Awesome
$ epr
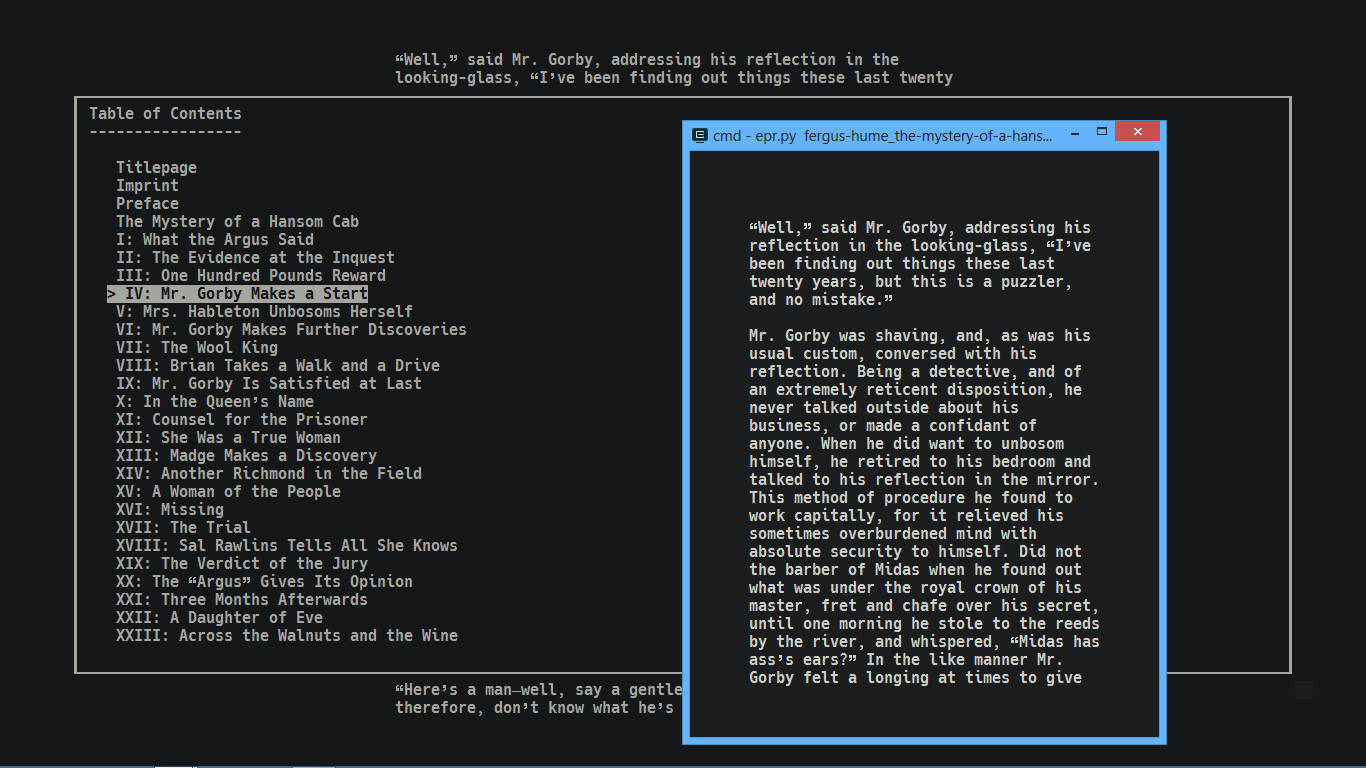
Terminal/CLI Epub reader written in Python 3.6 with features:
- Remembers last read file (just run
eprwithout any argument) - Remembers last reading state for each file (per file saved state written to
$HOME/.config/epr/configor$HOME/.eprrespectively depending on availability) - Adjustable text area width
- Adaptive to terminal resize
- Supports EPUB3 (no audio support)
- Secondary vim-like bindings
- Supports opening images
- Dark/Light colorscheme (depends on terminal color capability)
Limitations
- Minimum width: 22 cols
- Supports regex search only
- Supports only horizontal left-to-right text
- Currently, only supports language with latin alphabet (see issue30)
- Doesn't support hyperlinks
- <sup>Superscript</sup> and <sub>subscript</sub> displayed as
^{Superscript}and_{subscript}. - Some known issues mentioned below
Dependencies
- Windows:
windows-curses
Installation
-
Via PyPI
$ pip3 install epr-reader -
Via Pip+Git
$ pip3 install git+https://github.com/wustho/epr.git -
Via Homebrew for macOS or Linux
$ brew install epr -
Via Chocolatey
Maintained by cybercatgurrl
$ choco install epr -
Via AUR
Maintained by jneidel
$ yay -S epr-git -
Manually
Clone this repo, tweak
epr.pyas much as you see fit, rename it toepr, make it executable and put it somewhere inPATH.
Checkout epy!
It's just a fork of this epr with little more features:
- Formats supported: epub, epub3, fb2, mobi, azw3, url.
- Reading progress percentage
- Bookmarks
- External dictionary integration
- Table of contents scheme like regular ebook reader
- Inline formats: bold and italic (depend on terminal and font capability. Italic only supported in python>=3.7)
- Text-to-Speech (with additional setup)
- Page flip animation
- Seamless between chapter
Install it with:
$ pip3 install git+https://github.com/wustho/epy
Quickly Read from History
Rather than invoking epr /path/to/file each time you are going to read, you might find it easier to do just epr STRINGS.
Example:
$ epr dumas count mont
If STRINGS is not any file, epr will choose from reading history, best matched path/to/file with those STRINGS. So, the more STRINGS given the more accurate it will find.
Run epr -r to show list of all reading history.
Opening an Image
Just hit o when [IMG:n] (n is any number) comes up on a page. If there's only one of those, it will automatically open the image using viewer, but if there are more than one, cursor will appear to help you choose which image then press RET to open it and q to cancel.
Colorscheme
This is just a simple colorscheme involving foreground dan background color only, no syntax highlighting.
You can cycle color between default terminal color, dark or light respectively by pressing c.
You can also switch color to default, dark or light by pressing 0c, 1c or 2c respectively.
Customizing dark/light colorscheme needs to be done inside the source code by editing these lines:
# colorscheme
# DARK/LIGHT = (fg, bg)
# -1 is default terminal fg/bg
DARK = (252, 235)
LIGHT = (239, 223)
To see available values assigned to colors, you can run this one-liner on bash:
$ i=0; for j in {1..16}; do for k in {1..16}; do printf "\e[1;48;05;${i}m %03d \e[0m" $i; i=$((i+1)); done; echo; done
Known Issues
-
Search function can't find occurrences that span across multiple lines
Only capable of finding pattern that span inside a single line, not sentence. So works more effectively for finding word or letter rather than long phrase or sentence.
As workarounds, You can increase text area width to increase its reach or dump the content of epub using
-doption, which will dump each paragraph into a single line separated by empty line (or lines depending on the epub), to be later piped intogrep,rgetc. Pretty useful to find book quotes.Example:
# to get 1 paragraph before and after a paragraph containing "Overdue" $ epr -d the_girl_next_door.epub | grep Overdue -C 2 -
Some TOC issues (Checkout
epyif you're bothered with these issues):-
"-" chapters in TOC
This happens because not every chapter file (inside some epubs) is given navigation points. Some epubs even won't let you navigate between chapter, thus you'll find all chapters named as "-" using
eprfor these kind of epubs. -
Skipped chapters in TOC
Example:
Table of Contents ----------------- 1. Title Page 2. Chapter I 3. Chapter VThis happens because Chapter II to Chapter IV is probably in the same file with Chapter I, but in different sections, e. g.
ch000.html#section1andch000.html#section2.But don't worry, you should not miss any part to read. This just won't let you navigate to some points using TOC.
-
Sometimes page flipping itself to new chapter when scrolling
This might be disorienting. To avoid this issue, you can use
epyinstead which fixed this issue by setting its configSeamlessBetweenChapters.
-