Awesome
理解 Prompt:基于编程、绘画、写作的 AI 探索与总结
欢迎使用集成了这些模式的工具:https://github.com/prompt-engineering/click-prompt
目录:
文件目录:
- Stable Diffusion 简易教程:Stable Diffusion
- 从 AI 绘画看 AIGC 的未来
- Jupyter 练习 AI 相关部分
- translate.ipynb 中文翻译英文
- codeai.ipynb 代码自动生成
基于编程、绘画、写作的 AI 探索与总结:理解 Prompt
PS:本文的图形部分因 “真实世界原因”,包含一些年龄受限的词汇,建议未成年人在监护人陪同下阅读。
就当前节点(2023.02.22)而言,我虽然研究过一段时间传统的机器学习,但是并不擅长深度学习等领域,所以很多 AI 领域相关的词汇,我是不擅长的,只为自己总结一下,方便在未来更新自己的认识。
内容主要是结合我过去擅长的编程、写作、绘画展开的:
- 绘画:text 2 image。结合 Stable Diffusion 讲述一张图片的演化。
- 写作:chat 2 article。结合 ChatGPT 讲述围绕特定主题的内容创作。
- 编程:comment 2 code。结合 GitHub Copilot 如何加速日常的编程活动。
总体来说,AI 相当于美国队长的实力,遇强则强,遇弱则弱,关键其实在于 Prompt。所以,如何更好地完善 prompt,实现 prompt 工程就是:如何更好地使用 AI 的基础。
Prompt 是一种文本输入方式,用于与自然语言处理模型(例如GPT)进行交互。Prompt 是一个短语或一句话,可以启动模型并产生与 Prompt 相关的输出。这个输出可以是一个单独的单词、一句话,或者是一段完整的段落。它可以控制模型的行为,使其产生特定的结果。
所以,如何更好地完善 prompt,实现 prompt 工程就是:如何更好地使用 AI 的基础。所以,在这篇文章里,我将介绍:
- 用 text 2 image 来展示如何演进 prompt
- 用 text 2 article 来展示充足 prompt 的优点
- 结合 GitHub Copliot 来实现 prompt 完成工作
PS:感谢我老婆提供的照片。
图形生成:如何描述一张照片??
人类需要思考第一个问题:如何描述一张照片?在不关心感受的情况下,我们关注于主体、背景、颜色、构图等。
现在,我们脑海中出现一个场景:

接着,用文本来抽象它。在这里,我结合一下 Stable Diffusion 来讲述一下过程。
文本描述:第一个示例
生成 prompt:
- phodal: 我想写一段话描述一张照片,帮我美化一下:一年轻女子穿着裙子,背对着镜头,在海边看着日落,太阳已经到地平线下面了,她的头发在风中飘动。
- ChatGPT: 这张照片中的场景令人心醉,一位年轻女子穿着一条裙子,站在海边,背对着镜头,凝视着地平线下的夕阳。太阳已经沉入了海面,一片金黄色的光芒在海面上弥漫,照亮了整片海洋,仿佛这个时刻被定格在了时间的某个角落里。女子的头发随着微风轻轻飘动,轮廓被余晖映照得柔和而温暖。她的目光凝视着远方,仿佛在思考着生命的意义和无尽的未来。这张照片中蕴含着一种深刻的内涵,让人感受到时间和自然的力量,也让人思考着自己在这个宏大而美丽的世界中的角色和意义。
如果转换成英语的话:
A young woman wearing a flowing dress stands at the edge of the sea, her back turned to the camera as she gazes upon the glow of the setting sun. The ocean stretches out before her in all its grandeur, and the sun slowly sinks below the horizon, casting a golden light over the water. The woman's hair sways gently in the breeze, her features softened by the warm hues of the sunset. Her gaze is fixed on the distance, as if pondering the meaning of life and the endless possibilities of the future.
重复了 N 次之后,你会得到你想要的成功的照片,当然也会有失败的出现(因为没有配置 negative prompt 过滤失败的情况):

但是,熟悉各种搜索引擎的关键词的或者 NLP 的你,肯定知道,上面的大部分可能是废话,可以减化为如下的词,并添加一些专用的模型词汇,如black hair, hand before body, no hand, bodycon dress:
women back view without face, flowing dress, edge of the sea, backview, back turned to the camera, upon the glow of the setting sun, sun below the horizon, golden light over the water, hair sways gently, Chinese style clothes, black hair,
随后,添加一些反向 prompt,意思是不要这些内容,诸如于 AI 不擅长的:bad hands、morbid 等等。随后,不断调整 prompt,比如生成更好的 Prompt:
诸如于采用 Magic Prompt。
精准控图:结合 ControlNet
由于生成的姿势是随机的、无法控制,所以我就引入了 ControlNet 插件 ——用来实现骨骼绑定、精准控线、线稿上色、依据深度图结构透视精准重绘等。现在,就能结合我们做的创作来完善生成的图形,诸如于我们绘制草图、或者输入一张原始图片,就可以生成我们预期的效果:
最后,生成的图片如下:

在我写完文章的时候,又修改了一下 prompt:
women back view without face standing on the sandy beach, bodycov full skirt, edge of the sea, back turned to the camera, upon the glow of the setting sun, black hair, sunset red to blue gradient sky
对应的 negative prompt 是:
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
效果凑合着,还是不错的。然后,我们可以做更多的尝试,配合一下参数调整(俗称炼丹):
<table> <tr> <td><img src="./output/samples/01.jpeg" width="256px" height="384px"></td> <td><img src="./output/samples/02.jpeg" width="256px" height="384px"></td> <td><img src="./output/samples/04.jpeg" width="256px" height="384px"></td> </tr> <tr> <td><img src="./output/samples/05.jpeg" width="256px" height="384px"></td> <td><img src="./output/samples/06.jpeg" width="256px" height="384px"></td> <td><img src="./output/samples/08.jpeg" width="256px" height="384px"></td> </tr> </table>也可以结合 inpaint 对失真的部分进行修复。
更多的模型集:与二次元世界的照片(18 禁)
众所周知,AI 的生成质量是与模型息息相关的,所以好的质量需要有好的模型。
我们可以在 https://civitai.com/ 上找到更多的模型,不过因为年龄限制等原因,只建议你在安全的场所打开,不建议在公共场所打开。
真实的人物由于版权的种种原因,所以这个软件在二次元世界相当的流行。如下是常见的提示词来描述模型的质量,里面可能包含一些不适词语,为了体现真实世界,这里并不打算屏蔽。
提示词 :
modelshoot style, (wavy blue hair), ((half body portrait)), ((showing boobs, giant boobs, humongous breasts)), (( beautiful light makeup female sorceress in majestic blue dress)), photo realistic game cg, 8k, epic, (blue diamond necklace hyper intricate fine detail), symetrical features, joyful, majestic oil painting by Mikhail Vrubel, Atey Ghailan, by Jeremy Mann, Greg Manchess, WLOP, Charlie Bowater, trending on ArtStation, trending on CGSociety, Intricate, High Detail, Sharp focus, dramatic, photorealistic, black background, epic volumetric lighting, fine details, illustration, (masterpiece, best quality, highres), standing in majestic castle
负面提示词
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),((( missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet, lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
足够丰富的描述,可以帮助 AI 理解描述我们的需求:

上图为 AI 生成,也是同样场景下,不屏蔽的结果 —— 其原因是大部分的模型库加入了很多 18 禁的内容。
小结
现在,让我们来思考一下,如何描述一张带人物的图片:
- 详细的描述词。
- 人物的姿势。
- 丰富的模型。
- 反复修改的参数。
- 持续迭代。(基于 InPaint 等进行修改)
那么,文章呢?
文章:如何围绕特定主题思考?
结合一下先前 Stable Diffusion 的无数次的失败经验,我们应该先找好一个合适的框架来跑 ChatGPT。
在编写内容的内容,我们会有各种思路和原则:STAR、金字塔原理、5W1H等等。
我们可以以 STAR (Situation(情景)Task(任务)、Action(行动)和 Result(结果))可以作为与 ChatGPT 会话的基础:
- 描述一个情境或背景,使读者对问题有更好的了解。
- 说明任务或目标,告诉读者需要完成什么。
- 描述你所采取的行动,例如使用什么方法、工具、策略等等。
- 解释结果,包括遇到的挑战和取得的成果。
这样,对于我们展开思路会有一些帮助。
情境:如何用 ChatGPT 写一篇文章,以如何用 ChatGPT 写一篇文章?
phodal:我想写一篇文章,主题是《如何用 ChatGPT 写一篇文章,以如何用 ChatGPT 写一篇文章 》
示例:

但是,这样的内容并非我们想要的。
而在这个标题里,其实 ChatGPT 已经理解了,如何写一篇文章,换作是一个冷门的话题,他就不知道了。在此时,我们需要构建一个更丰富的上下文:

在这时,ChatGPT 给出的步骤依旧是错的,我们需要继续纠正。所以,我们可以考虑在一开始给一个完整的上下文:
构建更完整的上下文
对于 ChatGPT 来说,我们需要明确的 prompt::
我想写一篇文章,主题是《如何用 ChatGPT 写一篇文章,以如何用 ChatGPT 写一篇文章》,文章的大纲是:
1. 先用 100 字介绍一下 ChatGPT
2. 以 Julia 作为可以以具体的案例为例,介绍如何使用 ChatGPT 写一篇博客大赛的参赛作品。这包括如何确定主题、如何撰写开头和结尾、如何组织文章结构等等。主题是:《Julia Dataframe 在大数据分析领域的使用》,大纲中包含:用 200 字介绍一下 Julia 语言历史;介绍如何使用 DataFrames.jl,并有个代码示例;对比一下 Python Pandas、Apache Spark Dataframe;小结。
3. 对本文的内容进行总结,并再次强调使用 ChatGPT 进行写作的好处。
帮我写一篇文章?
如此一来,我们提供的上下文就会更加准确,就可以看到一个范例:

基于这个范例,可以思考我们的内容如何编写。
构建框架(frameworks)
ChatGPT 本身构建了一个框架,我们可以再输入一个有用的框架,以构建简单的反馈回路。于是,我开始教他 DDD,然后相互学习:

不过,ChatGPT 和上面的图片一样,经常丢失一些上下文。
phodal: 在这个 TicketOrder 聚合里,他应该包含哪些 API ?
在 TicketOrder 聚合里,可以包含以下一些 API:
- createOrder():创建一个新的订单,可以接收顾客信息、场次信息、座位信息等参数,并返回一个唯一的订单号。
- cancelOrder(orderId):取消某个订单,需要提供订单号。
- getOrder(orderId):获取某个订单的详细信息,需要提供订单号。
- reserveSeats(showTimeId, seatIds):在某个场次中预留座位,需要提供场次号和座位号。
- confirmOrder(orderId):确认订单,此时座位被锁定并且订单状态被改为已确认。
- payOrder(orderId, paymentInfo):支付订单,需要提供订单号和支付信息。
- refundOrder(orderId):退票,需要提供订单号并且只能在订单状态为已确认时进行。
- updateOrder(orderId, updateInfo):修改订单信息,可以更新顾客信息、场次信息、座位信息等,需要提供订单号和更新内容。
基本的 API 可以满足电影院订票业务的需求,但具体实现还需要根据业务场景和需求进行细化和调整。
其它小建议:
相似的,与 Stable Diffusion 类似的是,AI 生成的内容经常出现各种问题,所以我们要注意:
- 保持自然的表达。ChatGPT 能够生成流畅的语句,但有时可能会出现奇怪或不合适的表达。在使用 ChatGPT 进行写作时,需要注意保持自然的表达方式。
- 适时修正错误。如果 ChatGPT 生成的内容不准确或有错误,应该及时进行修正,以保证文章的准确性和可读性。
- 多次修改和调整。ChatGPT 的输出结果虽然会自动进行语法纠错和编辑,但是为了保证文章质量,还是需要经过多次修改和调整,不断完善文章结构和内容。
- 保持简洁明了。在使用 ChatGPT 进行写作时,需要尽量保持简洁明了,避免使用过于复杂的句式和词汇,以便读者更好地理解文章内容。
- 注重原创性和独特性。尽管 ChatGPT 能够生成大量的文章,但是为了在博客大赛中脱颖而出,还需要注重文章的原创性和独特性,尽可能地突出自己的风格和思想。
考虑到 ChatGPT 的代码并不那么准确,让我们使用 GitHub Copilot 生成更多的内容。
代码生成:GitHub Copilot
GitHub Copilot 是 GitHub 2021 年 8 月推出的一个 AI 代码生成工具,它可以根据你的代码,生成更多的代码。

所以,对于 Markdown 本身来说,它也能提供一些帮助。当然了,在这方向它没有 ChatGPT 那么强大,经常会出现一些奇怪的重复代码。
但是,也并非不可用,我们可以使用它来生成一些代码片段,以便于我们进行修改。
完整示例:DDD + ChatGPT + Copilot
如结合 Chat GPT 我们可以完成代码的前置设计(当然有些不靠谱):

复制生成的 API,写行注释告诉 Copilot:convert to markdown table,然后我们就有了:
| API | 描述 | HTTP方法 | URL | 参数 | 返回值 |
|---|---|---|---|---|---|
| 创建订单 | 创建一个新的订单 | POST | /ticket-orders | 创建订单信息 | 订单ID |
| 查询订单 | 查询一个已存在的订单 | GET | /ticket-orders/{orderId} | 订单ID | 订单信息 |
| 取消订单 | 取消一个已存在的订单 | DELETE | /ticket-orders/{orderId} | 订单ID | 取消成功或失败信息 |
| 添加座位 | 向一个已存在的订单添加座位 | POST | /ticket-orders/{orderId}/seats | 座位信息 | 座位添加成功或失败信息 |
| 移除座位 | 从一个已存在的订单中移除座位 | DELETE | /ticket-orders/{orderId}/seats/{seatId} | 座位ID | 座位移除成功或失败信息 |
| 查询可用座位 | 查询某个场次电影的可用座位 | GET | /cinema-schedule/{scheduleId}/available-seats | 场次ID | 可用座位信息 |
接下来,我们可以使用 Spring + Copilot 来生成一些代码片段,以便于我们进行修改:

在有足够类相关信息的情况下,诸如于,我们提供一个注释:
@PostMapping
fun createTicketOrder(@RequestBody ticketOrder: TicketOrder): String {
// check the schedule is valid, the seats are available, then create the order
}
它生成的代码会更加准确:

而如果我们添加了对应的 Exception 的处理注释:check the schedule is valid, the seats are available, then create the order, if the schedule is not valid, throw NotScheduleAvailableException,代码进一步转化为:
@PostMapping
fun createTicketOrder(@RequestBody ticketOrder: TicketOrder): String {
// check the schedule is valid, the seats are available, then create the order, if the schedule is not valid, throw NotScheduleAvailableException
// check the schedule is valid
val schedule = cinemaScheduleService.getSchedule(ticketOrder.scheduleId)
if (schedule == null) {
throw NotScheduleAvailableException()
}
// check the seats are available
val availableSeats = cinemaScheduleService.getAvailableSeats(ticketOrder.scheduleId)
if (!availableSeats.containsAll(ticketOrder.seats)) {
throw NotSeatAvailableException()
}
// create order
return tickerOrderApplicationService.createOrder(ticketOrder)
}
在另外一些场景下,如果你的函数名和参数名都是英文,那么 Copilot 生成的代码也会更加准确:

而在单元测试的场景下,Copilot 更加强大和智能,它能够根据你的测试代码,生成更多的测试代码。
其它:代码生成开源模型
我也尝试了下 Saleforce 的代码模型:https://huggingface.co/Salesforce/codegen-6B-mono,但是不能在我的 MBP 上跑上来,有些遗憾。
总结:AI 就像占卜
你可能无法预期输出的是啥,总会有各种惊喜。
而其实,与 AI 的 prompt 相似的是:和人类聊天的时候,我们也需要提供足够的上下文。所以,你需要一下 ChatGPT,他并不总是能理解你的上下文。
其它:Macbook Pro 的吐槽
公司配置的 Macbook Pro 2019 虽然有 AMD 显卡,但是没有 CUDA、ROCm 的支持,所以只能用 CPU 来跑了。
AI 生态不友好
诸如于 PyTorch,以前是支持 ROCm 加速的:
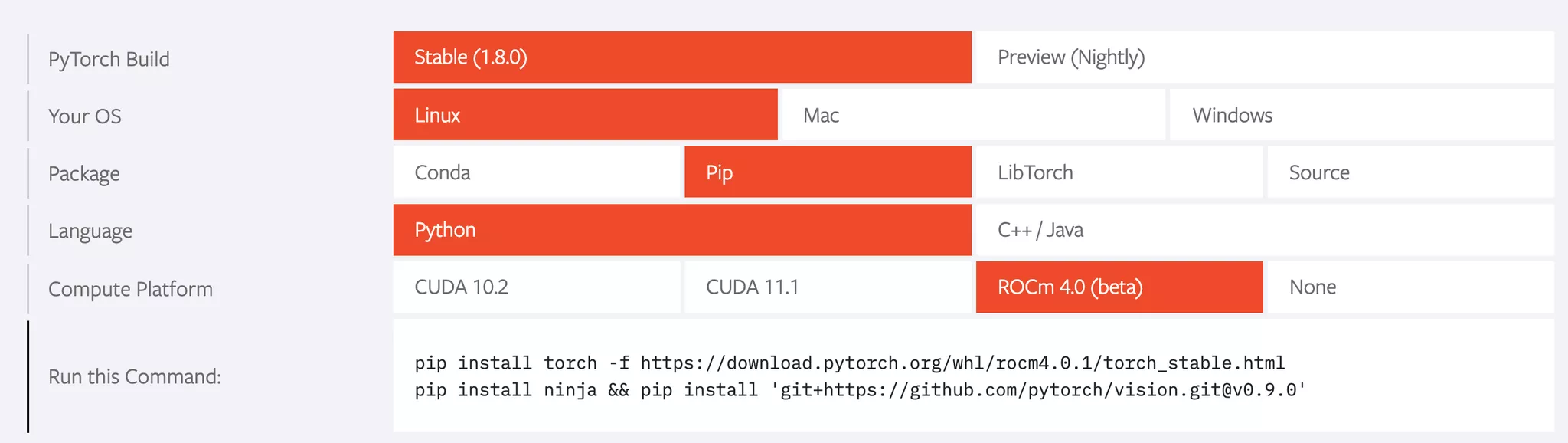
现在的版本不行了:https://pytorch.org/get-started/locally/ 。
本文相关资源
AI 生成图片:
- Stable Diffusion Webui GitHub: https://github.com/AUTOMATIC1111/stable-diffusion-webui
- 通用的 AI 模型社区:https://huggingface.co/
- Stable Diffusion AI 艺术模型社区:https://civitai.com/ (18 禁)
代码模型相关:
- Salesforce 模型:https://huggingface.co/Salesforce/codegen-6B-mono
- CarpserAI: https://huggingface.co/CarperAI/diff-codegen-6b-v2
ControlNet 加强:
- 模型:https://huggingface.co/lllyasviel/ControlNet
- 预编译:https://huggingface.co/kohya-ss/ControlNet-diff-modules
实时的软件生成 —— Prompt 编程打通低代码的最后一公里?
PS:这也是一篇畅想,虽然经过了一番试验,依旧有一些不足,但是大体上站得住脚。
传统的软件生成方式需要程序员编写大量的代码,然后进行测试、发布等一系列繁琐的流程。而实时生成技术则是借助人工智能技术,让计算机自动生成代码,并直接运行,从而大大提高了软件生成的效率和质量。
而实时生成技术是一种借助人工智能技术让计算机自动生成代码,并直接运行的方法,大大提高了软件生成的效率和质量。实现实时软件生成的一种方式是 Prompt 编程,可以将自然语言转化为直接运行的软件,而无需生成中间的一次性过渡代码。
引子
从 2019 年,写了那篇《**无代码编程》开始,我也一直在思考,诸如于 2021 年 和 2022 年 的前端趋势总结。
先前,我并不看好当前的低代码/无代码方案,先我们来思考一下这个过程:
第一步,业务需求需要在人类脑海里转换一遍,转换为程序逻辑。
第二步,专业人员(如程序员)将这些逻辑转换到无代码系统中,生成应用并直接部署。
第三步,如果这个专业人员是程序员,那么新的需要变更时,他可能直接去修改源码。
而随着 ChatGPT 的进一步普及,你会发现你可以很容易将需求转化为形式化格式,进而转化而软件,从而使得软件开发的效率和速度大大提升。这种一次性代码的新型软件工程方法就是实时软件生成,便可以进入真正的 “无代码” 时代。
Prompt 编程:真正的无代码
- Prompt 编程是实现实时软件生成的一种方式,可以将自然语言转化为直接运行的软件,而无需生成中间的一次性过渡代码。每当需要运行程序时,只需要再运行一下 prompt 或者触发词,就可以直接运行起某个软件。
我们尝试从编写 Prompt 的经验里,归纳出一套适合于 Prompt 编程的逻辑,方便于大家理解。Prompt 编程有以下特性:
1)从需求到代码的直接转换;
2)代码只是临时产物;
3)次序化的分解框架。
这种一次性代码的新型软件工程方法可以进入真正的 “无代码” 时代。
Prompt 编程特性 1:从需求到代码的直接转换
用户只需要简单输入自己的需求就能够生成符合要求的软件,无需具备专业的编程技能。示例:
我们来玩一个 mul 游戏,当我说 mul 开头,并输入数字时,你应该计算结果。示例:"""当我输入:mul 4,你应该输出:16"""
在这个游戏里,我们使用:
- 触发词。mul 作为街头暗号,告诉程序你要按这个步骤走。类似于编程里的函数名。
- 示例作为输入和输出。即预期输入某个结果时,输出我们想要的结果。
而在其实,已经是一个函数该有的样子:输入、输出、关系。值得注意的是,在简单的问题下,只要我们给定了示例,那么 AI 就会根据示例去计算输入和输出,不关注中间的处理逻辑。
接下来,再看一个隐含性编程的示例,依旧我们还是玩个游戏:
我们能玩一个名为 kfc 的谜语创作游戏,当我说 "kfc",你写一个谜题,要求:
1. 不少于 200 字
2. 谜题不能出现肯德基和星期四
3. 正文可以夹杂小语种语言,如 """他说:Ciao"""
4. 谜底必须是 ###原来今天是肯德基疯狂星期四!!!###
格式类似于:
"""
...
"""
这个例子已经相当的自由,我们也不关心中间的处理逻辑,只关注于结果。
Prompt 编程特性 2:代码只是临时产物
还记得在 Prompt 编写模式 中的 wula 游的例子吗?在 wula 游戏里,用户只需要输入问题,ChatGPT 便会自动给出代码、代码解释和文章。诸如于:wula: 头共10,足共28,鸡兔各几只?,那么 AI 便会开始自动开始二次编程:
这是一个鸡兔同笼问题,题目给出了头的数量和足的数量,要求求出鸡和兔的数量。通常解决这个问题的方法是,假设鸡和兔的数量分别为 x 和 y,那么可以列出如下方程组:
x + y = 10
2x + 4y = 28
解方程组可以得到 x=4,y=6,即鸡有4只,兔有6只。
鸡兔同笼问题的 JavaScript 代码实现
// 计算鸡兔数量的函数
function calcAnimals(heads, legs) {
.....
在传统的体系之下,我们要关注于中间生成的 JavaScript 代码、代码能不能运行等等,所以我们在设计 wula 的时候,要求了:
第二步. 代码编写:你需要用 JavaScript 编写解决这个问题的代码,并输出对应的代码,并介绍一下你的代码(不少于 200 字)。
第三步. 代码执行:你需要作为 JavaScript Console 执行第二步写的代码,如果没有给出测试数据,你需要自己随机生成测试数据,并将这些数据输入到代码中进行计算。
但是,回到第一个例子里,我们并不需要 JavaScript 代码,我们不需要任何代码。ChatGPT 可以为我们生成这部分的程序!!!
唯一限制我们的是:
- ChatGPT 的上下文能力
- 我们的 Prompt 编写能力
而在复杂的场景之下,Prompt 编写需要足够的形式化,才能让机器理解,也因此,我才把它称为 Prompt 编程。
Prompt 编程特性 3:次序化的分解框架
仅就当前而言 AI 的上下文能力,限制了 AI 解决复杂问题的能力。所以,它无法一次性解决复杂、中大型的问题,甚至于小型项目都存在一定的难度。同样的,对于人类来说,也存在这样的局限性,只是人类的问题是领域知识有限。
步骤详细见:DDD Sample
所以,作为编程核心的人类大脑,需要为机器设计一下工序,即每一步应该怎么做。所以,这个时候,就回到了 DDD(领域驱动设计)擅长的问题:
我们来定义一下 DDD 游戏的步骤,一共有 6 个步骤,步骤如下:
"""
第一步. 拆解场景。分析特定领域的所有商业活动,并将其拆解出每个场景。
第二步. 场景过程分析。选定一个场景,并使用 "{名词}已{动词}" 的形式描述过程中所有发生的事件,其中的名词是过程中的实体,其中的动词是实体相关的行为。
第三步. 针对场景建模。基于统一语言和拆解出的场景进行建模,以实现 DDD 设计与代码实现的双向绑定。
……
"""
对于每一步,我们只要限定好我们的输出(Output),那么在给定输入的情况下,AI 就能给出我们想要的(也有可能跑偏了)结果:
ddd 第二步:场景过程分析。下面是每个场景的过程分析:
用户注册和登录
用户注册:用户填写注册信息,系统验证信息合法性,生成用户账户并保存。
用户登录:用户输入账户名和密码,系统验证账户密码,登录成功后跳转到用户中心。
商品展示和搜索
商品列表展示:系统从数据库中获取商品列表并展示,用户可以进行商品分类和排序。
商品搜索:用户输入关键词进行商品搜索,系统根据关键词从数据库中获取商品列表并展示。
……
在这时,我们就可以引导 AI 生成到 API 粒度:
| API名称 | 请求方法 | 请求路径 | 请求体 | 响应体 | 描述 |
|---|---|---|---|---|---|
| 创建商品 | POST | /api/products | 商品信息 | 创建的商品信息 | 创建一个新的商品 |
| 获取商品列表 | GET | /api/products | 无 | 商品列表信息 | 获取所有的商品列表 |
| 获取单个商品信息 | GET | /api/products/{id} | 无 | 单个商品信息 | 根据商品 ID 获取单个商品信息 |
| 更新商品信息 | PUT | /api/products/{id} | 更新的商品信息 | 更新后的商品信息 | 根据商品 ID 更新商品信息 |
| 删除商品 | DELETE | /api/products/{id} | 无 | 无 | 根据商品 ID 删除商品信息 |
也可以生成代码,甚至于在上下文足够强大的时候,也是能够直接运行和自动优化的。
Prompt 编程特性 4:语言即语言
DSL(领域特定语言)是指专门针对某个特定领域的语言,通常具有严格定义的语法和规则,并且可以用来描述该领域中的问题、概念、过程和数据等。而经过形式化处理的自然语言可以被视为一种 DSL,因为它们具有明确定义的语法和规则,可以用来描述特定领域中的问题、概念、过程和数据等。
所以,简单来说如果我们限定了输入和输出的格式,那么我们的自然语言也是一种 DSL。这就意味着,限制我们进行次序化的关键就是形式化的抽象。
而,我们也可以通过编写 Prompt 来生成新的 DSL:帮我设计一个 DSL,用来写函数
好的,以下是一个简单的DSL设计,可以用来写函数:
1. 函数定义
在这个段落中,定义一个函数,包括函数名、参数和函数体等。
函数: 函数名: 描述函数的名称 参数: 参数1: 描述参数1的名称和类型 参数2: 描述参数2的名称和类型 ... 函数体: 描述函数的实现细节
2.。。。
简单来说,我们可以通过 Prompt :
- 借用 Prompt 设计自然语言式的 DSL
- 将自然语言式的 DSL 融入 Prompt
- 使用次序化的方式来实现 Prompt 自我编程
进而,我们就得到了一个可以自举的 Prompt。
Prompt 编程 Demo:引导 ChatGPT 创建语言与建模
说了,这么多我们来看一个结合我之前设计的 DSL 示例,即 Fklang。
阶段一:让 ChatGPT 与你学 DDD
在 Fklang 中,我们采用下面的形式来表示 ContextMap:
ContextMap TicketBooking {
Reservation -> Cinema;
Reservation -> Movie;
Reservation -> User;
}
但是,自己设计这样的 DSL 太累了,可以让 ChatGPT 来设计。在你开始之前,需要确认一下 ChatGPT 中的 DDD、DSL、事件风暴等的概念是否与你理解的一致。
第一个问题:设计一个 DSL 来表示 DDD 里的 Context Map 。
ContextMap:
Subdomain { Name: [subdomain_name] }
[CollaboratesWith: [other_subdomain_name], ...]
[ConformistWith: [other_subdomain_name], ...]
[Antagonizes: [other_subdomain_name], ...]
...
第二个问题:用这个 ContextMap DSL 对在线电影订票系统建模。对于其它问题也是相似的。
第三个问题:设计一个 DSL 来描述事件风暴的 事件建模 吗?
第四个问题:能用 事件建模的 DSL 来表示用户购票的流程吗?
一旦,我们觉得设计跑歪了,就可以重新设计。如果下是生成的复杂的 DSL:
EventStorming:
Domain { Name: "电影订票系统" }
Event { Name: "用户提交订单" }
Triggered By: "用户选择电影、场次、座位,确认订单"
Description: "用户提交订单,包括所选电影、场次、座位等信息"
Actors: ["用户"]
Action: "将用户提交的订单信息保存到订单数据库中"
Outcome: "订单状态被标记为已提交"
第五个问题……
剩下的你都会了,不会的,可以问 ChatGPT。
阶段二:完整设计 + DSL 生成
第一个问题:能总结一下,我们这里用 DDD 设计 购票系统到落地代码的过程吗?
第二个问题:能为每个过程,设计一个合理的 DSL 吗,并展示他们?
展示一部分神奇的 DSL:
generate java-code from-domain-model
target-package: com.example.movieticket.order
source-model: order-domain-model
service-mapper 订单服务映射
map-method: 查询电影
to-class: MovieRepository
to-method: findBySchedule
map-method: 查询座位
to-class: SeatRepository
to-method: findByRowAndColumnAndStatus
现在,有意思的地方来,有了上面的一系列 DSL 之后,我们就可以接入到代码系统中。
阶段三:代码生成与低代码
只要 ChatGPT 上下文能力足够强壮,或者支持 LoRA 式的插件模式,我们就能实现从需要到现有的任何系统中。
第一个问题:为电影订票系统设计一个 DDD 风格 Java 工程的代码目录结构。
第二个问题:结合 Spring 设计一下购票流程的 RESTful API
……
有点懒,就先这样吧。后面的部分,就可以结合 GitHub Copilot 去实现了。
小结
结合 Prompt 编程,低代码到了一定的成熟度,我们就可以发现更好玩的东西:实时的软件生成
实时的软件生成:自然语言即 Prompt,Prompt 即代码
实时软件生成核心思想是,通过算法和机器学习来自动生成代码,让计算机根据用户需求,快速生成符合要求的软件。这种技术能够自动化完成代码的编写、测试、发布等流程,大大缩短软件开发周期,降低了开发成本,提高了开发效率。
当我们想构建这样一软件用于实时生成软件时,它需要具备以下的特征:
特征 1:自然语言即语言,语言即软件
即如上面的 Prompt 编程所述,可以通过设定层层转换,直接将需求直接转换为软件。
特征 2:生成式的软件架构
软件本身不需要架构,架构是 AI 自动生成和调整的。
特征 3:自底向上生成
现有的语言本身需要 REPL 环境、操作系统、编程语言、语言底层库、库等一系列软件,对于 AI 而言,他能学习这些通用能力,自操作系统底层一样,逐步往上构建出软件的运行环境,以及软件本身 。
当前的挑战
对于当前而言,我们还存在些挑战:
- 现行组织架构难以支撑内部 ChatGPT。如内部权限、架构等的管理
- 通用大模型无法满足。领域特定能力有限,需要构建 LoRA 以更好的支持。
- 细节能力实现较差。在编程实现上,远不如 GitHub Copilot
当然了,受限于个人能力,可能还有别的一些挑战。
总结
本文介绍了 Prompt 编程的特点和实时软件生成的核心思想。Prompt 编程是一种次序化的分解框架,可以让机器根据用户需求自动生成代码。实时软件生成技术可以大大提高软件生成的效率和质量,同时也让软件开发变得更加简单。然而,现有组织架构难以支撑内部 ChatGPT,上下文能力有限,细节能力实现较差,这些都是实现 Prompt 编程和实时软件生成的难点。
如何利用好 AIGC ?从 AI 绘画的演进与 ChatGPT 现状出发
PS:就本文的结论而言,我相信你已经或多或少的有所体会了。也因此,本文更多的是展现一个思考的过程,而不是一个纯粹的结论。
AIGC 是什么?它是指通过机器学习、自然语言处理等人工智能技术,让计算机自动生成文字、图像、音频、视频等各种类型的内容。它能够帮助企业和个人降低创作成本、提高生产效率、增强创意输出等。
开始之前,先说结论:哪怕仅就当前的 AIGC 成熟度,我们都明白:人类应该去做更高价值的事,也因此在当前的工作模式上呈现的是,三步区:
- 蓝图设计(人类)。 负责创意性的思考与设计工作,如场景、软件架构等。
- 机械化生成(机器)。将创意借助工具或者人转换为 Prompt,然后交给 AIGC 生成。
- 细节修复(人类)。对于 AIGC 生成不合理、不适宜法律法规等的地方,进行修改。
因此,对于诸多通用的大众领域,人类这样的碳基生物而言,如果不能从思维框架来驾驭 AIGC。而对于细分领域来说,只要在足够卷的情况下,AIGC 也会给予我们更多的惊喜。
与 ChatGPT 的黑盒相比,类似于 Stable Diffusion 白盒开源,可以让我们更了解 Prompt 应该如何编写?如何更好地利用 AIGC。所以,本文的第一部分就是从现有的 AI 绘画的变化来看,如何更好的利用 AIGC。而第二部分则是结合 ChatGPT 的现状来看,如何更好的利用 AIGC。
如何构建高质量的 AI 图形:精准控线 + 个人模型
注意:请在取得授权的情况下,进行个人模型的练习,避免侵犯个人肖像权。
我们的例子,依旧是基于 Stable Diffusion,开源模型与开源软件才是人类的未来。太长不看图:

对于一个绘画过程来说,我们可以通过如下的方式,逐步引导绘图应用:
- 编写详细的 Negative Prompt,以淘汰不合理的生成内容。
- ControlNet 作为基准骨架,引导最终效果,过滤不合理的图像。
- 训练与融合个人模型,以构建领域特定的用途。
总的来说:过滤不合理的图像,就能提升生成质量。我们就可以,设计出初步符合需求(在不看 AI 画出来的手情况下)的框架性方案。
严格化验收条件:Negative Prompt
Negative Prompt 会将模型的目标从一般的高概率生成样本转换为生成与负向提示不匹配的低概率样本,从而迫使模型更加关注图像的细节和特征,提高其生成的图像的质量和逼真度。
我们的故事依旧可以从:微笑的女孩探出火车窗外 故事开开始,简单地翻译成英语,来作为我们的 prompt:smiling girl leaning out the train window。在只有 Prompt 的情况下,会生成各种奇怪的图形,所以我们需要添加 Negative Prompt。
所以在 Stable Diffusion 里,我们就可以通过它来提升质量:

而从结果来看,模型与我们想要的图,还存在一定的距离。对于 ChatGPT 也是类似的,所以我们需要相似的模式:诸如于 写一个不超过 800 字的作文,又或者是 写一个作文,要求如下:1. 不超过 800 字。
构架蓝图:ControlNet 精准控线
ControlNet 是一种神经网络结构,旨在通过添加额外条件来控制扩散模型。在特定场景下,ControlNet被用于生成类似建模效果(法线贴图)的中间图和相关的图像。这种技术可以被应用于多个领域,如骨骼绑定、精准控线、线稿上色、深度图结构透视精准重绘等。
简单来说,在人像领域,通过手绘特定的姿势、从照片中解析等方式,创建一个人物姿势,绘制出来的图便采用类似的格式。如下图所示:

从形状和生成的效果来说,除了脸部等细节不是特定令人满意之外,基本能满足使用的需求。而在更好地机器加持下,我们能得到更高分辨率,就可以靠人工修复脸部的问题。
而在写作场景之下,只要我们给了 ChatGPT 大纲,那么他就能帮助我们生成文章。唯一的问题是,我们不能添加上自己的写作风格、历史作品,否则我们可以更加容易使用这个作品。而在那之前,我们需要思考什么是我们的作品?什么是我们的风格?
轻量小模型:DreamBooth 个人模型与风格化
注意:请在取得授权的情况下,进行模型的练习与作品创作。除了 DreamBootb 还有其他工具可使用,但由于时间限制,我就没有展开进一步研究。
融合个人模型是指将训练后的个人风格和特点融入到 AI 绘画模型中,使其生成的画作更贴近个人风格和需求,提高生成画作的个性化和定制化。
诸如在 Stable Diffusion 中,我们可以用自己的头像结合 DreamBooth 等工具训练,以得到一个融合自己风格的模型。在二次元世界里,最常被使用的是 "个人头像",以用于生成动漫或者 idol。效果如下:

PS:在取得某人同意的情况下,放一张动画化的结果(当然了,取的是不像本人的照片):

在 Stable Diffusion 的模型尝试之后,我们可以发现:云 GPU + 模型可插件化 + 算力要求逐步下降之后,会使得个人的小模型会变成越来越普及,所以我训练的模型也只在云上跑了几分钟。
完善与细化:局部绘制 —— InPaint 的手部修复
众所周知,当前的 AI 绘图还存在诸多细节问题,比如手、脚等,因此需要一定的人类修复画师。又有一部分人自此成为了服务于 AI 的打工人。如下是使用 InPaint 修复手部时生产出来的,人类画师就需要从中挑选出合适的照片:

最后,总算,先找到一张可以凑合着交差的:

除此,还可以选择对图形进行裁剪,或者使用 Photoshop 等工具进行重绘等。
小小的总结:严格化验收条件 + 构架蓝图 + 轻量小模型 + 完善与细化
要想清晰的表达自己的需求,我们需要:
- 严格化的验收条件,即通过 Prompt 描写需求,通过 Negative Prompt 排除异常
- 表达构架蓝图,即通过 ControlNet 创建所需要的内容骨架,控制
- 轻量的领域小模型,即通过 DreamBooth,结合灵活的架构模型,来丰富 AI 模型。
- 完善与细化,即通过 InPaint 对有缺陷的部分进行修复,如局部绘制。
当然了,在 Stable Diffusion 里,还可以通过 Inpaint 等方式进行修复。
个人 AI 策略:构架 + 磨炼 + 小模型
在先前的两篇文章里,我们已经不断地在探索适合于个人的 AI 策略:
对于我来说,我的 AI 策略大致是:
- 强化构架能力。强化架构设计、软件设计、抽象设计等。
- 构建小模型。在未来合适的时候,诸如于合适的开源 GPT 等。
- 探索与磨炼技巧。探索更多的 AI 解决方案,如 Notion AI 等;持续探索 Prompt 模式等。
对于修复与完善来说,由于 AI 本身是无法达到这么精细的,所以我的想法是持续构建小工具。
策略 0:拥抱变化
首先,我们要理解 AIGC 真的带来变化,尽管现今的 AI 并不能完整的代替我们,但是已经能大大提升效率。
作为一个知名的 “开源挖抗” 作者,在我使用 GitHub Copilot 的初期,觉得这 TM(Trademark) 就是一个智障。而我适应了:如何与智障沟通之后,我悟了,我才是 ”智障“ —— 只有理解机器的 API 与工作方式,才能利用好机器。
策略 1:强化构架能力
AI 工具无法替代个人的感性思考和直觉,所以个人在设计过程是非常重要性的。
强化设计是指通过 AI 技术释放个人的创造力,帮助个人在设计中实现更高效、更优质的创造成果。这个策略的核心在于使用 AIGC 工具来自动生成大量的创意元素,例如图像、文字、音频等,从而将创造的效率提高到一个新的水平。
在实践中,个人可以通过以下方式强化自己的构架能力:
- 持续学习新的设计理念和创意方法,不断拓展自己的知识面和视野。例如,了解一些新兴的设计趋势,学习如何将传统的设计元素与现代的技术手段相结合,从而创造出更有创意和张力的作品。
- 坚持思考和探索,不断挑战自己的思维方式和想象力。通过不断思考和实践,将自己的思维方式和想象力逐渐转化为可操作的设计构架,从而在 AIGC 工具的帮助下实现更高效的创造。
除此,我们还应该熟练掌握使用 AIGC 工具的方法,尤其是一些高级的特性。例如,对于文本生成任务,可以使用 Negative Prompt 等技巧提高生成的质量;对于图像生成任务,则可以使用 ControlNet 等技术实现更精准的控制。
策略 2:构建领域小模型
PS:此处需要持续寻找合适的工具,就当前而言,只有 AI 绘图领域是相对比较成熟(可用)的。
每个人的知识面是不同的,知识体系也是不同的。因此,我们不能期望一个通用的大模型能够满足所有人的需求。相反,我们应该尝试构建适合自己领域的小模型。通过选择合适的数据集、算法和网络结构,我们可以快速训练出一个专门用于解决自己问题的小型模型。这个模型不需要太复杂,只需要满足自己的需求即可。这样可以提高模型的效率和准确度,并且减少训练时间和计算资源的消耗。
例如,对于一个博客作者来说,可以使用 GPT-3 来帮助自己快速生成博客文章的开头或结尾段落,也可以通过训练自己的小模型,生成符合自己风格的文章内容。对于一名摄影师来说,可以通过构建小模型来辅助自己完成相册的排版、图像剪辑等工作。
所以,对于而言,我有 900+ 的博客,从中训练出来的写作风格,大概是能像我的 —— 也存在不同时机的风格不一样的问题。
策略 3:探索与磨炼技巧
对于探索而言,也是最近才有时间和精力去探索,加入了公司的相关讨论群后,也获得了更多的输入。只是对于我来说,更多的是想把 AI 融入到日常事务中,以提升工作效率,所以也不想去创建微信群。
对于技巧来说,其实更多的是要去理解 AI 是如何 work 的,并将这种模式整合到自己的思维方式里。
除此,我们还可以思考如何将思维框架赋予 AI,以完成更闭环的工作。诸如于 GitHub Copilot 可以帮我们写代码,但是无法从宏观上理解业务问题、整体性的架构问题,生成的代码只是从局部考虑的。因此,我们需要通过不断地磨炼自己的技能和能力,来提高自己的综合素质和创造力。如我正在持续丰富的 phodal/prompt-patterns 也算是我的磨炼技巧。
小结
最后,再让 AI 总结一下四个策略:
- 拥抱变化,尽管人工智能并不能完全代替人类,但它已经能够大大提高效率。
- 强化构架能力,因为人工智能工具无法代替个人的感性思考和直觉。
- 构建领域小模型,可以快速训练出一个专门用于解决自己问题的小型模型。
- 探索与磨炼技巧,探索 AI 能力并持续构建小工具,来修复和完善自己的 AI 增强系统。
结论,AI 在短期内还是智障,但是已经可以大大提升效率了。