Awesome
Template Code: BERT-for-Sequence-Labeling-and-Text-Classification
BERT is used for sequence annotation and text categorization template code to facilitate BERT for more tasks. The code has been tested on snips (intention recognition and slot filling task), ATIS (intention recognition and slot filling task) and conll-2003 (named entity recognition task) datasets. Welcome to use this BERT template to solve more NLP tasks, and then share your results and code here.
这是使用BERT进行序列标注和文本分类的模板代码,方便大家将BERT用于更多任务。该代码已经在SNIPS(意图识别和槽填充任务)、ATIS(意图识别和槽填充任务)和conll-2003(命名实体识别任务)数据集上进行了实验。欢迎使用这个BERT模板解决更多NLP任务,然后在这里分享你的结果和代码。
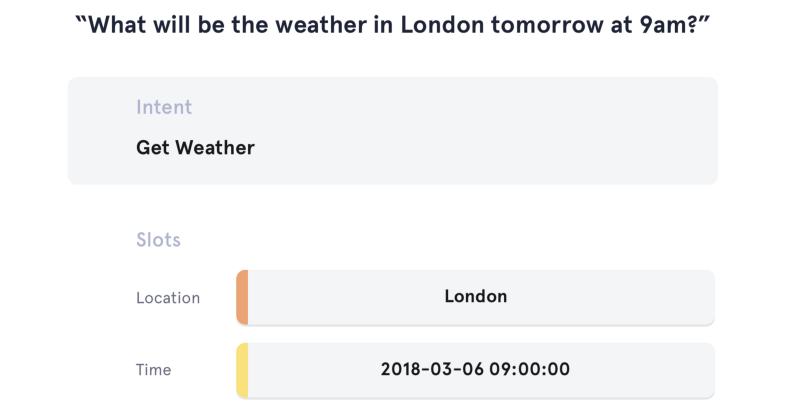
Task and Dataset
I have downloaded the data for you. Welcome to add new data set.
| task name | dataset name | data source |
|---|---|---|
| CoNLL-2003 named entity recognition | conll2003ner | https://www.clips.uantwerpen.be/conll2003/ner/ |
| Atis Joint Slot Filling and Intent Prediction | atis | https://github.com/MiuLab/SlotGated-SLU/tree/master/data/atis |
| Snips Joint Slot Filling and Intent Prediction | snips | https://github.com/MiuLab/SlotGated-SLU/tree/master/data/snips |
Environment Requirements
Use pip install -r requirements.txt to install dependencies quickly.
- python 3.6+
- Tensorflow 1.12.0+
- sklearn
Template Code Usage Method
Using pre training and fine-tuning model directly
For example: Atis Joint Slot Filling and Intent Prediction
- Download model weight atis_join_task_LSTM_epoch30_simple.zip and unzip then to file
store_fine_tuned_model, https://pan.baidu.com/s/1SZkQXP8NrOtZKVEMfDE4bw; - Run Code! You can change task_name and output_dir.
python run_slot_intent_join_task_LSTM.py \
--task_name=Atis \
--do_predict=true \
--data_dir=data/atis_Intent_Detection_and_Slot_Filling \
--vocab_file=pretrained_model/uncased_L-12_H-768_A-12/vocab.txt \
--bert_config_file=pretrained_model/uncased_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=store_fine_tuned_model/atis_join_task_LSTM_epoch30_simple/model.ckpt-4198 \
--max_seq_length=128 \
--output_dir=./output_model_predict/atis_join_task_LSTM_epoch30_simple_ckpt4198
You can find the file of model prediction and the score of model prediction in output_dir (You can find the content of model socres later).
Quick start(model train and predict)
See predefined_task_usage.md for more predefined task usage codes.
- Move google's BERT code to file
bert(I've prepared a copy for you.); - Download google's BERT pretrained model and unzip then to file
pretrained_model, https://github.com/google-research/bert; - Run Code! You can change task_name and output_dir.
model training
python run_sequence_labeling_and_text_classification.py \
--task_name=snips \
--do_train=true \
--do_eval=true \
--data_dir=data/snips_Intent_Detection_and_Slot_Filling \
--vocab_file=pretrained_model/uncased_L-12_H-768_A-12/vocab.txt \
--bert_config_file=pretrained_model/uncased_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=pretrained_model/uncased_L-12_H-768_A-12/bert_model.ckpt \
--num_train_epochs=3.0 \
--output_dir=./store_fine_tuned_model/snips_join_task_epoch3/
Then you can find the fine tuned model in the output_dir=./store_fine_tuned_model/snips_join_task_epoch3/ folder.
model prediction
python run_sequence_labeling_and_text_classification.py \
--task_name=Snips \
--do_predict=true \
--data_dir=data/snips_Intent_Detection_and_Slot_Filling \
--vocab_file=pretrained_model/uncased_L-12_H-768_A-12/vocab.txt \
--bert_config_file=pretrained_model/uncased_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=output_model/snips_join_task_epoch3/model.ckpt-1000 \
--max_seq_length=128 \
--output_dir=./output_model_prediction/snips_join_task_epoch3_ckpt1000
Then you can find the predicted output of the model and the output test results (accuracy, recall, F1 value, etc.) in the output_dir=./output_model_prediction/snips_join_task_epoch3_ckpt1000 folder.
File Structure
| name | function |
|---|---|
| bert | store google's BERT code |
| data | store task raw data set |
| output_model_prediction | store model predict |
| store_fine_tuned_model | store finet tuned model |
| calculating_model_score | |
| pretrained_model | store BERT pretrained model |
| run_sequence_labeling.py | for Sequence Labeling Task |
| run_text_classification.py | for Text Classification Task |
| run_sequence_labeling_and_text_classification.py | for join task |
| calculate_model_score.py | for evaluation model |
Model Socres
The following model scores are model scores without careful adjustment of model parameters, that is to say, the scores can continue to improve!
CoNLL-2003 named entity recognition
eval_f = 0.926 eval_precision = 0.925 eval_recall = 0.928
Atis Joint Slot Filling and Intent Prediction
Intent Prediction Correct rate: 0.976 Accuracy: 0.976 Recall rate: 0.976 F1-score: 0.976
Slot Filling19 Correct rate: 0.955 Accuracy: 0.955 Recall rate: 0.955 F1-score: 0.955
How to add a new task
Just write a small piece of code according to the existing template!
Data
For example, If you have a new classification task QQP.
Before running this example you must download the GLUE data by running this script.
Code
Now, write code!
class QqpProcessor(DataProcessor):
"""Processor for the QQP data set."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0 or len(line)!=6:
continue
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[3])
text_b = tokenization.convert_to_unicode(line[4])
if set_type == "test":
label = "1"
else:
label = tokenization.convert_to_unicode(line[5])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=text_b, label=label))
return examples
Registration task
def main(_):
tf.logging.set_verbosity(tf.logging.INFO)
processors = {
"qqp": QqpProcessor,
}
Run
python run_text_classification.py \
--task_name=qqp \
--do_train=true \
--do_eval=true \
--data_dir=data/snips_Intent_Detection_and_Slot_Filling \
--vocab_file=pretrained_model/uncased_L-12_H-768_A-12/vocab.txt \
--bert_config_file=pretrained_model/uncased_L-12_H-768_A-12/bert_config.json \
--init_checkpoint=pretrained_model/uncased_L-12_H-768_A-12/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=./output/qqp_Intent_Detection/