Awesome
Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image
<a href="https://arxiv.org/abs/2203.09457"><img src="https://img.shields.io/badge/arXiv-2203.09457-b31b1b.svg"></a> <a href="https://opensource.org/licenses/MIT"><img src="https://img.shields.io/badge/License-MIT-yellow.svg"></a>
This repository contains the code (in PyTorch) for the model introduced in the following paper:
Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image <br> Xuanchi Ren, Xiaolong Wang <br> CVPR 2022<br>
[Paper] [Project Page (Demos)] [Supplementary]

Our method can synthesize a consistent long-term 3D scene video from a single image, especially for looking outside the room.
Citation
@inproceedings{ren2022look,
title = {Look Outside the Room: Synthesizing A Consistent Long-Term 3D Scene Video from A Single Image},
author = {Ren, Xuanchi and Wang, Xiaolong},
booktitle = {CVPR},
year = {2022}
}
Update:
:white_check_mark: Release pretrained model for Matterport 3D
:black_square_button: Release pretrained model for RealEstate
Contents
Introduction
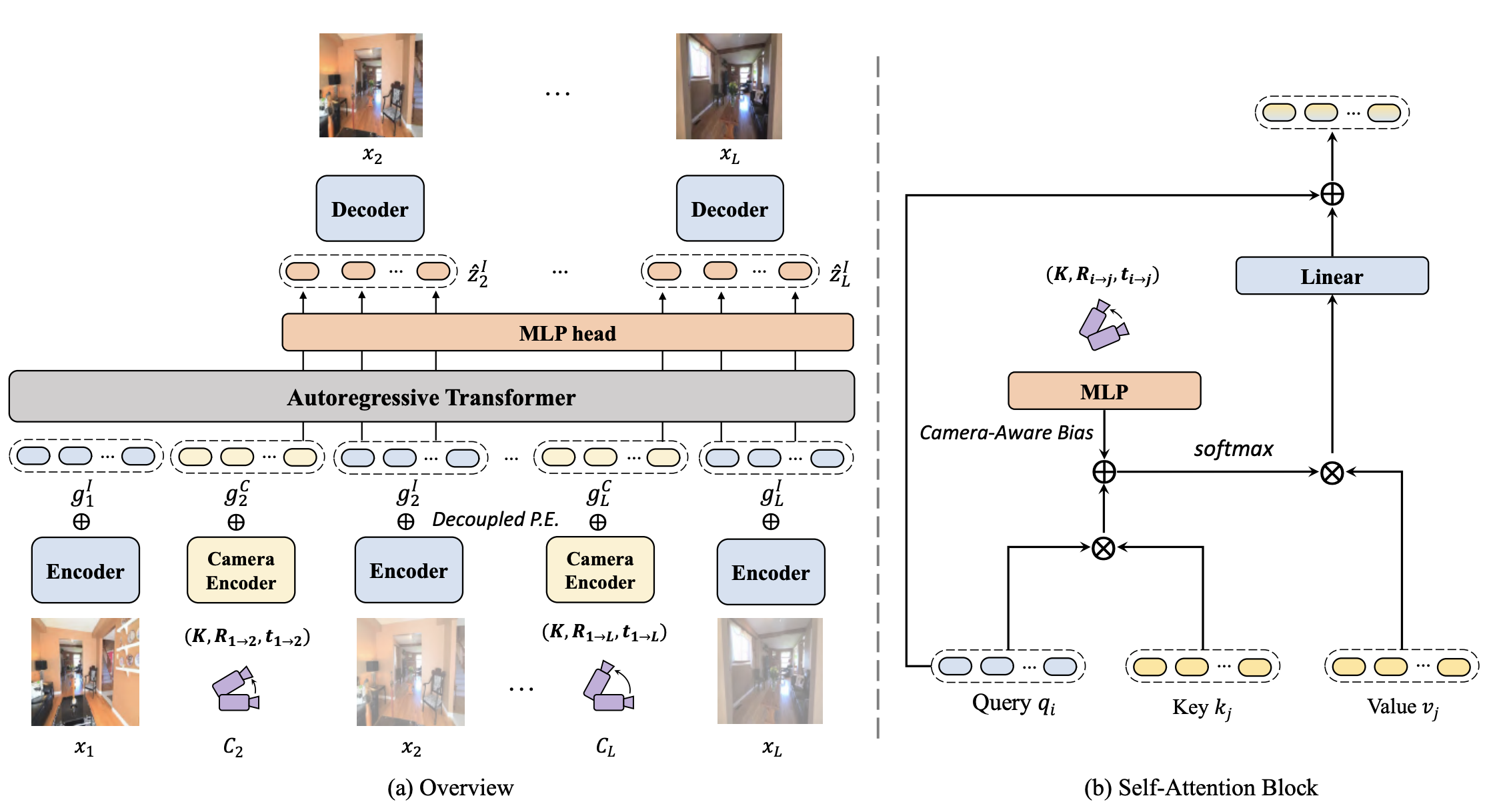 In this paper, we propose a novel approach to synthesize a consistent long-term video given a single scene image and a trajectory of large camera motions. Our approach utilizes an autoregressive Transformer to perform sequential modeling of multiple frames, which reasons the relations between multiple frames and the corresponding cameras to predict the next frame. To facilitate learning and ensure consistency among generated frames, we introduce a locality constraint based on the input cameras to guide self-attention among a large number of patches across space and time.
In this paper, we propose a novel approach to synthesize a consistent long-term video given a single scene image and a trajectory of large camera motions. Our approach utilizes an autoregressive Transformer to perform sequential modeling of multiple frames, which reasons the relations between multiple frames and the corresponding cameras to predict the next frame. To facilitate learning and ensure consistency among generated frames, we introduce a locality constraint based on the input cameras to guide self-attention among a large number of patches across space and time.
Installation
- Clone the repository:
git clone https://github.com/xrenaa/Look-Outside-Room
cd Look-Outside-Room
python scripts/download_vqmodels.py
- Dependencies:
conda env create -f environment.yaml
conda activate lookout
pip install opencv-python ffmpeg-python matplotlib tqdm omegaconf pytorch-lightning einops importlib-resources imageio imageio-ffmpeg numpy-quaternion
Data preparation
Matterport 3D (this could be tricky):
-
Quick Access: To enable quick access, we also provide some samples here (around 90G). You can download and place it under
/MP3D/test. -
Install habitat-api and habitat-sim. You need to use the following repo version (see this SynSin issue for details):
- habitat-sim: d383c2011bf1baab2ce7b3cd40aea573ad2ddf71
- habitat-api: e94e6f3953fcfba4c29ee30f65baa52d6cea716e
-
Download the models from the Matterport3D dataset and the point nav datasets. You should have a dataset folder with the following data structure:
root_folder/
mp3d/
17DRP5sb8fy/
17DRP5sb8fy.glb
17DRP5sb8fy.house
17DRP5sb8fy.navmesh
17DRP5sb8fy_semantic.ply
1LXtFkjw3qL/
...
1pXnuDYAj8r/
...
...
pointnav/
mp3d/
...
- Walk-through videos: We use a
get_action_shortest_pathfunction provided by the Habitat navigation package to generate episodes of tours of the rooms.
python scripts/create_mp3d_dataset_train.py
python scripts/create_mp3d_dataset_test.py
RealEstate10K:
- Download the dataset from RealEstate10K.
- Download videos from RealEstate10K dataset, decode videos into frames. You might find the RealEstate10K_Downloader written by cashiwamochi helpful. Organize the data files into the following structure:
$ROOT/RealEstate10K
train/
0000cc6d8b108390.txt
00028da87cc5a4c4.txt
...
test/
000c3ab189999a83.txt
000db54a47bd43fe.txt
...
$ROOT/dataset
train/
0000cc6d8b108390/
52553000.jpg
52586000.jpg
...
00028da87cc5a4c4/
...
test/
000c3ab189999a83/
...
- To prepare the
$SPLITsplit of the dataset ($SPLITbeing one oftrainandtestfor RealEstate ) in$ROOT, run the following within thescriptsdirectory:
python sparse_from_realestate_format.py --txt_src ${ROOT/RealEstate10K}/${SPLIT} --img_src ${ROOT/dataset}/${SPLIT} --spa_dst ${ROOT/sparse}/${SPLIT}
Pre-trained models:
- Pre-trained model (Matterport3D): Link. You can place it under
experiments/mp3d/{your_name}. - Pre-trained model (RealEstate10K) (To Do)
Training:
By default, the training scripts are designed for 4*32G GPUs. You can adjust the hyperparameters based on your machine.
Matterport 3D:
- Train the mdoel:
python -m torch.distributed.launch --nproc_per_node=4 --master_port=14900 main.py --dataset mp3d --name exp_1 --base ./configs/mp3d/mp3d_16x16_sine_cview_adaptive.yaml --data-path /MP3D/train
- Finetune the model by error accumulation:
python -m torch.distributed.launch --nproc_per_node=4 --master_port=14900 error_accumulation.py --dataset mp3d --name exp_1_error --base ./configs/mp3d/mp3d_16x16_sine_cview_adaptive_error.yaml --data-path /MP3D/train
RealEstate10K:
- Train the mdoel:
python -m torch.distributed.launch --nproc_per_node=4 --master_port=14900 main.py --dataset realestate --name exp_1 --base ./configs/realestate/realestate_16x16_sine_cview_adaptive.yaml --data-path $ROOT
- Finetune the model by error accumulation:
python -m torch.distributed.launch --nproc_per_node=4 --master_port=14900 error_accumulation.py --dataset realestate --name exp_1_error --base ./configs/realestate/realestate_16x16_sine_cview_adaptive_error.yaml --data-path $ROOT
Evaluation:
Matterport 3D:
Generate and evaluate the synthesis results:
python ./evaluation/evaluate_mp3d.py --len 21 --video_limit 100 --base mp3d_16x16_sine_cview_adaptive --exp exp_1_error --data-path /MP3D/test
RealEstate10K:
Generate and evaluate the synthesis results:
python ./evaluation/evaluate_realestate.py --len 21 --video_limit 200 --base realestate_16x16_sine_cview_adaptive --exp exp_1_error --data-path $ROOT
Credits
This repo is mainly based on https://github.com/CompVis/geometry-free-view-synthesis.
Data generator of Matterport 3D is based on: https://github.com/facebookresearch/synsin.
Evaluation metircs are based on: https://github.com/zlai0/VideoAutoencoder.