Awesome
GridDiff: Grid Diffusion Models for Text-to-Video Generation, CVPR 2024
This repository is the official implementation of Grid Diffusion Models for Text-to-Video Generation.
GridDiff: Grid Diffusion Models for Text-to-Video Generation <br/> Taegyeong Lee*, Soyeong Kwon*,Taehwan Kim
<br/>
![]()
Abstract
Recent advances in the diffusion models have significantly improved text-to-image generation. However, generating videos from text is a more challenging task than generating images from text, due to the much larger dataset and higher computational cost required. Most existing video generation methods use either a 3D U-Net architecture that considers the temporal dimension or autoregressive generation. These methods require large datasets and are limited in terms of computational costs compared to text-to-image generation. To tackle these challenges, we propose a simple but effective novel grid diffusion for text-to-video generation without temporal dimension in architecture and a large text-video paired dataset. We can generate a high-quality video using a fixed amount of GPU memory regardless of the number of frames by representing the video as a grid image. Additionally, since our method reduces the dimensions of the video to the dimensions of the image, various image-based methods can be applied to videos, such as text-guided video manipulation from image manipulation. Our proposed method outperforms the existing methods in both quantitative and qualitative evaluations, demonstrating the suitability of our model for real-world video generation.
News
- [04-02-2024] README.md
- [08-17-2024] Add video to grid image preprocess code
- [08-18-2024] Add grid image to parquet
- [08-27-2024] Add training code (inter1 and inter)
Approach
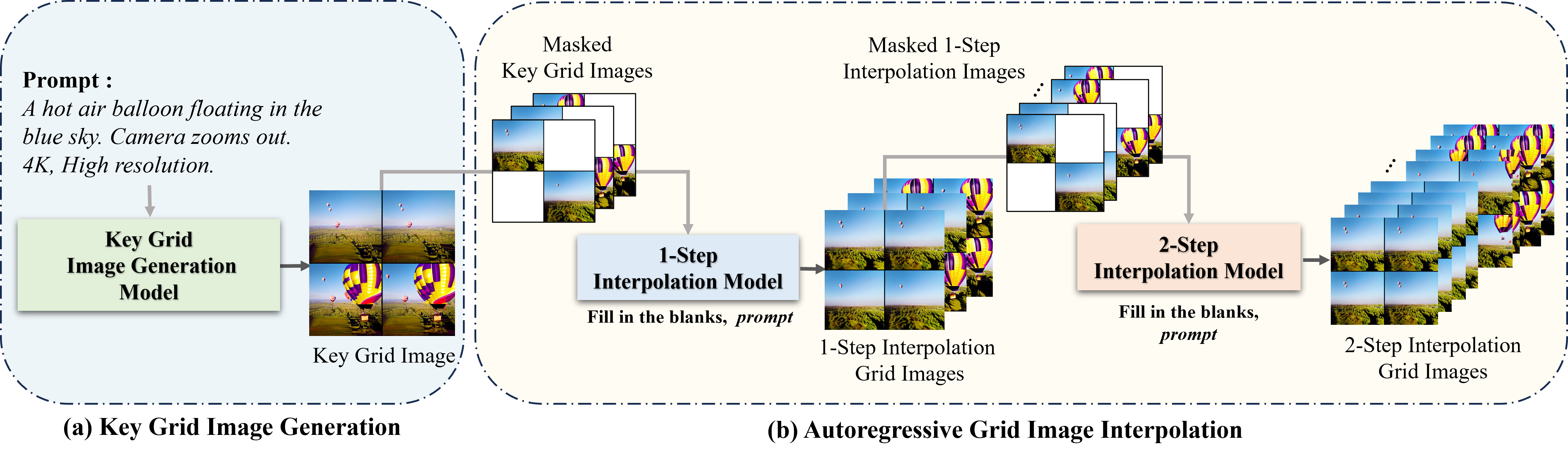
Usage
- We first extract a key frame from the video to construct a key grid image (using preprocess/im2par_inter1/inter2/key, mp42grid_2x2.py files).
Citation
@inproceedings{lee2024grid,
title={Grid Diffusion Models for Text-to-Video Generation},
author={Lee, Taegyeong and Kwon, Soyeong and Kim, Taehwan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={8734--8743},
year={2024}
}