Awesome
JsoupXpath

![]()
![]()
纯Java实现的支持W3C Xpath 1.0标准语法的HTML解析器。A html parser with xpath base on Jsoup and Antlr4.Maybe it is the best in java,Just try it.
If you like this project, please give it a Star. Read detail document in English | 日本語 | 한국어 | Русский | Français.
简介
JsoupXpath 是一款纯Java开发的使用xpath解析提取html数据的解析器,针对html解析完全重新实现了W3C XPATH 1.0标准语法,xpath的Lexer和Parser基于Antlr4构建,html的DOM树生成采用Jsoup,故命名为JsoupXpath. 为了在java里也享受xpath的强大与方便但又苦于找不到一款足够好用的xpath解析器,故开发了JsoupXpath。JsoupXpath的实现逻辑清晰,扩展方便, 支持完备的W3C XPATH 1.0标准语法,W3C规范:http://www.w3.org/TR/1999/REC-xpath-19991116 ,JsoupXpath语法描述文件Xpath.g4
Change Log
https://github.com/zhegexiaohuozi/JsoupXpath/releases
社区讨论
- Issue
https://github.com/zhegexiaohuozi/JsoupXpath/issues
- 微信订阅号

里面会发布一些使用案例等文章,以及seimi体系相关项目的最新更新动态等。也会有作者关于互联网后端技术一些文章和感悟。
快速开始
maven依赖,全版本请参见release信息或中央maven库:
<dependency>
<groupId>cn.wanghaomiao</groupId>
<artifactId>JsoupXpath</artifactId>
<version>2.5.3</version>
</dependency>
示例:
String html = "<html><body><script>console.log('aaaaa')</script><div class='test'>some body</div><div class='xiao'>Two</div></body></html>";
JXDocument underTest = JXDocument.create(html);
String xpath = "//div[contains(@class,'xiao')]/text()";
JXNode node = underTest.selNOne(xpath);
Assert.assertEquals("Two",node.asString());
其他可以参考 org.seimicrawler.xpath.JXDocumentTest,这里有大量的测试用例
或者Issue中比较典型的例子
语法
支持完备的W3C XPATH 1.0标准语法,W3C规范:http://www.w3.org/TR/1999/REC-xpath-19991116
这里是JsoupXpath的基于Antlr4的语法解析树示例,方便大家更快速的一览JsoupXpath的语法处理能力与语法解析执行过程
-
//ul[@class='subject-list']/li[./div/div/span[@class='pl']/num()>(1000+90*(2*50))][last()][1]/div/h2/allText()这个主要是一些表达式嵌套的解析示例,点击图片可以查看大图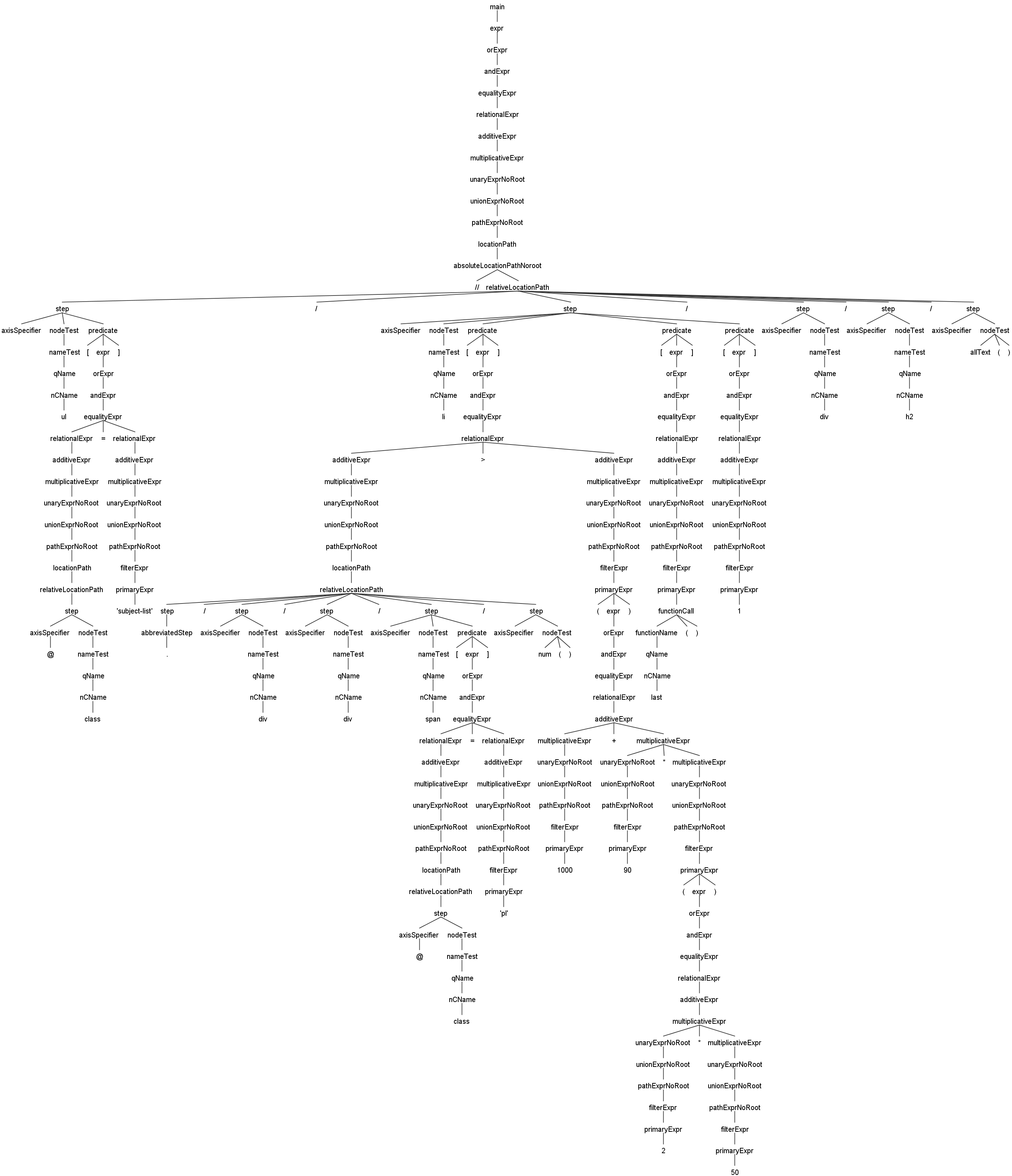
-
//ul[@class='subject-list']/li[not(contains(self::li/div/div/span[@class='pl']//text(),'14582'))]/div/h2//text()这个是对内置函数支持的一个解析示例,点击图片可以查看大图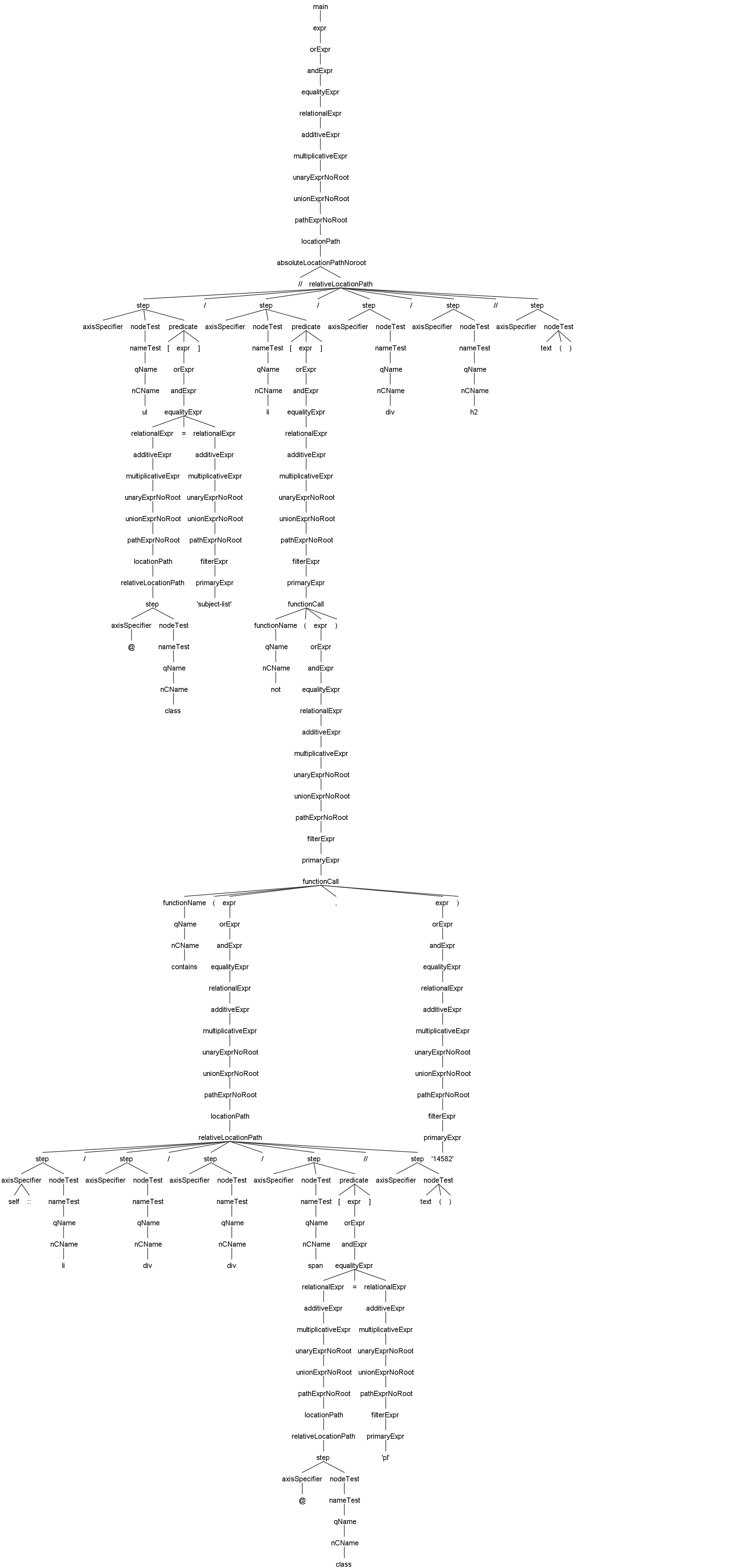
关于使用Xpath的一些注意事项
多数情况下是不建议直接粘贴Firefox或chrome里生成的Xpath,这些浏览器在渲染页面会根据标准自动补全一些标签,如table标签会自动加上tbody标签,这样生成的Xpath路径显然不是最通用的,所以很可能就取不到值。所以,要使用Xpath并感受Xpath的强大以及他所带来便捷与优雅最好就是学习下Xpath的标准语法,这样应对各种问题才能游刃有余,享受Xpath的真正威力!
函数
-
int position()返回当前节点在其所在上下文中的位置 -
int last()返回所在上下文的最后那个节点位置 -
int first()返回所在上下文的的第一个节点位置 -
string concat(string, string, string*)连接若干字符串 -
boolean contains(string, string)判断第一个字符串是否包含第二个 -
int count(node-set)计算给定的节点集合中节点个数 -
double/long sum(node-set)计算给定的节点集合中数字节点值的和,计算参数范围内包含非数字内容则计算无效。 -
boolean starts-with(string, string)判断第一个字符串是否以第二个开头 -
int string-length(string?)如果给定了字符串则返回字符串长度,如果没有,那么则将当前节点转为字符串并返回长度 -
string substring(string, number, number?)第一个参数指定字符串,第二个指定起始位置(xpath索引都是从1开始),第三指定要截取的长度,这里要注意在xpath的语法里这,不是结束的位置。substring("12345", 1.5, 2.6) returns "234"
substring("12345", 2, 3) returns "234"
-
string substring-ex(string, number, number)第一个参数指定字符串,第二个指定起始位置(java里的习惯从0开始),第三个结束的位置(支持负数),这个是JsoupXpath扩展的函数,方便java习惯的开发者使用。 -
string substring-after(string, string)在第一个字符串中截取第二个字符串之后的部分 -
string substring-after-last(string, string)在第一个字符串中截取第二个字符串最后出现位置之后的部分 -
string substring-before(string, string)在第一个字符串中截取第二个字符串之前的部分 -
string substring-before-last(string, string)在第一个字符串中截取第二个字符串最后出现位置之前的部分 -
date format-date(string, string ,string)第一个参数是表达式,第二个参数是表达式值的时间格式,第三个参数是时区locale,非必填
开发者添加函数
以上只是Xpath1.0标准中的函数,开发亦可以方便快捷的添加自定义函数,只需实现 org.seimicrawler.xpath.core.Function.java接口,并在你的系统初始化的时候调用Scanner.registerFunction(Class<? extends Function> func),不需要修改语法范式,JsoupXpath运行时即可识别并加载。对于标准语法中目前JsoupXpath还未实现的函数,欢迎大家向主仓库提交Pull request,一起添砖添瓦。
NodeTest
allText()提取节点下全部文本,取代类似//div/h3//text()这种递归取文本用法html()获取全部节点的内部的htmlouterHtml()获取全部节点的 包含节点本身在内的全部htmlnum()抽取节点自有文本中全部数字,如果知道节点的自有文本(即非子代节点所包含的文本)中只存在一个数字,如阅读数,评论数,价格等那么直接可以直接提取此数字出来。如果有多个数字将提取第一个匹配的连续数字。text()提取节点的自有文本。更多介绍可参见 https://github.com/zhegexiaohuozi/JsoupXpath/releases/tag/v2.4.1node()提取所有节点
轴
AxisName: 'ancestor' //在当前上下文中节点的祖先中选择
| 'ancestor-or-self' //在当前上下文中节点的祖先及包括自身中选择
| 'attribute' //标记做提取节点属性运算
| 'child' //在当前上下文中节点的子节点中选择 这是xpath默认的轴,如 /div/li 就是 /div/child::li 的简写
| 'descendant' //在当前上下文中节点的后代中选择
| 'descendant-or-self' //在当前上下文中节点的后代包括自身中选择
| 'following' //在当前上下文中节点后面的全部节点中选择
| 'following-sibling' //在当前上下文中节点后面的全部同胞节点中选择
| 'parent' //在当前上下文中节点的父亲节点中选择
| 'preceding' //在当前上下文中节点前面的全部节点中选择
| 'preceding-sibling' //在当前上下文中节点前面的全部同胞节点中选择
| 'self' //当前上下文中选择
| 'following-sibling-one' //在上下文中节点的下一个同胞节点中选择(JsoupXpath扩展)
| 'preceding-sibling-one' //在上下文中节点的前一个同胞节点选择(JsoupXpath扩展)
| 'sibling' //全部同胞(JsoupXpath扩展)(开发中。。。)
;
操作符
MINUS
: '-';
PLUS
: '+';
DOT
: '.';
MUL
: '*';
DIVISION
: '`div`';
MODULO
: '`mod`';
DOTDOT
: '..';
AT
: '@';
COMMA
: ',';
PIPE
: '|';
LESS
: '<';
MORE_
: '>';
LE
: '<=';
GE
: '>=';
START_WITH
: '^='; // `a^=b` 字符串a以字符串b开头 a startwith b (JsoupXpath扩展)
END_WITH
: '$='; // `a*=b` a包含b, a contains b (JsoupXpath扩展)
CONTAIN_WITH
: '*='; // a包含b, a contains b (JsoupXpath扩展)
REGEXP_WITH
: '~='; // a的内容符合 正则表达式b (JsoupXpath扩展)
REGEXP_NOT_WITH
: '!~'; //a的内容不符合 正则表达式b (JsoupXpath扩展)
应用的项目
目前JsoupXpath被大量使用的项目或是组织有:SeimiCrawler。 如果您也有项目在使用JsoupXpath,并希望出现在这个列表中,可以通过下面的联系方式联系我,邮件格式可以为:
项目或组织名称:XX
项目或组织URL:http://xxx.xxx.cc