Awesome
SC2 Benchmark: Supervised Compression for Split Computing
![]()

This is the official repository of sc2bench package and our TMLR paper, "SC2 Benchmark: Supervised Compression for Split Computing".
As an intermediate option between local computing and edge computing (full offloading), split computing has been attracting considerable attention from the research communities.
In split computing, we split a neural network model into two sequences so that some elementary feature transformations are applied by the first sequence of the model on a weak mobile (local) device. Then, intermediate, informative features are transmitted through a wireless communication channel to a powerful edge server that processes the bulk part of the computation (the second sequence of the model).
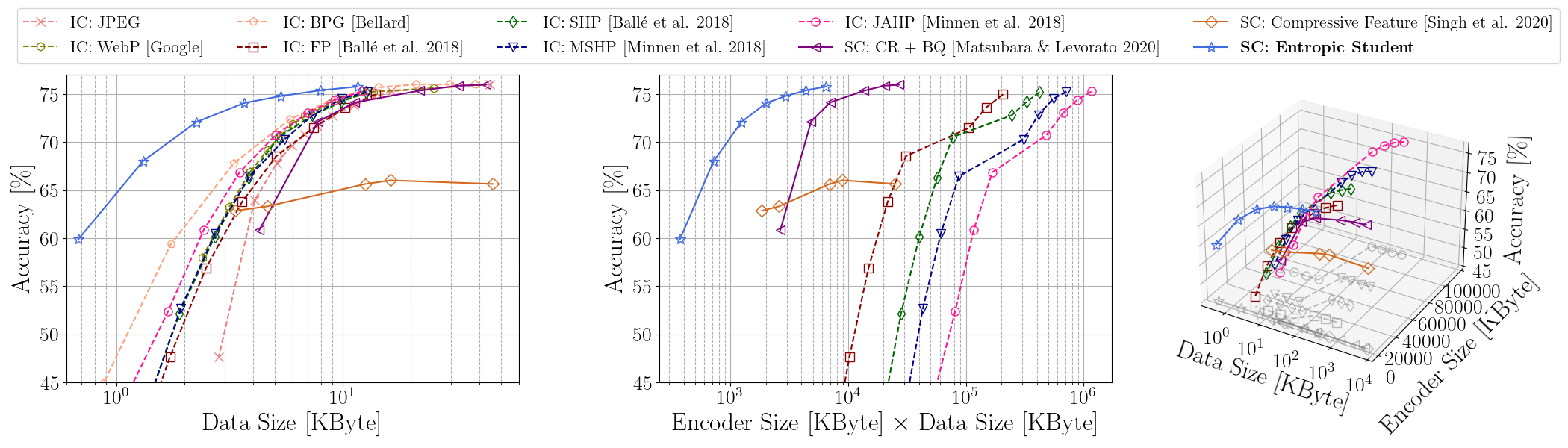 ImageNet (ILSVRC 2012): R-D (rate-distortion), ExR-D, and three-way tradeoffs for input compression and supervised compression with ResNet-50 as a reference model
ImageNet (ILSVRC 2012): R-D (rate-distortion), ExR-D, and three-way tradeoffs for input compression and supervised compression with ResNet-50 as a reference model
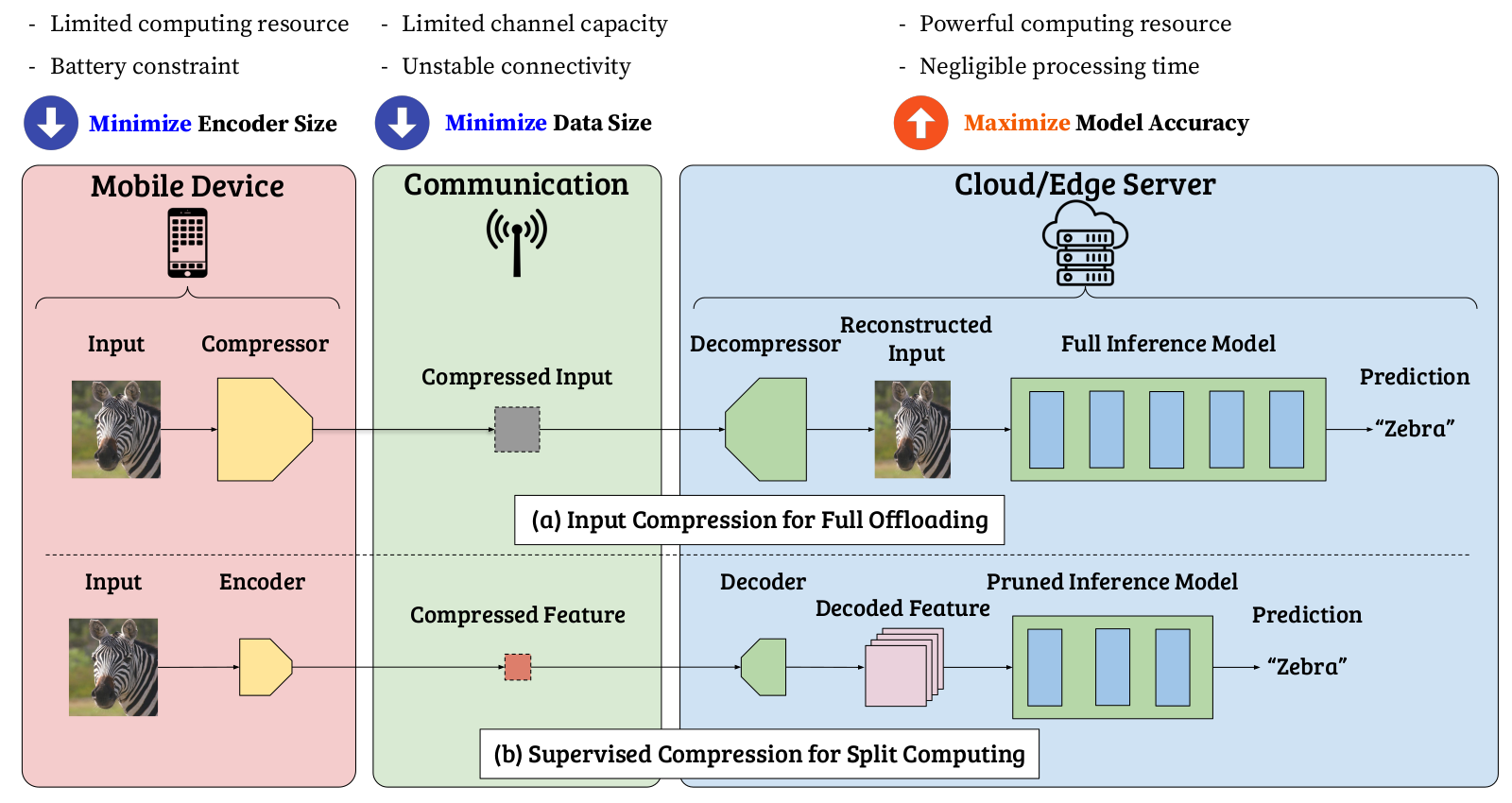
Input compression is an approach to save transmitted data, but it leads to transmitting information irrelevant to the supervised task. To achieve better supervised rate-distortion tradeoff, we define supervised compression as learning compressed representations for supervised downstream tasks such as classification, detection, or segmentation. Specifically for split computing, we term the problem setting SC2 (Supervised Compression for Split Computing).
Note that the training process can be done offline (i.e., on a single device without splitting), and it is different from "split learning".
SC2 Metrics
1. Encoder Size (to be minimized)
Local processing cost should be minimized as local (mobile) devices usually have battery constraints and limited computing power. As a simple proxy for the computing costs, we measure the number of encoder parameters and define the encoder size as the total number of bits to represent the parameters of the encoder.
2. Data Size (to be minimized)
We want to penalize large data being transferred from the mobile device to the edge server while the BPP does not penalize it when feeding higher resolution images to downstream models for achieving higher model accuracy.
3. Model Accuracy (to be maximized)
While minimizing the two metrics, we want to maximize model accuracy (minimize supervised distortion). Example supervised distortions are accuracy, mean average precision (mAP), and mean intersection over union (mIoU) for image classification, object detection, and semantic segmentation, respectively.
Installation
pip install sc2bench
Virtual Environments
For pipenv users,
pipenv install --python 3.9
# or create your own pipenv environment
pipenv install sc2bench
Datasets
See instructions here
Checkpoints
You can download our checkpoints including trained model weights here.
Unzip the downloaded zip files under ./, then there will be ./resource/ckpt/.
Supervised Compression
- CR + BQ: "Neural Compression and Filtering for Edge-assisted Real-time Object Detection in Challenged Networks"
- End-to-End: "End-to-end Learning of Compressible Features"
- Entropic Student: "Supervised Compression for Resource-Constrained Edge Computing Systems"
README.md explains how to train/test implemented supervised compression methods.
Baselines: Input Compression
- Codec-based input compression: JPEG, WebP, BPG
- Neural input compression: Factorized Prior, Scale Hyperprior, Mean-scale Hyperprior, and Joint Autoregressive Hierarchical Prior
Each README.md gives instructions to run the baseline experiments.
Codec-based Feature Compression
# JPEG
python script/task/image_classification.py -test_only --config configs/ilsvrc2012/feature_compression/jpeg-resnet50.yaml
# WebP
python script/task/image_classification.py -test_only --config configs/ilsvrc2012/feature_compression/webp-resnet50.yaml
Citation
@article{matsubara2023sc2,
title={{SC2 Benchmark: Supervised Compression for Split Computing}},
author={Matsubara, Yoshitomo and Yang, Ruihan and Levorato, Marco and Mandt, Stephan},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2023},
url={https://openreview.net/forum?id=p28wv4G65d}
}
Note
For measuring data size per sample precisely, it is important to keep test batch size of 1 when testing.
E.g., some baseline modules may expect larger batch size if you have multiple GPUs.
Then, add CUDA_VISIBLE_DEVICES=0 before your execution command (e.g., sh, bash, python)
so that you can force the script to use one GPU (use GPU: 0 in this case).
For instance, an input compression experiment using factorized prior (pretrained input compression model) and ResNet-50 (pretrained classifier)
CUDA_VISIBLE_DEVICES=0 sh script/neural_input_compression/ilsvrc2012-image_classification.sh factorized_prior-resnet50 8
Issues / Questions / Requests
The documentation is work-in-progress. In the meantime, feel free to create an issue if you find a bug.
If you have either a question or feature request, start a new discussion here.
References
- PyTorch (torchvision)
- PyTorch Image Models (timm)
- CompressAI
- torchdistill
- Johannes Ballé, David Minnen, Saurabh Singh, Sung Jin Hwang and Nick Johnston. "Variational image compression with a scale hyperprior" (ICLR 2018)
- David Minnen, Johannes Ballé and George D. Toderici. "Joint Autoregressive and Hierarchical Priors for Learned Image Compression" (NeurIPS 2018)
- Yoshitomo Matsubara and Marco Levorato. "Neural Compression and Filtering for Edge-assisted Real-time Object Detection in Challenged Networks" (ICPR 2020)
- Saurabh Singh, Sami Abu-El-Haija, Nick Johnston, Johannes Ballé, Abhinav Shrivastava and George Toderici. "End-to-end Learning of Compressible Features" (ICIP 2020)
- Yoshitomo Matsubara, Ruihan Yang, Marco Levorato and Stephan Mandt. "Supervised Compression for Resource-Constrained Edge Computing Systems" (WACV 2022)