Awesome
Akkalat, Wafer-Scale GPU Simulation Infrastructure
Akkalat is the infrastructure to simulate wafer-scale GPUs, based on the architecture-agnostic simulator framework Akita.
The simulator targeted on Cerebras Wafer-Scale Engines and supported a variety of OpenCL benchmarks.
In the latest stable Akkalat v3, we devised a tile-based hardware paradigm, which can highly scale up compute resources at CU(Compute Unit)-level. Each tile consists of optimized L1 caches and TLBs, distributed memory and other basic components like reorder buffers and address translators. The tiles are connected to a Network-on-Chip (NoC) for communication.
The further performance optimization and hardware designs could be assisted with Vis4Mesh, a visualization tool developed later for mesh Network-on-Chip research.
Build
git clone git@github.com:ueqri/akkalat.git
cd akkalat/samples/fir
go build
# Case 1: run FIR in 64x64 mesh without NoC tracing
./fir -width=64 -height=64 -length=100000 -verify -timing
# Case 2: run FIR with tracing and Vis4Mesh,
# and customize the env to meet your demands
export AKITA_TRACE_PASSWORD=[RedisPassword]
export AKITA_TRACE_IP=127.0.0.1
export AKITA_TRACE_PORT=6379
export AKITA_TRACE_REDIS_DB=0
./fir -width=64 -height=64 -length=100000 -verify -timing -trace-vis
# Then follow Vis4Mesh tutorial to run visualization
Note: many Akita libraries used here are under development, therefore please stick with the latest commit of the correct branches for go packages util, noc, and mgpusim (as described in go.mod).
# Assume the work directory is inside akkalat/
cd ..
git clone --single-branch -b v2 git@gitlab.com/akita/util
git clone --single-branch -b 9-task-tracing-for-networks git@gitlab.com/akita/noc
git clone --single-branch -b 90-command-processor-reuses-todma-sender-port git@gitlab.com/akita/mgpusim
Benchmark
We support the following benchmarks the evaluate the performance.
| AMD APP SDK | DNN Mark | HeteroMark | Polybench | Rodinia | SHOC |
|---|---|---|---|---|---|
| Bitonic Sort | MaxPooling | AES | ATAX | Needleman-Wunsch | BFS |
| Fast Walsh Transform | ReLU | FIR | BICG | FFT | |
| Floyd-Warshall | KMeans | SPMV | |||
| Matrix Multiplication | PageRank | Stencil2D | |||
| Matrix Transpose | |||||
| NBody | |||||
| Simple Covolution |
Performance
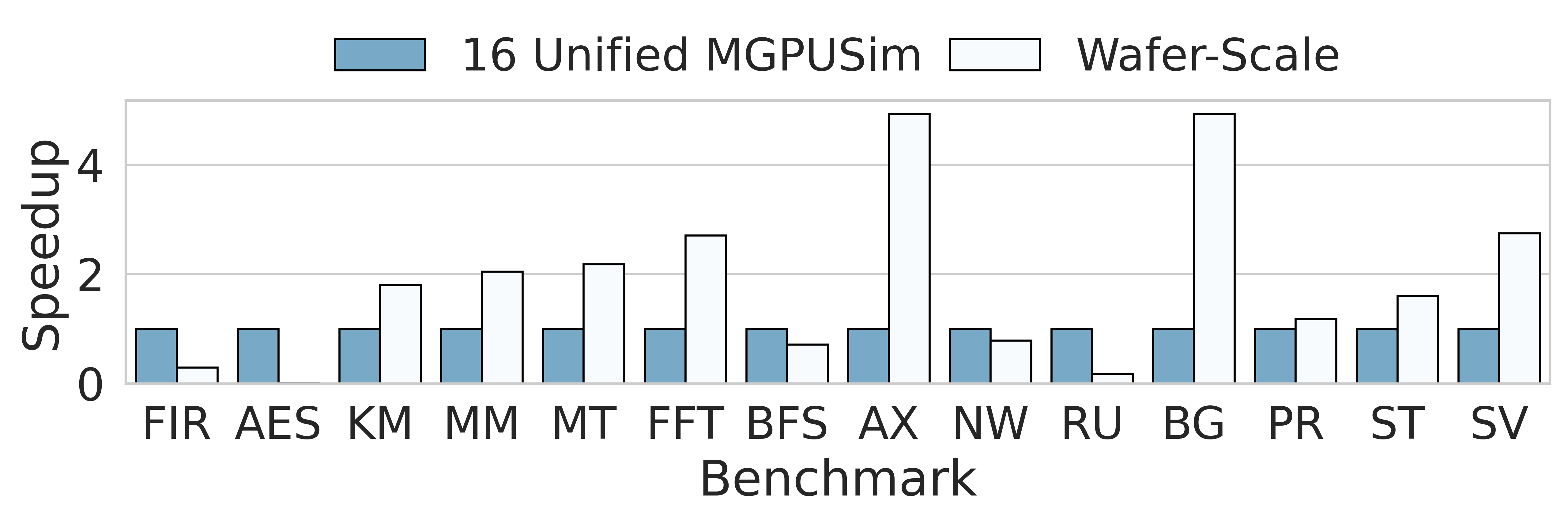
We demonstrate a 32x32 wafer-scale GPU using akkalat. Compared to 16 unified AMD R9Nano GPUs(with the same numbers of compute units) modeled by MGPUSim, the wafer-scale outperforms in many workloads and achieves up-to 4 speedup in Polybench.
This figure is generated full-automatically by another self-developed tool akitaplot, feel free to try it :-). And the detailed metrics of this test could also download in that repo, link.
Publications
- Chris Thames, Hang Yan, and Yifan Sun. Understanding wafer-scale GPU performance using an architectural simulator. In Proceedings of the 14th Workshop on General Purpose Processing Using GPU (GPGPU '22). April 2022.