Awesome
Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization
This is the official repository for Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization accepted at WACV 2024. It includes the script to run lip-synchronization at inference time given a filelist of audio-video pairs.
| Abstract | ArXiv | Website | Colab Notebook |
|---|
tl;dr
Diff2Lip: arbitrary speech + face videos → high quality lip-sync.
Applications: movies, education, virtual avatars, (eventually) video conferencing.

Results
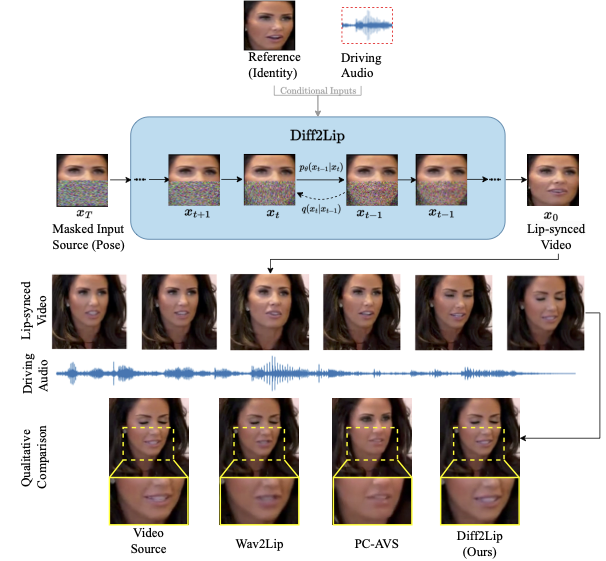
(a) Video Source (b) Wav2Lip (c) PC-AVS (d) Diff2Lip (ours)

Please find more results on our website.
Overview of our approach
- Top : Diff2Lip uses an audio-conditioned diffusion model to generate lip-synchronized videos.
- Bottom: On zooming in to the mouth region it can be seen that our method generates high-quality video frames without suffering from identity loss.
Setting up the environment
conda create -n diff2lip python=3.9
conda activate diff2lip
conda install -c conda-forge ffmpeg=5.0.1
pip install -r requirements.txt
Inference
For inference on VoxCeleb2 dataset we use scripts/inference.sh script which internally calls the python scripts generate.py or generate_dist.py. Set the following variables to run inference:
real_video_root: set this to the base path of your directory containing VoxCeleb2 dataset.model_path: first download the Diff2Lip checkpoint from here, place it incheckpointsdirectory, and set this variable to the checkpoint's path.sample_path: set this to where you want to generate your output.sample_mode: set this to "cross" to drive a video source with a different/same audio source or set it to "reconstruction" to drive the first frame of the video with the same/differnt audio source.NUM_GPUS; controls the number of gpus to be used. If set to greater than 1, it runs the disributed generation.
After setting these variables in the script, inference can be run using the following command:
scripts/inference.sh
Inference on other data
For example if you want to run on LRW dataset, apart from the above arguments you also need to set --is_voxceleb2=False, change variable filelist_recon to dataset/filelists/lrw_reconstruction_relative_path.txt and variable filelist_cross to dataset/filelists/lrw_cross_relative_path.txt. Each line of these filelists contain the relative path of the audio source and the video source separated by a space, relative to the real_video_root variable.
For inference on a single video, set --is_voxceleb2=False and then either (1) filelist can have only one line or (2) set --generate_from_filelist=0 and specify --video_path,--audio_path,--out_path instead of --test_video_dir,--sample_path,--filelist flags in the scripts/inference_single_video.sh script.
Google Colab Notebook
You can try out Diff2Lip on Google Colab Notebook now using this link.
License

Except where otherwise specified, the text/code on <a href="https://github.com/soumik-kanad/diff2lip">Diff2Lip</a> repository by Soumik Mukhopadhyay (soumik-kanad) is licensed under the <a href="https://creativecommons.org/licenses/by-nc/4.0/">Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0)</a>. It can be shared and adapted provided that they credit us and don't use our work for commercial purposes.
Citation
Please cite our paper if you find our work helpful and use our code.
@InProceedings{Mukhopadhyay_2024_WACV,
author = {Mukhopadhyay, Soumik and Suri, Saksham and Gadde, Ravi Teja and Shrivastava, Abhinav},
title = {Diff2Lip: Audio Conditioned Diffusion Models for Lip-Synchronization},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2024},
pages = {5292-5302}
}