Awesome
KDTree
Description
3D KDTree for Unity, with fast construction and fast & thread-safe querying, with minimal memory garbage.
It was designed:
- to be working with Unity Vector3 structs, but can be modified to work with any other 3D (or 2D & 4D or higher) struct/arrays
- for speedy & light Construction & Reconstruction,
- to be light on memory, everything is pooled,
- for fast querying,
- queryable from multiple threads (thread-safe),
Query modes:
- K-Nearest
- Closest point query
- Radius query
- Interval query
How to use
Construction
First you need some array of points.
Example:
Vector3[] pointCloud = new Vector3[10000];
for(int i = 0; i < pointCloud.Length; i++)
pointCloud[i] = Random.insideUnitSphere;
Then build the tree out of it. Note that original pointCloud shouldn't change, since tree is referencing it!
Note: Higher maxPointsPerLeafNode makes construction of tree faster, but querying slower. And true is inverse: Lower maxPointsPerLeafNode makes construction of tree slower, but querying faster.
int maxPointsPerLeafNode = 32;
KDTree tree = new KDTree(pointCloud, maxPointsPerLeafNode);
Reconstruction
If you wish to update points and reconstruct tree, you do it like this:
for(int i = 0; i < tree.Count; i++) {
tree.Points[i] += Func(tree.Points[i]);
}
tree.Rebuild();
Such rebuilding will be with zero GC impact.
Other functions for rebuilding (data will be copied from array/list, not reference!).
public void Build(Vector3[] newPoints, int maxPointsPerLeafNode = -1);
public void Build(List<Vector3> newPoints, int maxPointsPerLeafNode = -1);
Querying
Now that tree has been constructed, make a KDQuery object.
Note: if you wish to do querying from multiple threads, then each own thread should have it's own KDQuery object.
Query.KDQuery query = new Query.KDQuery();
For most query methods you need pre-initialized results list & reference to tree that you wish to query. Results list will contain indexes for pointCloud array.
List should be cleared; but it's not necesary to clear it (if you wish to do multiple queries), but this way you will have duplicate indexes.
Query objects should be re-used, since it pools everything - to avoid unnecesarry allocations and deallocations.
List<int> results = new List<int>();
// spherical query
query.Radius(tree, position, radius, results);
// returns k nearest points
query.KNearest(tree, position, k, results);
// bounds query
query.Interval(tree, min, max, results);
// closest point query
query.ClosestPoint(tree, position, results);
Post Query
If you wish to do something with query results, then use it like this:
for(int i = 0; i < results.Count; i++) {
Vector3 p = pointCloud[results[i]];
Draw(p);
}
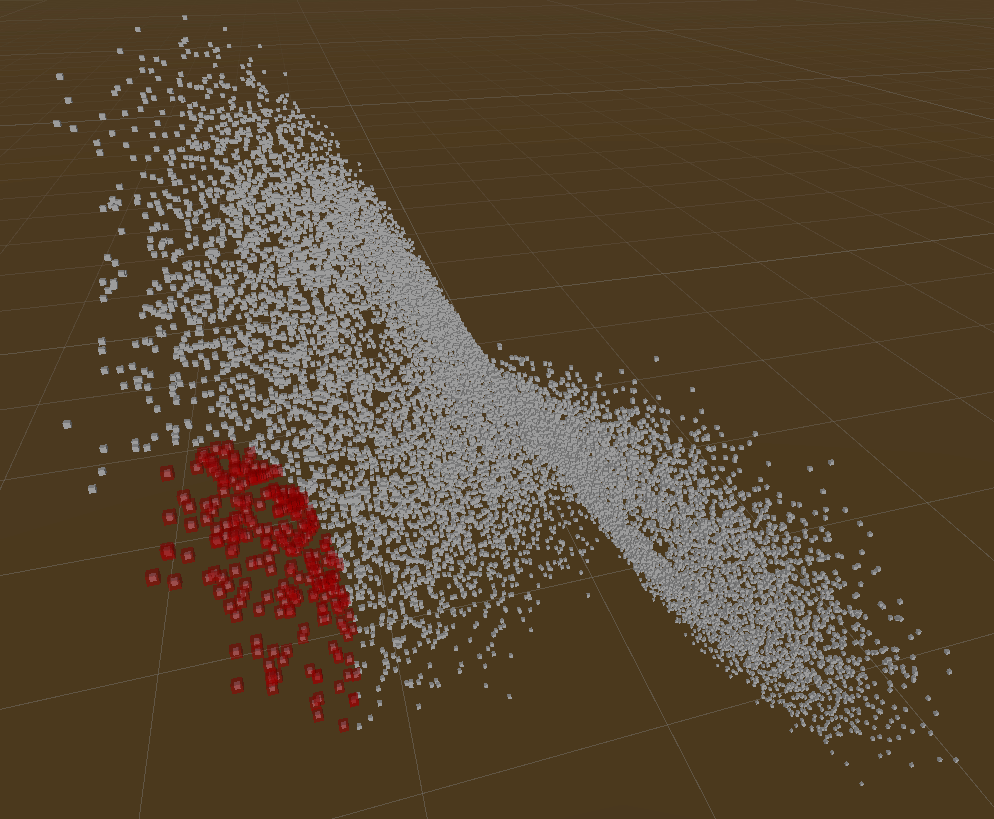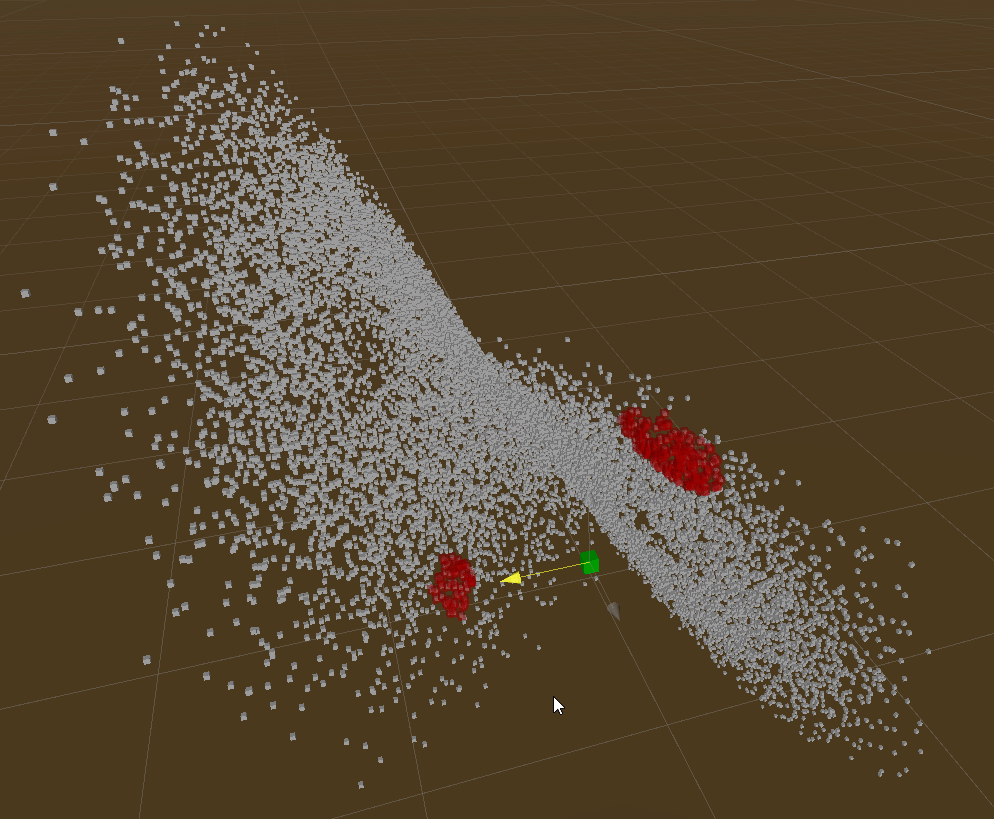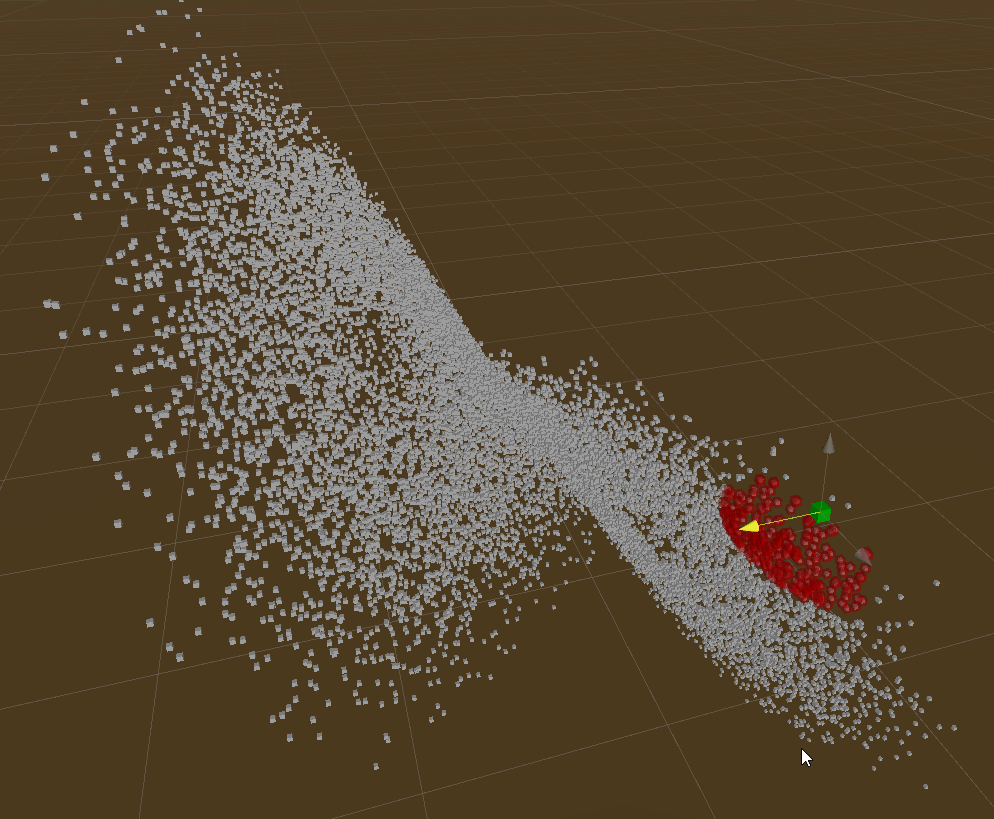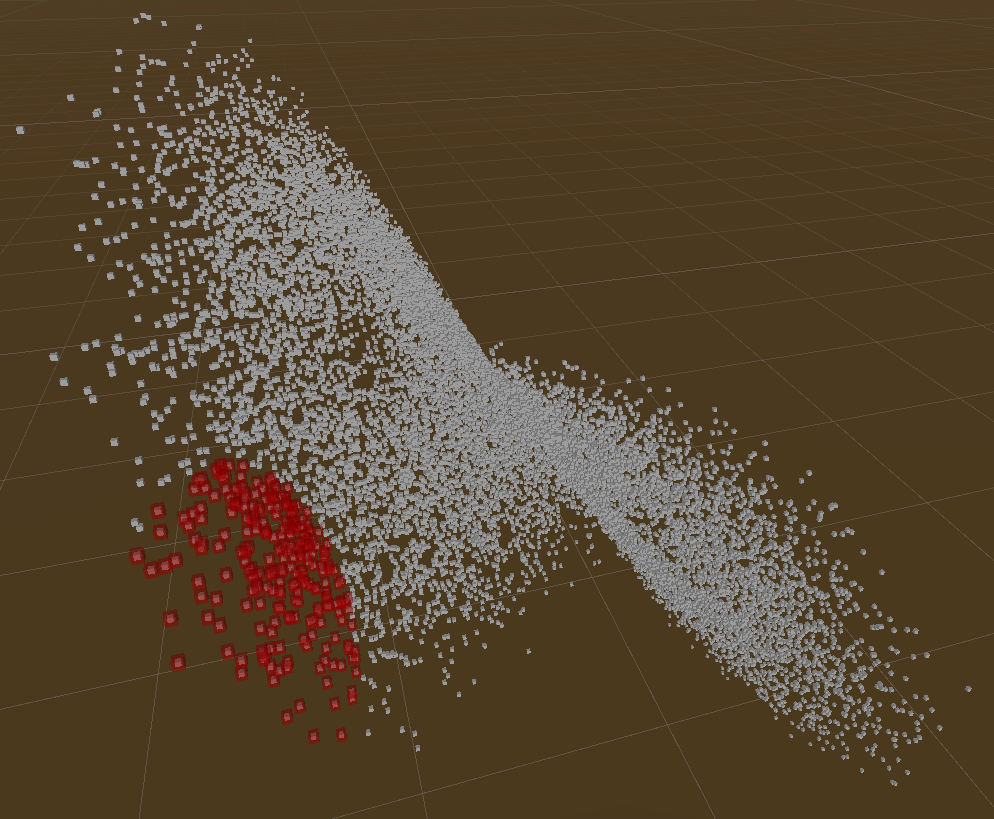
Demos
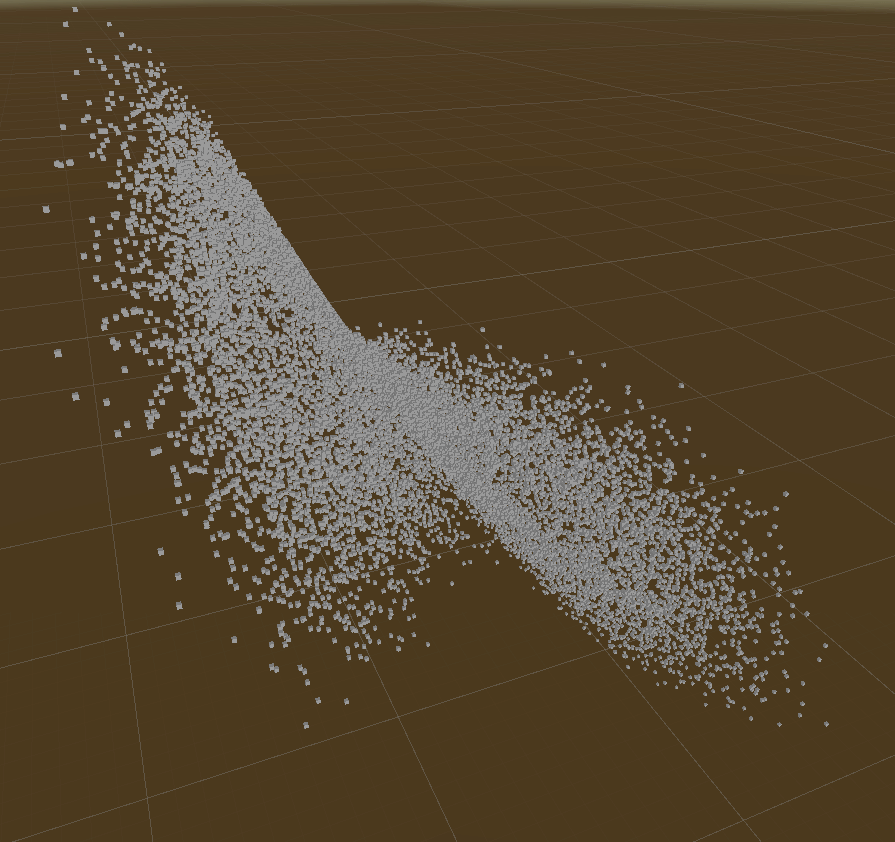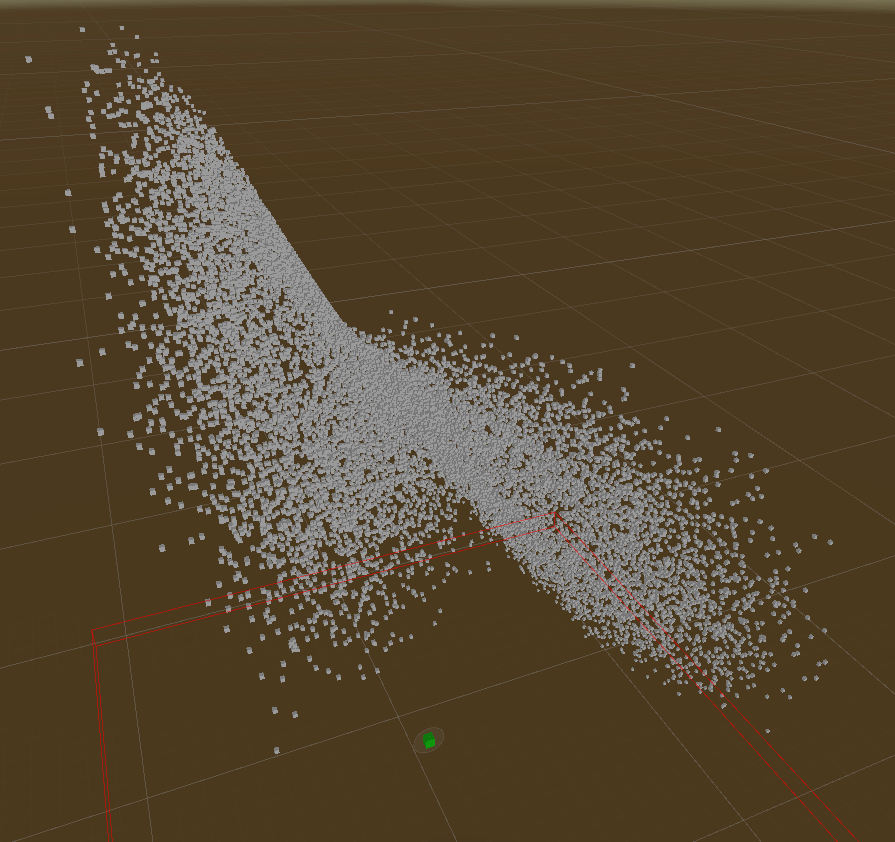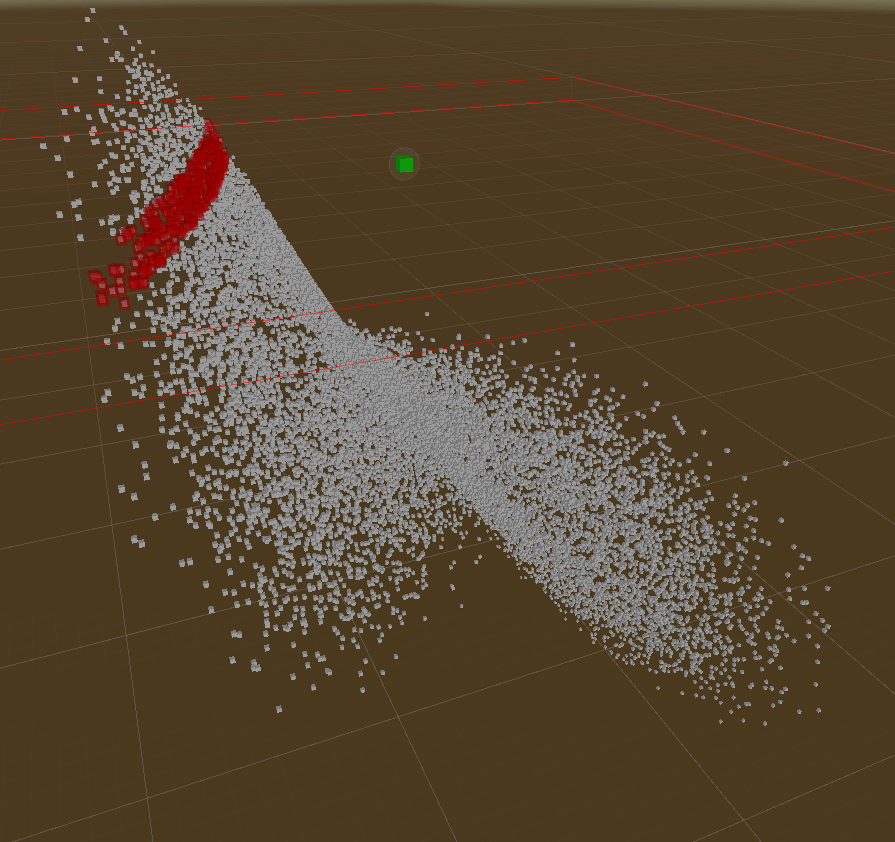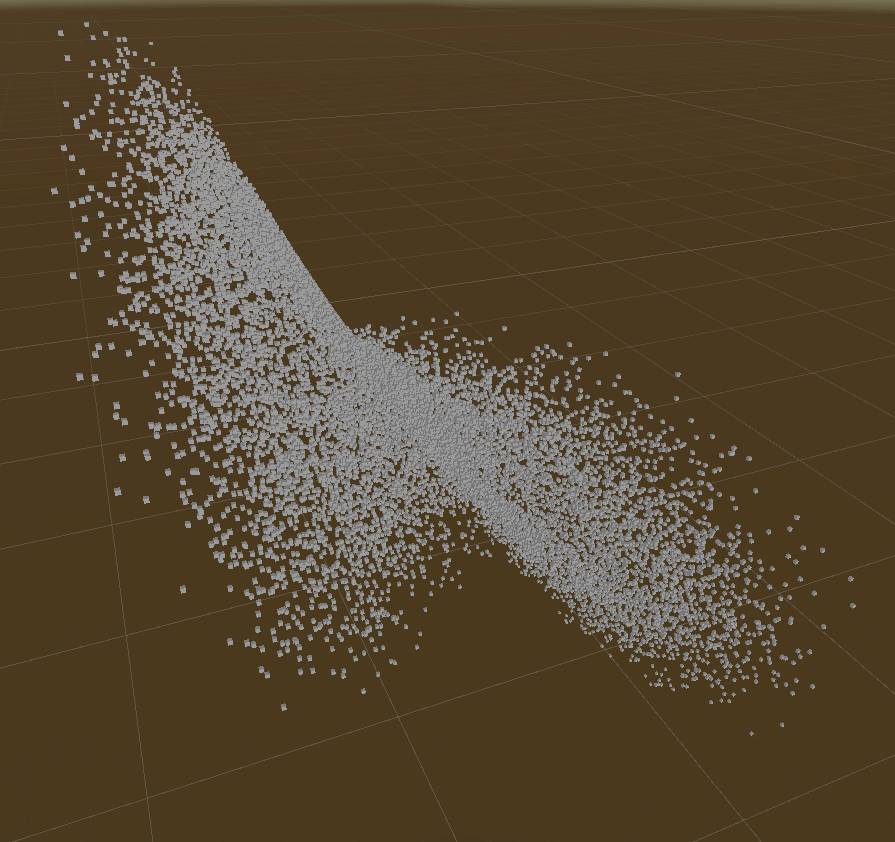
Those demos show rebuilding tree & querying of Live Lorenz Attractor point cloud.
Drawing traversal nodes of KNearest Query

KNearest Query
Radius Query
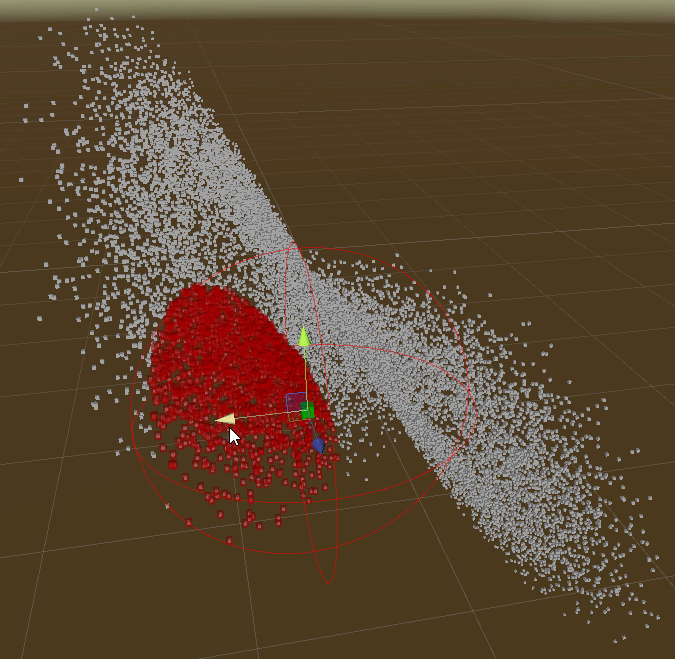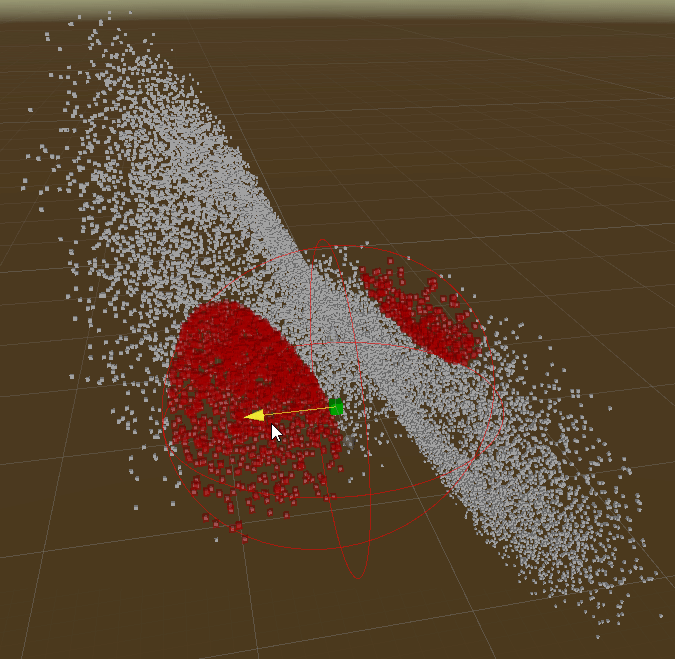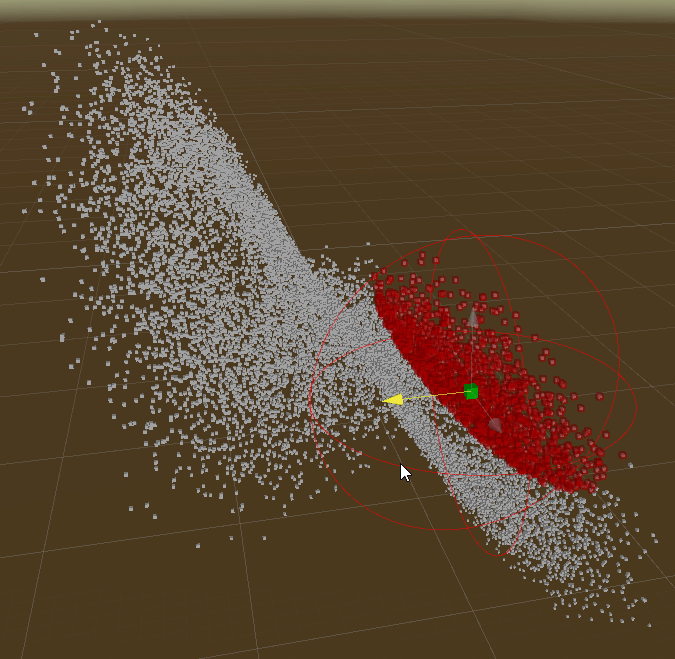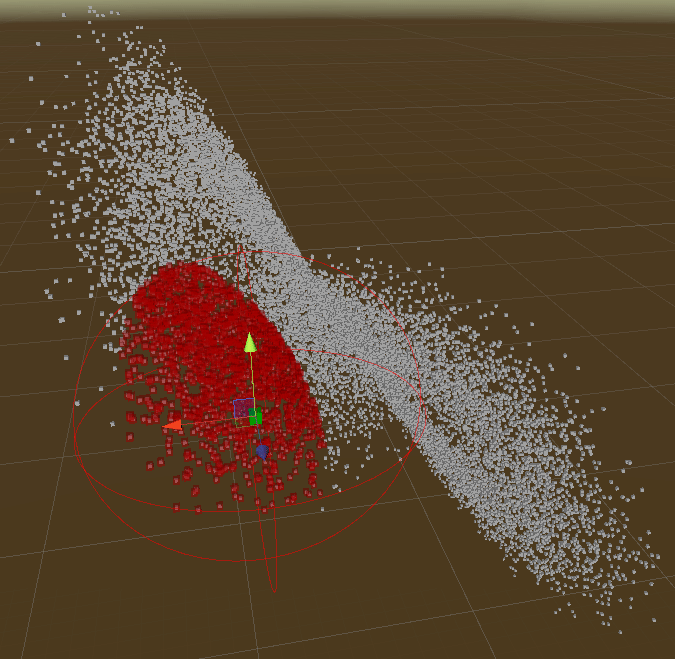
Interval/Bounds Query
How it works?
Construction
Uses internal permutation array, so it doesn't modify original data array. Permutation is identity array at first (arr[i] = i), then gets sorted down the line. Hoare partitioning enables to sort permutation array inplace. (Quicksort uses hoare partitioning, too). Mid-point rule is used for node splitting - not the most optimal split but makes construction much faster.
KDQuery
All traversal nodes are pooled in internal queue. Uses binary heap for KNearest query. Heaps for all sizes are pooled inside KDQuery object.
Sources
https://www.cs.umd.edu/~mount/Papers/cgc99-smpack.pdf - Paper about slidding mid-point rule for node splitting.
Jobified KDTree
There is heavily modified version of this source, that runs on Unity Job System (not made by me). Also note that tests are wrong - you are supposed to reuse Query objects, not always create new ones, hence the GC. https://github.com/ArthurBrussee/KNN