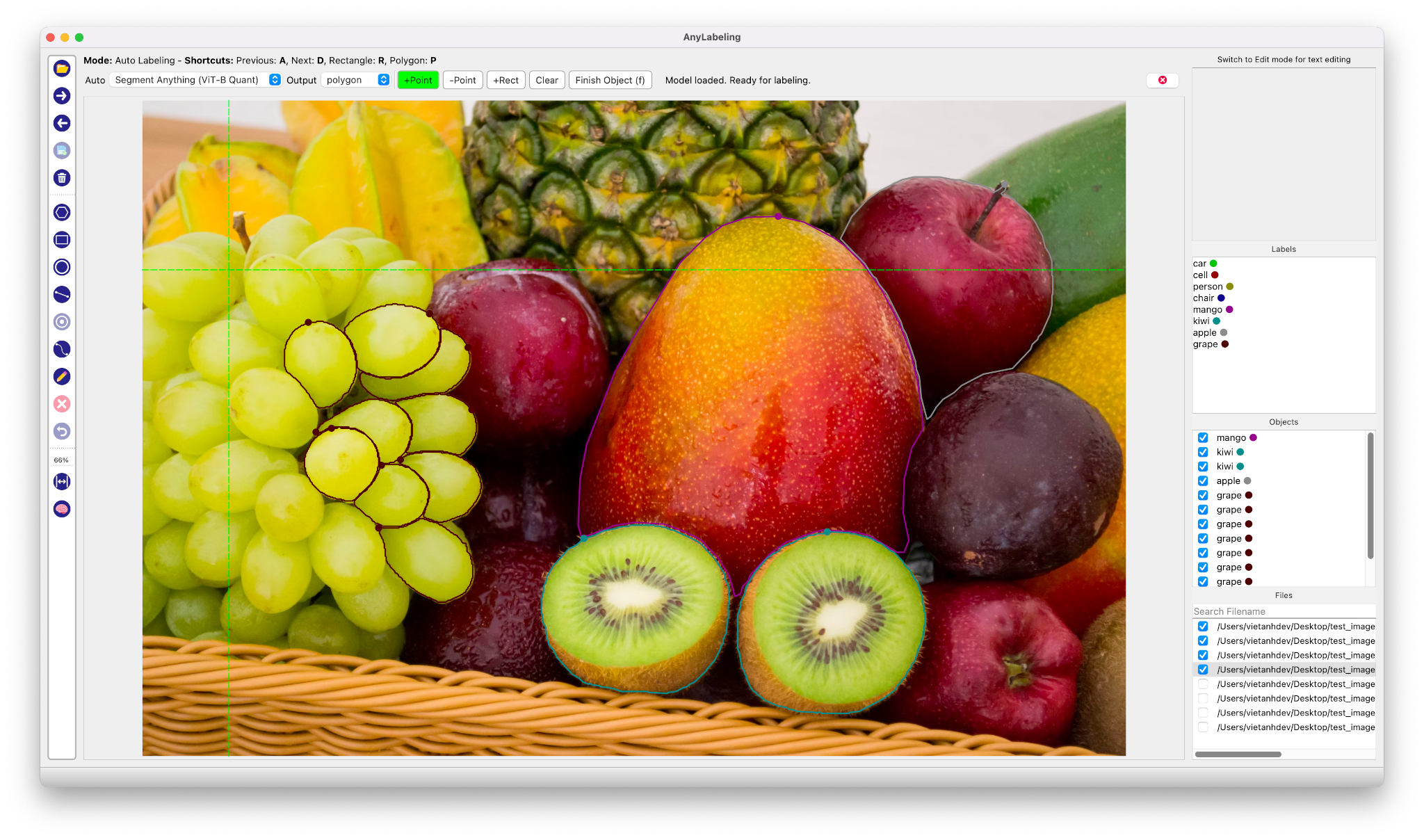 | YoutubeDemo | Code | - | SAM + Labelme + LabelImg + Auto-labeling. |
| ISAT with segment anything |  | YoutubeDemo BiliBili Demo | Code | - | Labeling tool by SAM(segment anything model),supports SAM, sam-hq, MobileSAM EdgeSAM etc. |
| Annotation Anything Pipeline |  | - | Code | - | GPT + SAM. |
| Roboflow Annotate |  | App | Blog | Roboflow | SAM-assisted labeling for training computer vision models. |
| SALT |  | - | Code | - | A tool that adds a basic interface for image labeling and saves the generated masks in COCO format.] |
| SAM U Specify |  | - | Code | - | Use SAM and CLIP model to segment unique instances you want.] |
| SAM web UI |  | App | Code | - | This is a new web interface for the SAM. |
| Finetune Anything |  | - | Code | - | A class-aware one-stage tool for training fine-tuning models based on SAM. |
| NanoSAM |  | - | Code | NVIDIA | A distilled Segment Anything (SAM) model capable of running real-time with NVIDIA TensorRT. |
Video Segmentation task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| MetaSeg |  | HuggingFace | Code | - | SAM + Video. |
| SAM-Track | Video | YoutubeDemo | Code | Zhejiang University | This project, which is based on SAM and DeAOT, focuses on segmenting and tracking objects in videos. |
Medical image Segmentation task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| SAM in Napari | Video | - | Code | - | Segment anything with Napari integration of SAM. |
| SAM Medical Imaging | 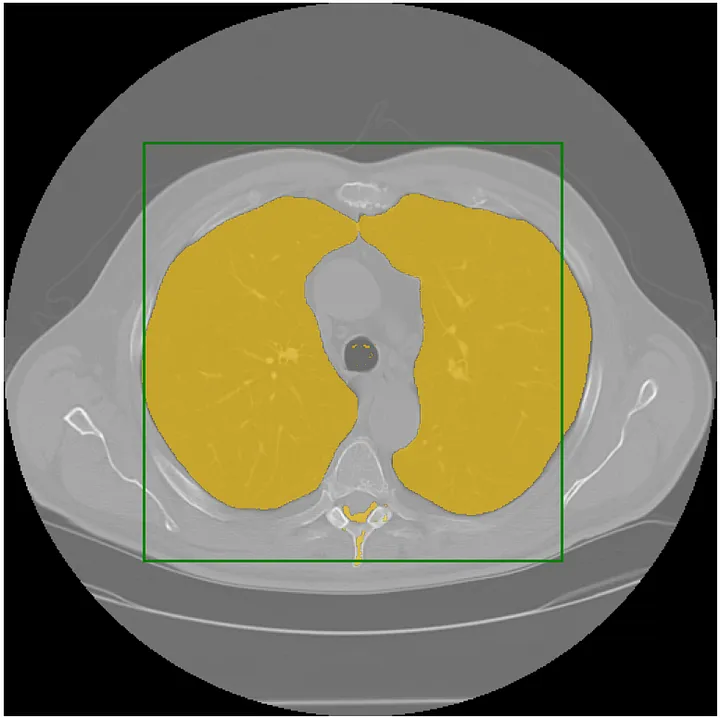 | - | Code | - | SAM for Medical Imaging. |
Inpainting task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| SegAnythingPro | - | Code | - | SAM + Inpainting/Replacing. |
3D task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| 3D-Box |  | - | Code | - | SAM is extended to 3D perception by combining it with VoxelNeXt. |
| Anything 3DNovel View |  | - | Code | - | SAM + Zero 1-to-3. |
| Any 3DFace |   | - | Code | - | SAM + HRN. |
| Segment Anything 3D |  | - | Code | Pointcept | Extending Segment Anything to 3D perception by transferring the segmentation information of 2D images to 3D space |
Image Generation task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| Edit Anything |  | - | Code | - | Edit and Generate Anything in an image. |
| Image Edit Anything |  | - | Code | - | Stable Diffusion + SAM. |
| SAM for Stable Diffusion Webui |  | - | Code | - | Stable Diffusion + SAM. |
Remote Sensing task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| Earth Observation Tools |  | Colab | Code | - | SAM + Remote Sensing. |
Moving Object Detection task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| Moving Object Detection | - | Code | - | SAM + Moving Object Detection. |
OCR task
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| OCR-SAM |  | Blog | Code | - | Optical Character Recognition with SAM. |
front-end framework
SAMJS
| Title | Presentation | Project page | Code base | Affiliation | Description |
|---|---|---|---|---|---|
| SAMJS | 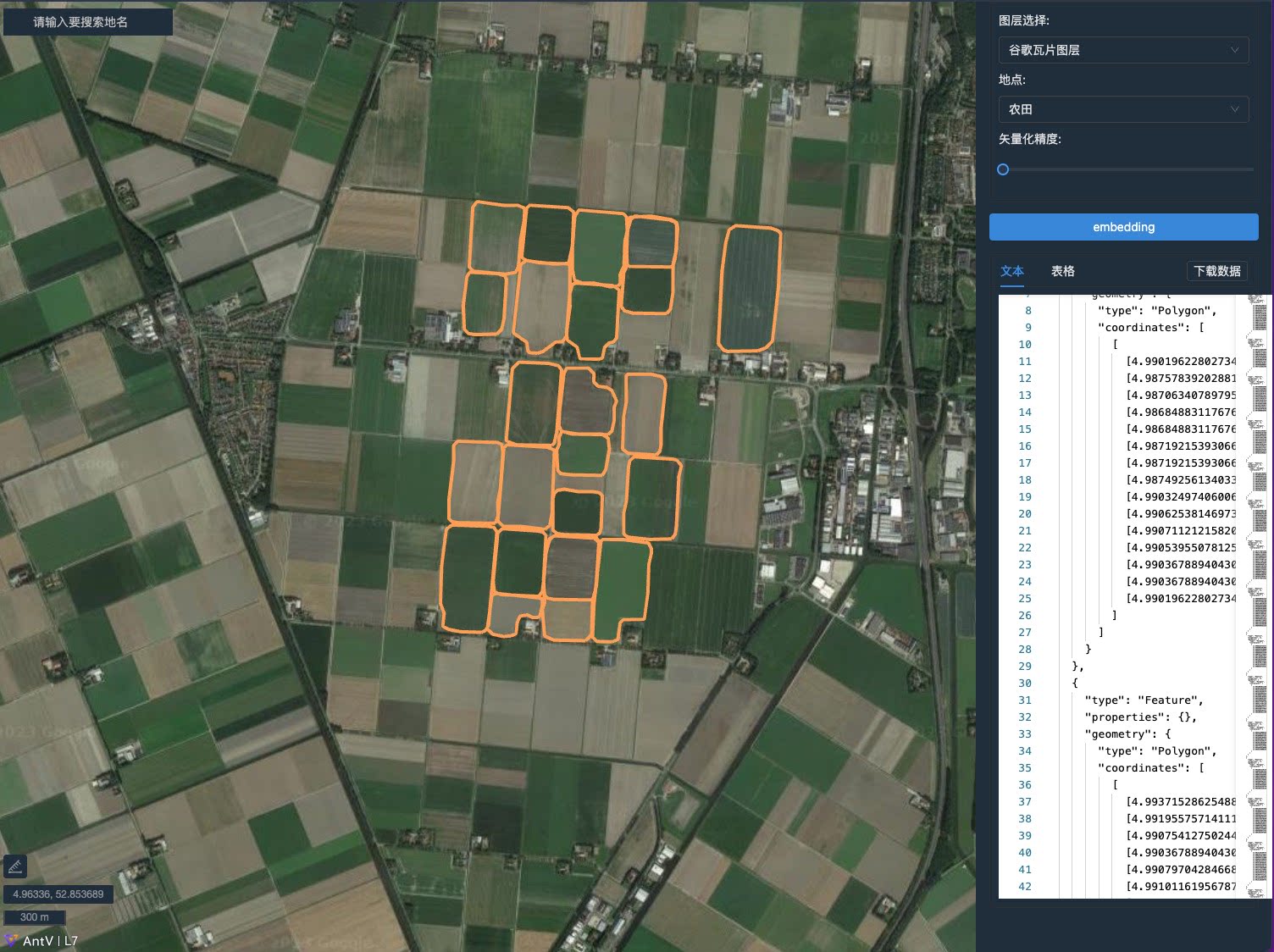 | demo | Code | - | JS SDK for SAM, Support remote sensing data segmentation and vectorization |
Acknowledgement
Some of the presentations in this repository are borrowed from the original author, and we are very thankful for their contribution.
License
This project is released under the MIT license. Please see the LICENSE file for more information.