Awesome
1st Place Public Leaderboard Solution for ERC2019
Overview
Although the competition is for recognizing emotion from audio data. You can treat this codebase for a baseline for audio classification in general, I did not make any assumption about the provided data. This is is pipeline
Key features
Preprocessing by converting the audio to Mel Spectrogram.
I used librosa with this config:
- sampling_rate = 16000
- duration = 2 # sec
- hop_length = 125 * duration
- n_mels = 128
Basically, each 128x128 image represents 2 second of audio.
Fully CNN for audio classification
Recently we won a gold medal in Kaggle's Freesound Audio Tagging 2019 and thus most of the architectures were borrowed from there.
The final submission was an ensemble of 4 models. 3 of them were Classifier_M0, Classifier_M2 and Classifier_M3 from our technical report [1]:

Here's what Classifier_M3 looks like:

The other model came from the 7th place solution
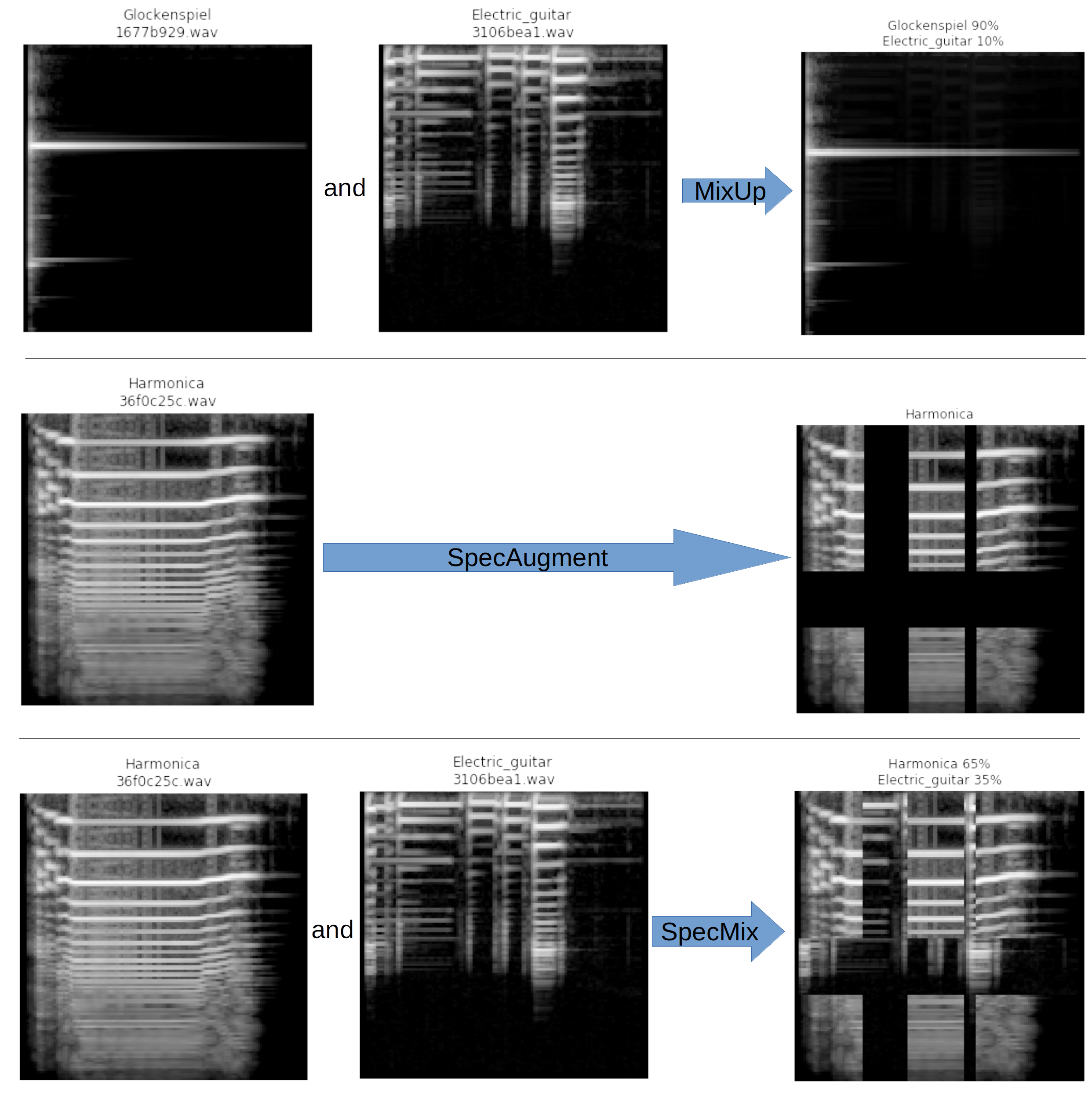
Mixup + SpecAugment (SpecMix)
The most important part of this solution is the augmentation method, as the dataset is very small and pretraining is not allowed.
Augmenting options spectrogram are very limited due to the nature of the data (they are not ordinary images e.g rotating a spectrogram makes no sense). In this work I ultilized Mixup [2] and SpecAugment [3].
This repo by Eric Bouteillon showed a nice explantion of the method:
Training
Preprocessing
To reproduce the Mels data, run the following command:
$python preprocess.py --train_df_path <path-to>/train_label.csv --train_dir <path-to>/Train --test_dir <path-to>/Public_Test --train_output_path ./data/mels_train.pkl --test_output_path ./data/mels_test.pkl
Training
To reproduce the models, run the following commands:
$python train_pred.py --train_df_path <path-to>/train_label.csv --test_dir <path-to>/Public_Test/ --model m0 --logdir models_m0 --output_name preds_m0.npy
$python train_pred.py --train_df_path <path-to>/train_label.csv --test_dir <path-to>/Public_Test/ --model m2 --logdir models_m2 --output_name preds_m2.npy
$python train_pred.py --train_df_path <path-to>/train_label.csv --test_dir <path-to>/Public_Test/ --model m3 --logdir models_m3 --output_name preds_m3.npy
$python train_pred.py --train_df_path <path-to>/train_label.csv --test_dir <path-to>/Public_Test/ --model dcase --logdir models_dcase --output_name preds_dcase.npy