Awesome
使用 Unity 进行GPU-Driven Particles Rendering
摘要
现在CPU和GPU都越发强大,在实际绘制中的瓶颈制约的反而更有可能是CPU和GPU之间的带宽,也就是通常所说的受批次制约。在实际中,我们常用合批或者instance的方法来缓解批次的限制。但是合批对材质有限制,instance受限于剔除算法,需要额外地去绘制画面之外的物体。本文简要介绍GPU-Driven Rendering Pipeline,在此基础上用Unity实现粒子系统的GPU-Driven Rendering pipeline简单demo。
简介
GPU-Driven Rendering Pipeline的理解思路是把所有的绘制信息都放在GPU端,由GPU去处理哪些需要绘制,绘制顺序,绘制参数绑定,减少CPU和GPU之间的通讯信息,避免等待,提高绘制效率。
GPU Culling
由GPU进行Culling的核心思路是,GPU去判断一个几何图元可见性比实际去绘制这个图元更加高效。而且因为在GPU端进行可见性判断,可以直接写入到indirect draw call 参数中,无需GPU和CPU的信息交换,既无需再告诉CPU现在drawcall的数量,之间由GPU发出绘制命令。 在GPU端进行culling 有几种方式:
-
GPU Queries: 这种方法主要GPU返回CPU绘制信息,是受限于等待;
-
CPU光栅化检测:慢
-
GPU光栅化检测:得到深度缓存后额外pass,其中GPU不进行颜色绘制,只绘制可见性,既只要有fragment通过测试,就记录该drawcall的可见性信息。弊端是需要额外的可见性检测pass。
-
Hiz方法:本demo使用方法,生成depth buffer的hirachy信息,draw call包围盒与Hiz做检测,通过检测加入到indirect draw 缓存中,否则遗弃这个draw. 本demo所用的Hiz生成采用做传统的mipmap方式简化流程,如果使用wave operation和group memory还可以更进一步优化Hiz的生成。使用Hiz的方式缺点是太过保守,由于Hiz生成太过保守导致还有大量的被遮挡draw被错误地统计到需要绘制的参数中。一种改进方法可以通过在draw覆盖范围更低的level下进行精细的遍历像素,但是这由于GPU culling的思想相悖:GPU去判断一个几何图元可见性比实际去绘制这个图元更加高效。
 上图展示了hiz buffer的mipmap结构。可以看出hiz_buffer是一种保守的可见性判断方法。
上图展示了hiz buffer的mipmap结构。可以看出hiz_buffer是一种保守的可见性判断方法。
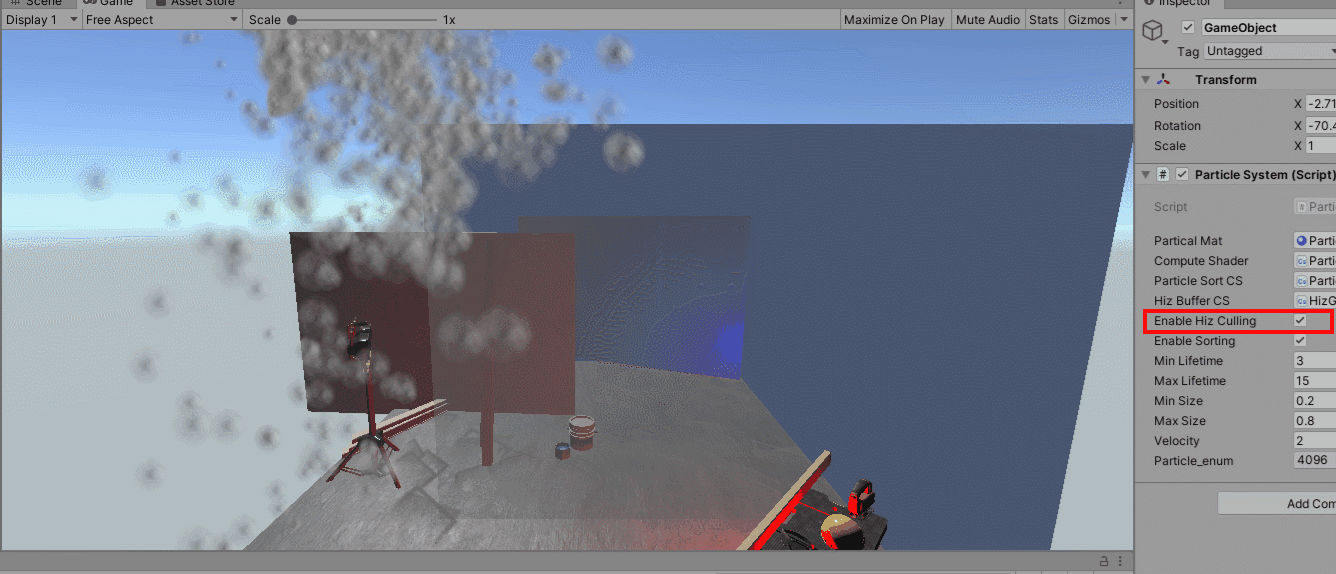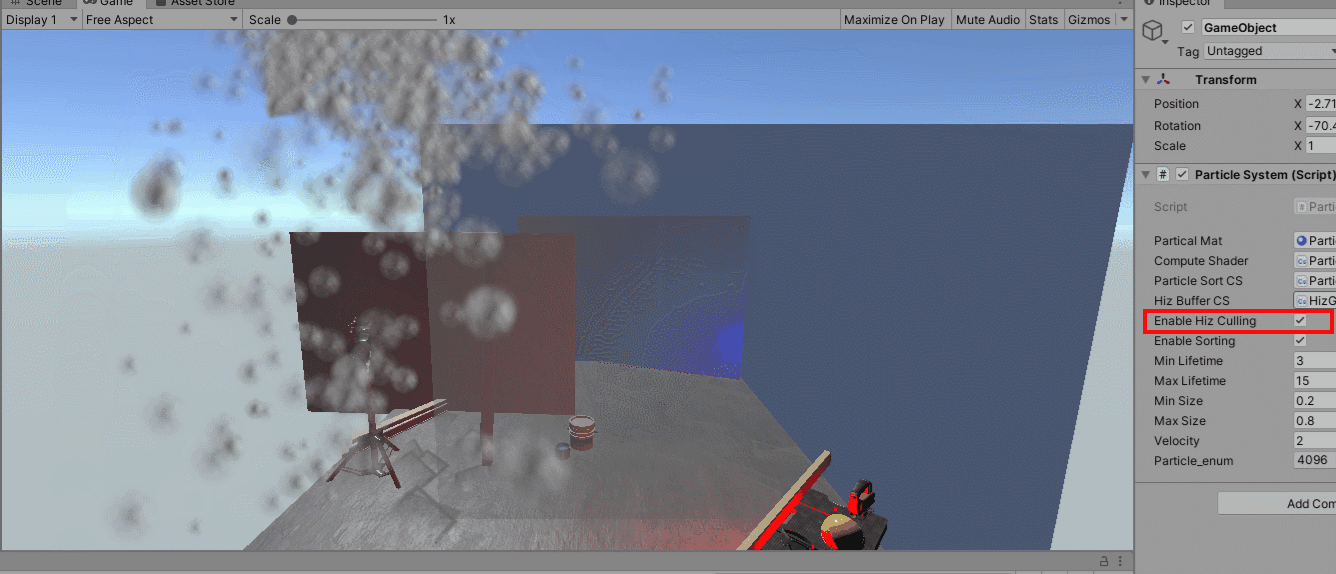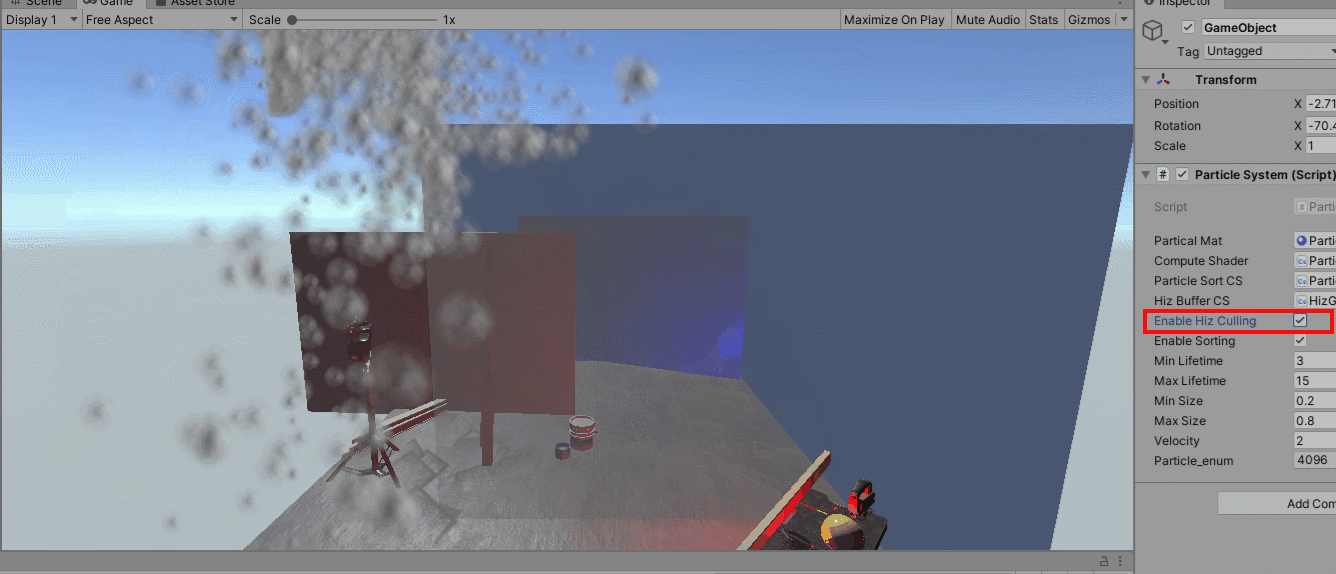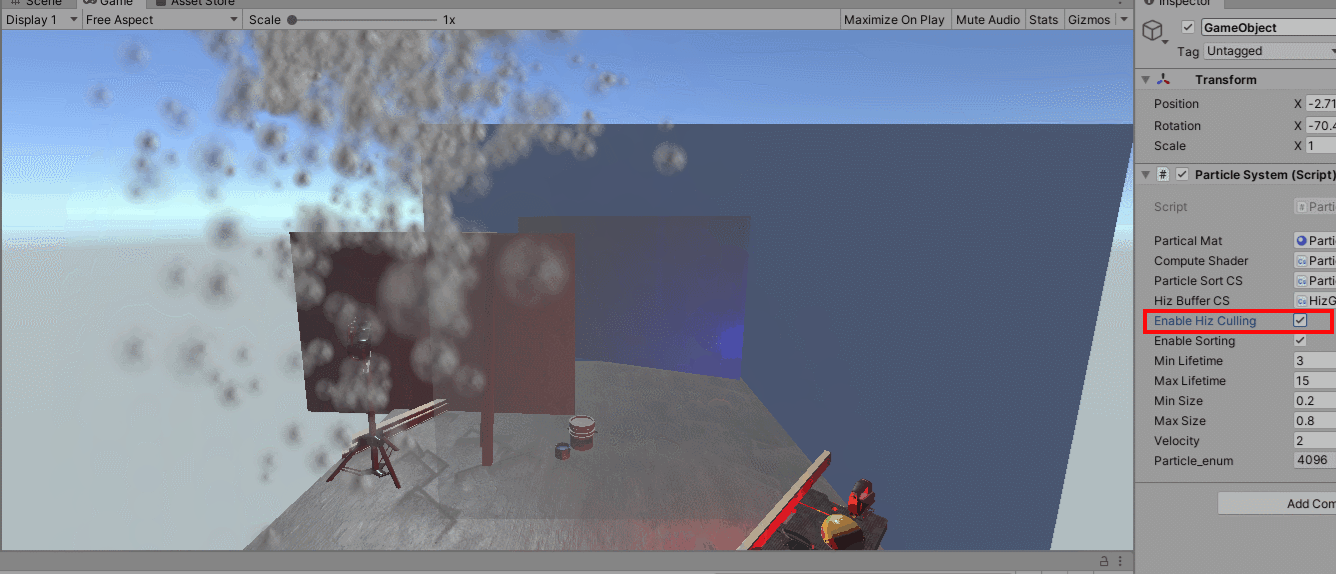 上图通过透明化绘制出来被遮挡体遮住的draw,最外面的蓝色遮挡物比粒子更靠近相机,透明材质写入深度,只为透视可视化显示出遮住的图元。上图在使用hiz剔除和不使用hiz剔除之间切换,可以看到虽然需要绘制的图元有显著的减少,但是Hiz这种保守的遮挡方案还是使得部分应该被剔除的粒子进入到绘制管线中。
上图通过透明化绘制出来被遮挡体遮住的draw,最外面的蓝色遮挡物比粒子更靠近相机,透明材质写入深度,只为透视可视化显示出遮住的图元。上图在使用hiz剔除和不使用hiz剔除之间切换,可以看到虽然需要绘制的图元有显著的减少,但是Hiz这种保守的遮挡方案还是使得部分应该被剔除的粒子进入到绘制管线中。
GPU Sorting
本demo采用使用与GPU的bitonic方式进行GPU sorting. 与Microsoft direct sdk相比,虽然都是bitonic sort.但是后者受限于当时不能进行random write的限制,有点别扭,现在由于硬件的更新去除了这一限制,便有了更易读的sorting方法。
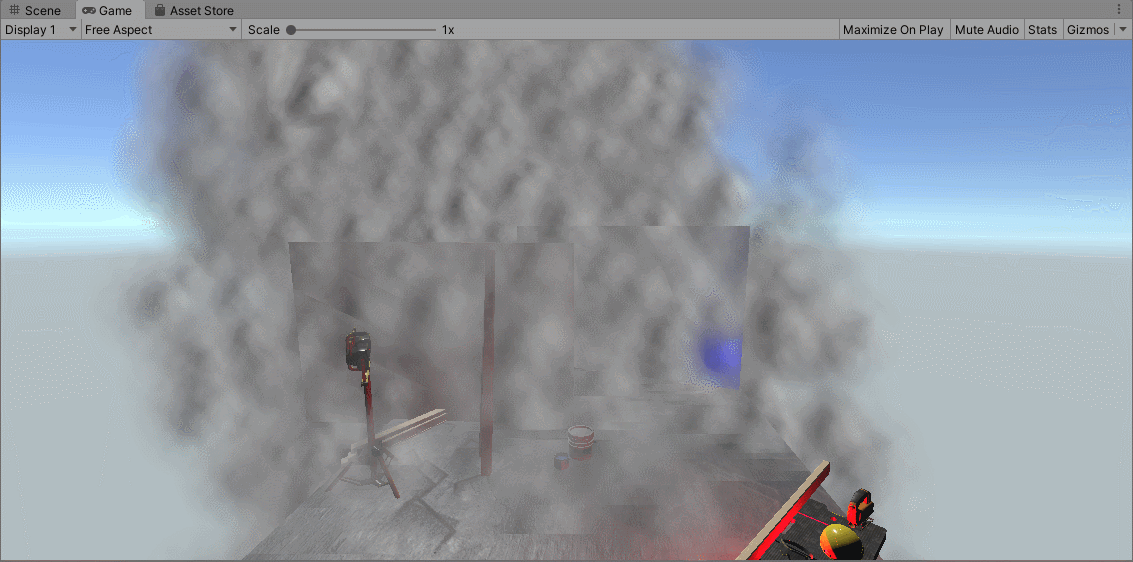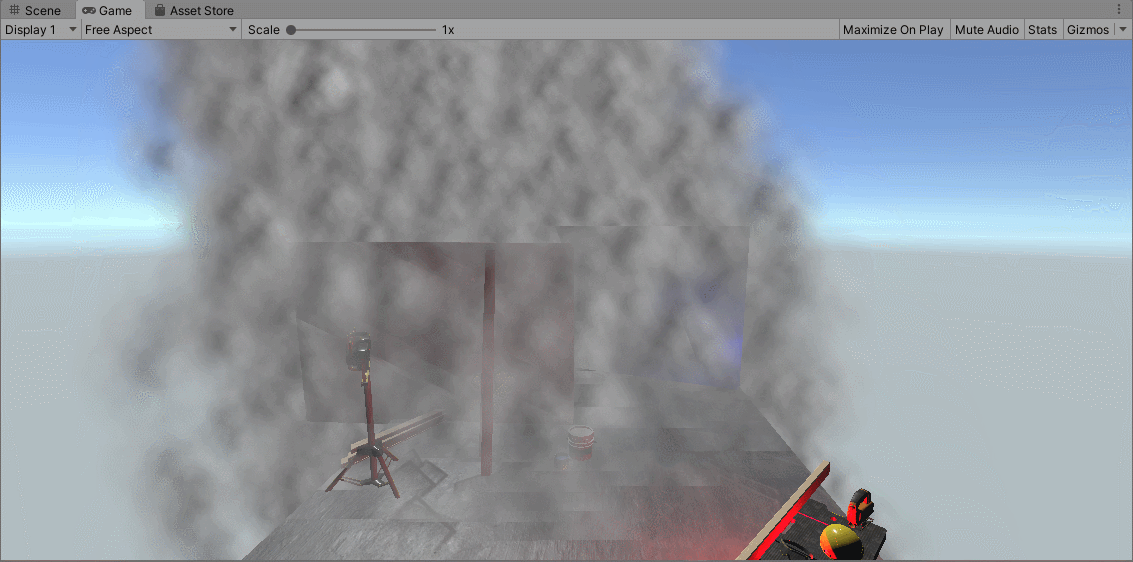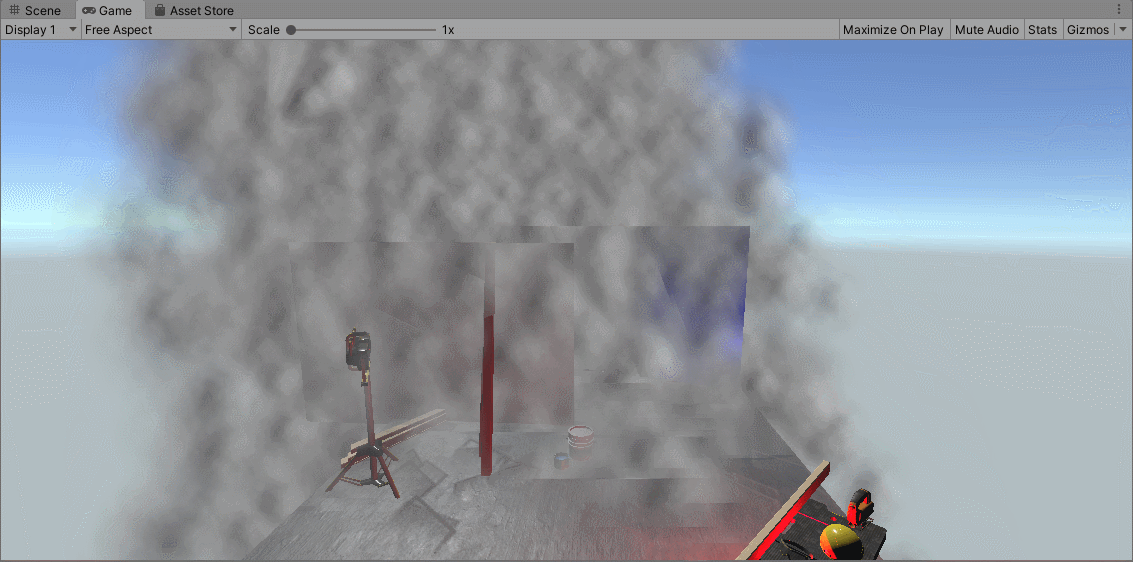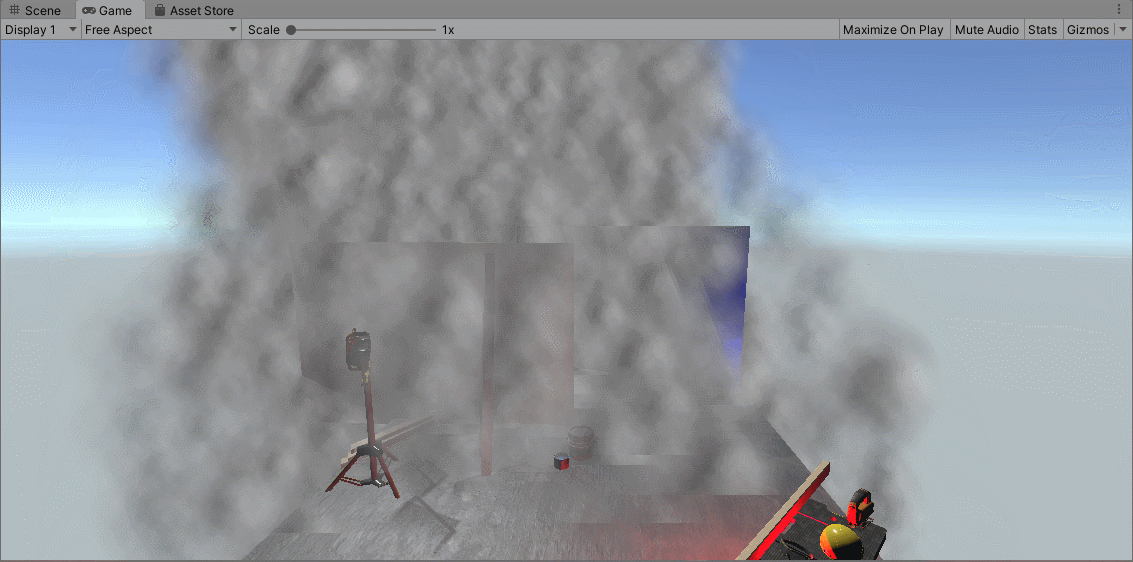 上图展示了没有进行排序的无序粒子,绘制很不稳定,粒子的个数是16384个。
上图展示了没有进行排序的无序粒子,绘制很不稳定,粒子的个数是16384个。
 上图展示了进行深度排序的粒子,绘制出稳定的画面,粒子的个数是16384个。
上图展示了进行深度排序的粒子,绘制出稳定的画面,粒子的个数是16384个。
Unity SRP 实现
Unity对底部的实现细节进行了封装,按照暴露的接口可以由DrawProceduralIndirect指定argument buffer进行indirect draw call。由于绘制draw的参数不一,需要为每个draw绑定各个的shader参数,比如constant buffer和贴图。在较新的渲染API中,可以通过绑定每个indirect draw call的buffer资源的GPU位置偏移和shader resource 来绑定每个drawcall的constant buffer view和贴图资源,这样的好处是shader的编写完全更绘制的方式无关,同样可以按照普通的绘制方式进行脚本编写。但是Unity没法直接去设置底层参数,也没有sparse texture 支持,我们折衷由structbuffer来表达众多的constant buffer view,由3D texture 和纹理索引来表示众多的纹理,然后用每个draw各自id来索引表达绘制参数。
 上图显示在同一个绘制批次中particle的uniform参数(位置,速度)和纹理都可以不一致。
上图显示在同一个绘制批次中particle的uniform参数(位置,速度)和纹理都可以不一致。
兼容性
Indirect draw call 和compute shader在Openes3.1是支持的,该程序可以在笔者小米mix2机器上由vulkan Api进行绘制。
总结
通过简单的GPU_Driven_Pipeline的粒子系统我们可以进一步扩大这个概念,如果每个draw是模型或者模型的某一部分(cluster),就是GPU-Driven Rendering Pipeline)的基本理念。 GPU_Driven_Pipeline是一种为了减少CPU提交次数的充分利用GPU性能的一种绘制技术。为了让绘制更加高效,更加合理,又加入了各种变种的剔除算法,绘制优化等优化算法等。GPU_Driven_Pipeline通常有indirect draw call,这样可以消除GPU和CPU之间的参数传递带宽等待时间,但是它的弊端是这种drawcall会比较慢,而且需要高级API支持。好的GPU_DRIVEN_PIPELINE需要对GPU的加速算法非常熟悉,要不然很可能做的是负优化。
todo
Particles Update里面使用GPU reduction 生成index buffer bug:运行时有什么问题,请disable掉component,然后重新enable看看。另外在frame analysis的时候回不时crush.
参考资料
Experiments in GPU-based occlusion culling – Interplay of Light
Hierarchical-Z map based occlusion culling – RasterGrid Blogosphere
GitHub - nvpro-samples/gl_occlusion_culling: OpenGL sample for shader-based occlusion culling