Awesome
<img src="logo.jpg" alt="Paris" class="center"> <h1 align="center"> <a href="https://emoji.gg/emoji/9849-legocool"><img src="https://cdn3.emoji.gg/emojis/9849-legocool.png" width="64px" height="64px" alt="LEGOcool"></a> Awesome-ComposableAI <a href="https://emoji.gg/emoji/9849-legocool"><img src="https://cdn3.emoji.gg/emojis/9849-legocool.png" width="64px" height="64px" alt="LEGOcool"></a> </h1>![]()
A curated list of Composable AI methods: Building AI system by composing modules.
It includes Composable-Model, Composable-Task, Composable-Gen, Composable-Agent, and Composable-X, etc.
Contributions are welcome!
<h4 align="center"><a href="https://emoji.gg/emoji/7440-lego-brick"><img src="https://cdn3.emoji.gg/emojis/7440-lego-brick.png" width="32px" height="32px" alt="lego_brick"></a> <b>Let's build AI as Lego!<b> <a href="https://emoji.gg/emoji/7440-lego-brick"><img src="https://cdn3.emoji.gg/emojis/7440-lego-brick.png" width="32px" height="32px" alt="lego_brick"></a></h4>Table of Content
Definition
A paramount issue in AI is the combinational challenge: It is infeasible to enumerate all possibilities for an intelligent system.
Composable AI offers a solution to this challenge by emphasizing the creation of modular, flexible, and reusable AI components. These components can be assembled and reconfigured in various ways, enabling the construction of customized AI systems that are specifically tailored to individual tasks, domains, or applications.
Composable-Task
Projects & Papers
| Title & Authors | Intro | Useful Links |
|---|---|---|
| HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace <br> Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang <br> Preprint'23 <br><br> [Jarvis (Project)] | <img src="https://github.com/microsoft/JARVIS/raw/main/assets/overview.jpg"><img> | [Github] <br> [Demo] |
| MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action <br> Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, Lijuan Wang <br> Preprint'23 <br><br> [MM-REACT (Project)] | [Github] <br> [Page]<br>[Demo] | |
| TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs <br> Yaobo Liang, Chenfei Wu, Ting Song, Wenshan Wu, Yan Xia, Yu Liu, Yang Ou, Shuai Lu, Lei Ji, Shaoguang Mao, Yun Wang, Linjun Shou, Ming Gong, Nan Duan Preprint'23 |  | [Github] |
| OpenAGI: When LLM Meets Domain Experts <br> Yingqiang Ge, Wenyue Hua, Jianchao Ji, Juntao Tan, Shuyuan Xu, Yongfeng Zhang <br><br> [OpenAGI (Project)] |  | Github |
| ChatGPT Asks, BLIP-2 Answers: Automatic Questioning Towards Enriched Visual Descriptions <br> Deyao Zhu, Jun Chen, Kilichbek Haydarov, Xiaoqian Shen, Wenxuan Zhang, Mohamed Elhoseiny <br>Preprint'23<br> [ChatCaptioner (Project)] |  | Github |
| Visual Programming: Compositional visual reasoning without training<br> Tanmay Gupta, Aniruddha Kembhavi <br>CVPR'23<br> Visprog (Project) |  | [Github] <br> [Page] |
| ViperGPT: Visual Inference via Python Execution for Reasoning<br> Dídac Surís, Sachit Menon, Carl Vondrick <br>CVPR'23<br> Viper (Project) |  | [Github] <br> [Page] |
| Composing Ensembles of Pre-trained Models via Iterative Consensus<br> Shuang Li, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba, Igor Mordatch <br>ICLR'23<br> |  | [Page] |
| Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language<br> Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, Pete Florence <br>ICLR'23<br> socraticmodels (Project) |  | [Github] <br> [Page] |
Project Only
| Title & Authors | Intro | Useful Links |
|---|---|---|
| Grounded-SAM (Project) <br>[Grounding DINO + Segment-Anything + X] <br> Shilong Liu and Zhaoyang Zeng and Tianhe Ren and Feng Li and Hao Zhang and Jie Yang and Chunyuan Li and Jianwei Yang and Hang Su and Jun Zhu and Lei Zhang |  | [Github] <br> [Demo] |
| Semantic-Segment-Anything (Project)<br> [Close-set Segmenters + Open-vocabulary Models]<br> Jiaqi Chen, Zeyu Yang, Li Zhang |  | [Github] |
 <br> Inpaint-Anything: Segment Anything Meets Image Inpainting (Project) <br> [SAM + LaMa + Stable Diffusion]<br> Tao Yu <br> Inpaint-Anything: Segment Anything Meets Image Inpainting (Project) <br> [SAM + LaMa + Stable Diffusion]<br> Tao Yu |  | [Github] |
| Segment Anything and Name It (Project)<br>[Visual ChatGPT + GLIP + Segment-Anything]<br> Peize Sun and Shoufa Chen |  | [Github] |
 <br> EditAnything (Project)<br> [Segment Anything + ControlNet + BLIP2 + Stable Diffusion] <br> Shanghua Gao, Pan Zhou <br> EditAnything (Project)<br> [Segment Anything + ControlNet + BLIP2 + Stable Diffusion] <br> Shanghua Gao, Pan Zhou |  | [Github] |
Composable-Model
Projects & Papers
| Title & Authors | Intro | Useful Links |
|---|---|---|
| AdapterHub: A Framework for Adapting Transformers <br> Álvaro Barbero Jiménez <br> EMNLP'20 <br><br> [adapter-transformers (Project)] | <img src="https://adapterhub.ml/static/adapter-bert.png" alt="Girl in a jacket" height="300"> | [Github] <br> [Page] |
| Deep Model Reassembly <br> Xingyi Yang, Daquan Zhou, Songhua Liu, Jingwen Ye, Xinchao Wang <br> NeurIPS'22 <br><br> [DeRy (Project)] <br> |  | [Github] <br> [Page] |
| Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer <br> Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, Jeff Dean <br> ICLR'17 <br><br> [mixture-of-experts (Project)] <br> | [Github] |
Composable-Gen
Projects & Papers
| Title & Authors | Intro | Useful Links |
|---|---|---|
| Mixture of Diffusers for scene composition and high resolution image generation <br> Álvaro Barbero Jiménez <br> Preprint'23 <br><br> [Mixture-of-Diffusers (Project)] |  | [Github] <br> [Demo] |
| Compositional Visual Generation with Composable Diffusion Models <br> Nan Liu, Shuang Li, Yilun Du, Antonio Torralba, Joshua B. Tenenbaum <br> ECCV'22 <br><br> [Composable Diffusion (Project)] |  | [Github] <br> [Demo] <br> [Page] |
| Training-Free Structured Diffusion Guidance for Compositional Text-to-Image Synthesis <br> Weixi Feng, Xuehai He, Tsu-Jui Fu, Varun Jampani, Arjun Akula, Pradyumna Narayana, Sugato Basu, Xin Eric Wang, William Yang Wang <br> ICLR'23 <br><br> [Structured-Diffusion-Guidance (Project)] | 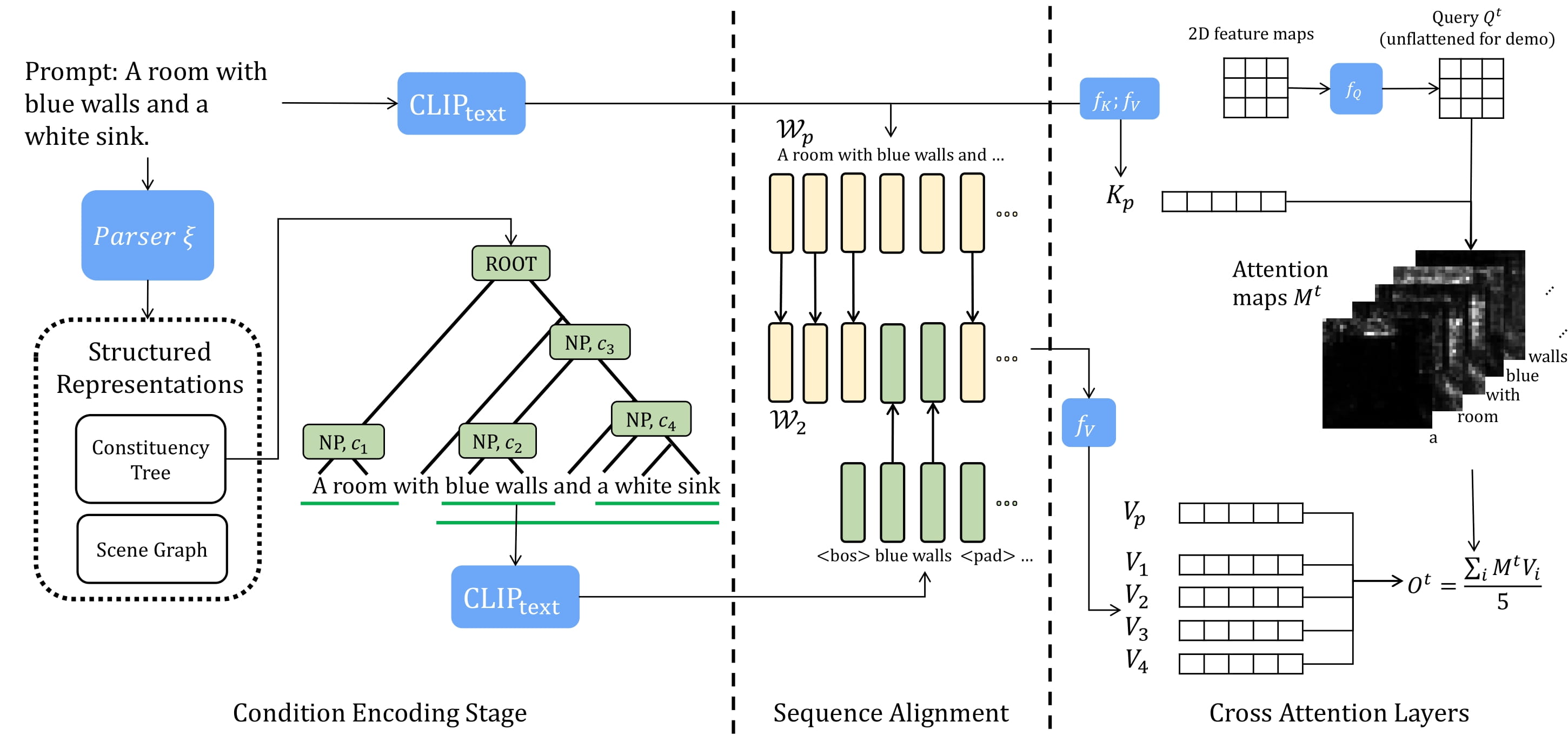 | [Github] <br> [Page] |
| Reduce, Reuse, Recycle: Compositional Generation with Energy-Based Diffusion Models and MCMC <br> Yilun Du, Conor Durkan, Robin Strudel, Joshua B. Tenenbaum, Sander Dieleman, Rob Fergus, Jascha Sohl-Dickstein, Arnaud Doucet, Will Grathwohl <br> Preprint'23 <br><br> [reduce_reuse_recycle (Project)] |  | [Github] <br> [Page] |
| Learning to Compose Visual Relations <br> Nan Liu, Shuang Li, Yilun Du, Joshua B. Tenenbaum, Antonio Torralba <br> NeurIPS'21 <br><br> [compose-visual-relations (Project)] |  | [Github] <br> [Page] |
Composable-Agent
Paper Only
- MCP: Learning Composable Hierarchical Control with Multiplicative Compositional Policies Xue Bin Peng, Michael Chang, Grace Zhang, Pieter Abbeel, Sergey Levine NeurIPS'19 [Paper]
- Composable Planning with Attributes Amy Zhang, Sainbayar Sukhbaatar, Adam Lerer, Arthur Szlam, Rob Fergus ICML'18 [Paper]
Composable-Product
| Title & Authors | Intro | Useful Links |
|---|---|---|
| langchain (Project)<br> [LLM + X] |  | Github |
Composable-X
TO BE UPDATE