Awesome
JSON Voorhees
Yet another JSON library for C++. This one touts new C++11 features for developer-friendliness, an extremely slow-speed parser and no dependencies beyond a compliant compiler. If you love Doxygen, check out the documentation.
Features include (but are not necessarily limited to):
- Simple
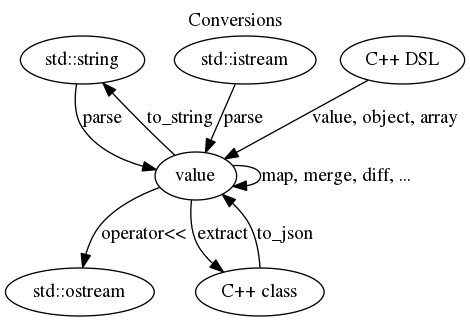
- A
valueshould not feel terribly different from a C++ Standard Library container - Write valid JSON with
operator<< - Simple JSON parsing with
parse - Reasonable error messages when parsing fails
- Full support for Unicode-filled JSON (encoded in UTF-8 in C++)
- A
- Efficient
- Minimal overhead to store values (a
valueis 16 bytes on a 64-bit platform) - No-throw move semantics wherever possible
- Minimal overhead to store values (a
- Easy
- Convert a
valueinto a C++ type usingextract<T> - Encode a C++ type into a value using
to_json
- Convert a
- Safe
- In the best case, illegal code should fail to compile
- An illegal action should throw an exception
- Almost all utility functions have a strong exception guarantee
- Stable
- Worry less about upgrading -- the API and ABI will not change out from under you
- Documented
- Consumable by human beings
- Answers questions you might actually ask
- Compiler support
- GCC (4.8+)
- Clang++ (3.3+)

![]()
![]()
Compile and Install
JSON Voorhees uses CMake as the automatic configuration software.
On Linux or Mac OSX, if you have boost, cmake, g++ and make installed, simply:
$> cmake .
$> make
$> sudo make install
If you want to customize your compilation or installation, see the options in CMakeLists.txt for easy-to-use
configuration options.
If you are on Windows, you can also use CMake if you want.
However, it is probably easier to use the provided Visual Studio project files in msvc/vs2015 to get going.
Hitting F5 should perform a NuGet restore, then compile and run all the unit tests.
Arch Linux
If you use Arch Linux, JSON Voorhees is easily installable via AUR.
The "latest stable" is called json-voorhees, while there is a "close
to tip" package called json-voorhees-git.
With Arch, installation is as easy as yaourt json-voorhees!
Future
Future planned features can be found on the issue tracker.
License
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.
Miscellaneous
Compiler Support
- Supported
- GCC 4.8+
- Clang 3.3+
- Experimental
- MSVC 14.0 CTP5+ (Visual C++ 2015)
Versioning
Like every software system ever, JSON Voorhees describes versions in 3 part semantic versioning:
${major}.${minor}.${patch}.
The version components changing have very specific meanings:
major: There are no guarantees whatsoever across major releases.minor: For a given minor release, all code is forward-compatible source-code compliant. That means code written against version 1.1 can be recompiled against version 1.4 and continue to work. No guarantees are made for going backwards (version 1.4 might have added new functions).patch: Code is ABI-compatible across patch. Library A built against JSON Voorhees 1.2.4 should be able to pass ajsonv::valueto library B built against JSON Voorhees 1.2.9. Any change to publicly-visible data structures or calling conventions will correspond to a bump in the minor version.
The preceding statements are not true if the version is suffixed with -preN.
These values are "pre-release" and are allowed to do whatever they feel like before a release.
When developing code, follow this simple workflow to determine which version components need to change:
- Will this change force users to change their source code?
If yes, bump the
majorversion. - Will this change force users to recompile to continue to work?
If yes, bump the
minorversion. - Will this change the behavior in any way?
If yes, bump the
patchversion. - Did I only change comments or rearrange code positioning (indentation, etc)? If yes, you do not need to update any part of the version.
- Did I miss something? Yes. Go back to #1 and try again.
Character Encoding
This library assumes you really love UTF-8.
When parsing JSON, this library happily assumes all sequences of bytes from C++ are UTF-8 encoded strings; it assumes
you also want UTF-8 encoded strings when converting from JSON in C++ land; and it assumes the non-ASCII contents of a
source string should be treated as UTF-8.
If you wish to use some other encoding format for your std::string, there is no convenient way to do that beyond
conversion at every use site.
There is a proposal to potentially address this.
On output, the system takes the "safe" route of using the numeric encoding for dealing with non-ASCII std::strings.
For example, the std::string for "Travis Göckel" ("Travis G\xc3\xb6ckel") will be encoded in JSON as
"Travis G\u00f6ckel", despite the fact that the character 'ö' is the most basic of the Unicode Basic Multilingual
Planes.
This is generally considered the most compatible option, as (hopefully) every transport mechanism can gracefully
transmit ASCII character sequences without molestation.
The drawback to this route is a needlessly lengthened resultant encoding if all components of the pipeline gracefully
deal with UTF-8.
There is an outstanding issue to address this shortcoming.
F.A.Q.
What makes JSON Voorhees different from the other C++ JSON libraries?
JSON Voorhees was written for a C++ programmer who wants to be productive in this modern world. What does that mean? There are a ton of JSON libraries floating around touting how they are "modern" C++ and so on. But who really cares? JSON Voorhees puts the focus more on the resulting C++ than any "modern" feature set. This means the library does not skip on string encoding details like having full support for UTF-8. Are there "modern" features? Sure, but this library is not meant to be a gallery of them -- a good API should get out of your way and let you work.
Another thing JSON Voorhees does not attempt to do is be a lightweight library; in fact, it wants to be the kitchen sink
for anything you want to do in JSON in your C++ application.
This means it is configurable for your
needs.
That said, the library does not depend on strange environment settings, so you can still drop the .cpp and .hpp files
into your own project if you want.
It also includes a powerful serialization framework for converting from JSON into C++ types and back again. There is an extensible Serialization Builder DSL to help you writing your application. The serialization framework was designed with the modern application in mind -- you will like it or your money back!
Why are integer and decimal distinct types?
The JSON specification only has a number type, whereas this library has kind::integer and kind::decimal.
Behavior between the two types should be fairly consistent -- comparisons between two different kinds should behave as
you would expect (assuming you expect things like value(1) == value(1.0) and value(2.0) < value(10)).
If you wish for behavior more like JavaScript, feel free to only use as_decimal().
The reason integer and decimal are not a single type is because of how people tend to use JSON in C++. If you look at projects that consume JSON, they make a distinction between integer and decimal values. Even in specification land, a distinction between the numeric type is pretty normal (for example: Swagger). To ultimately answer the question: integer and decimal are distinct types for the convenience of users.
Why are NaN and INFINITY serialized as a null?
The JSON specification does not have support for non-finite floating-point numbers like NaN and infinity.
This means the value defined with object({ { "nan", std::nan("") }, { "infinity", INFINITY } }) to get serialized as
{ "nan": null, "infinity": null }.
While this seems to constitute a loss of information, not doing this would lead to the encoder outputting invalid JSON
text, which is completely unacceptable (unfortunately, this is a very common mistake in JSON libraries).
If you want to check that there will be no information loss when encoding, use the utility funciton validate.
Why not throw when encoding?
One could imagine the encoder::encode throwing something like an encode_error instead of outputting null to the
stream.
However, that would make operator<< a potentially-throwing operation, which is extremely uncommon and would be very
surprizing (imagine if you tried to log a value and it threw).
Why not throw when constructing the value?
Instead of waiting for encoding time to do anything about the problem, the library could attack the issue at the source
and throw an exception if someone says value(INFINITY).
This was not chosen as the behavior, because non-finite values are only an issue in the string representation, which is
not a problem if the value is never encoded.
You are free to use this JSON library without parse and encode, so it should not prevent an action simply because
someone might use encode.
Why are there so many corruption checks?
If you are looking through the implementation, you will find a ton of places where there are default cases in switch
statements that should be impossible to hit without memory corruption.
This is because it is unclear what should happen when the library detects something like an invalid kind.
The library could assert, but that seems overbearing when there is a reasonable option to fall back to.
Alternatively, the library could throw in these cases, but that leads to innocuous-looking operations like x == y
being able to throw, which is somewhat disconcerning.
This is really helpful! Can I give you money?
I would be Flattr-ed!
With such a cool name, do you have an equally cool logo?
Not really...
