Awesome
<div align="center">![]()
![]()
![]()
![]()
1. What does this library do?
grex is a library that is meant to simplify the often complicated and tedious task of creating regular expressions. It does so by automatically generating a single regular expression from user-provided test cases. The resulting expression is guaranteed to match the test cases which it was generated from.
This project has started as a Rust port of
the JavaScript tool regexgen
written by Devon Govett. Although a lot of
further useful features could be added to it, its development was apparently
ceased several years ago. The Rust library offers new features and extended
Unicode support. By compiling it to WebAssembly (WASM),
these improvements are now back in the browser and in Node.js.
This repository here contains only the compiled WASM modules and the generated
JavaScript bindings. They have been created from the Rust source code with the help
of wasm-pack.
The philosophy of this project is to generate the most specific regular expression possible by default which exactly matches the given input only and nothing else. With the use of preprocessing methods, more generalized expressions can be created.
The produced expressions are Perl-compatible regular expressions.
They are mostly compatible with JavaScript's
RegExp
implementation but not all PCRE features are supported. An alternative is the XRegExp
library which virtually supports the entire PCRE feature set. Other regular expression parsers or
respective libraries from other programming languages have not been tested so far,
but they ought to be mostly compatible as well.
There is a demo website available where you can give grex a try.
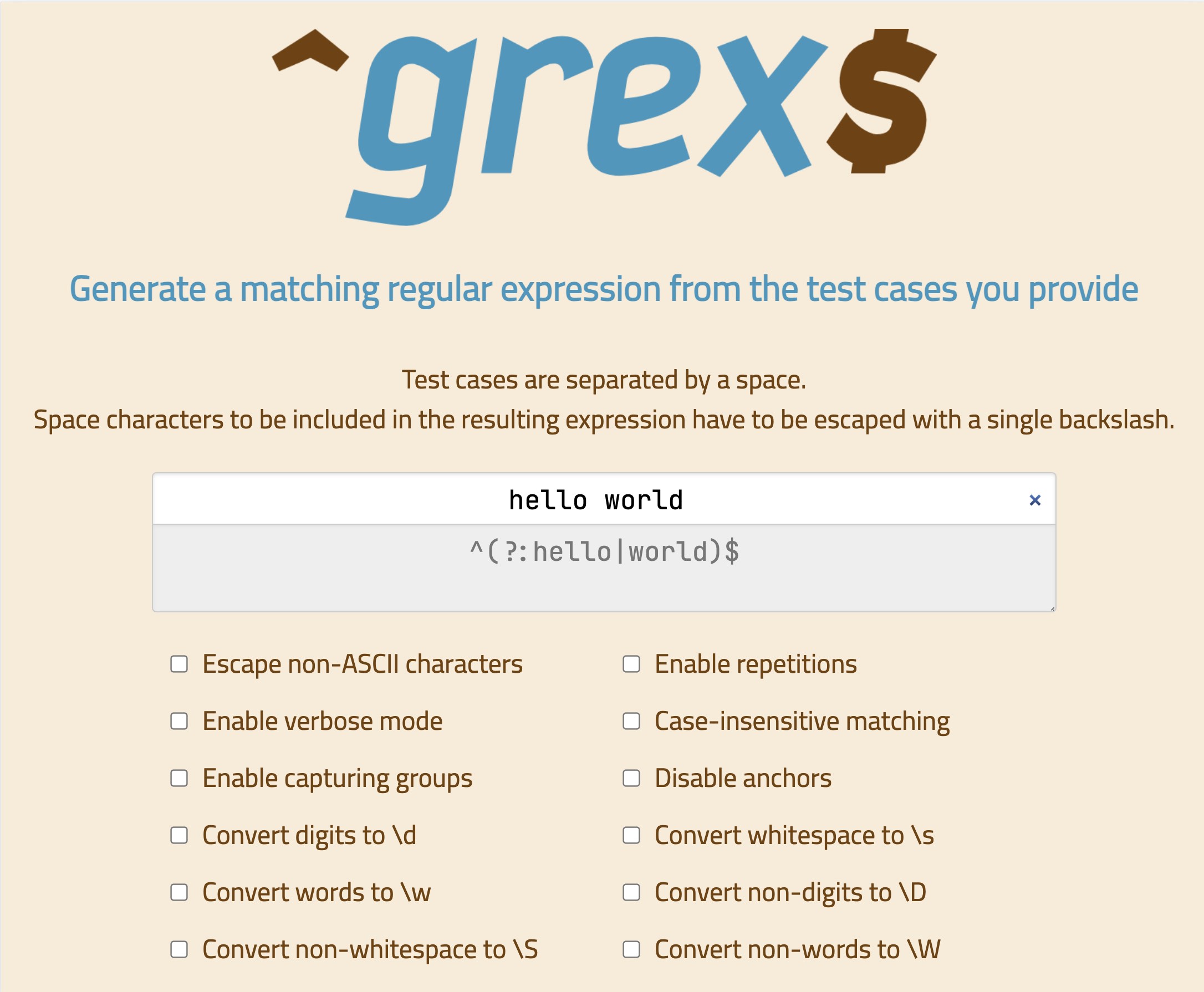
2. Do I still need to learn to write regexes then?
Definitely, yes! Using the standard settings, grex produces a regular expression that is guaranteed
to match only the test cases given as input and nothing else. However, if the conversion to shorthand
character classes such as \w is enabled, the resulting regex matches a much wider scope of test cases.
Knowledge about the consequences of this conversion is essential for finding a correct regular expression
for your business domain.
grex uses an algorithm that tries to find the shortest possible regex for the given test cases. Very often though, the resulting expression is still longer or more complex than it needs to be. In such cases, a more compact or elegant regex can be created only by hand. Also, every regular expression engine has different built-in optimizations. grex does not know anything about those and therefore cannot optimize its regexes for a specific engine.
So, please learn how to write regular expressions! The currently best use case for grex is to find an initial correct regex which should be inspected by hand if further optimizations are possible.
3. Current Features
- literals
- character classes
- detection of common prefixes and suffixes
- detection of repeated substrings and conversion to
{min,max}quantifier notation - alternation using
|operator - optionality using
?quantifier - escaping of non-ascii characters, with optional conversion of astral code points to surrogate pairs
- case-sensitive or case-insensitive matching
- capturing or non-capturing groups
- optional anchors
^and$ - fully compliant to Unicode Standard 15.0
- correctly handles graphemes consisting of multiple Unicode symbols
- produces more readable expressions indented on multiple using optional verbose mode
- optional syntax highlighting for nicer output in supported terminals
4. How to install?
npm install @pemistahl/grex
The current version 1.0.2 corresponds to the latest version 1.4.2 of the Rust library and command-line tool.
5. How to use?
Detailed explanations of the available settings are provided in the API section.
5.1 In the browser
grex is available as an ECMAScript module. So it can be used in the browser,
but it needs a module bundler. As WebAssembly is a pretty new technology, the
only bundler which is currently compatible is Webpack 5.
In your webpack.config.js file, you need to add the following setting to enable
WASM support:
module.exports = {
...
experiments: {
asyncWebAssembly: true
}
};
Afterwards, you can import the library as shown below and bundle your JavaScript as usual.
import { RegExpBuilder } from '@pemistahl/grex';
const testCases = ['hello', 'world'];
const pattern = RegExpBuilder.from(testCases).build();
console.log(pattern === '^(?:hello|world)$');
const regexp = RegExp(pattern);
for (const testCase of testCases) {
console.log(regexp.test(testCase));
}
5.2 In Node.js
The library is also available as a CommonJS module, so it can be easily used in Node.js.
const { RegExpBuilder } = require('@pemistahl/grex');
const testCases = ['hello', 'world'];
const pattern = RegExpBuilder.from(testCases).build();
console.log(pattern === '^(?:hello|world)$');
const regexp = RegExp(pattern);
for (const testCase of testCases) {
console.log(regexp.test(testCase));
}
5.3 The API
The entire API docs are hosted on doxdox.org.
5.3.1 Default settings
const regexp = RegExpBuilder.from(['a', 'aa', 'aaa']).build();
console.assert(regexp === '^a(?:aa?)?$');
5.3.2 Convert to character classes
const regexp = RegExpBuilder.from(['a', 'aa', '123'])
.withConversionOfDigits()
.withConversionOfWords()
.build();
console.assert(regexp === '^(?:\\d\\d\\d|\\w(?:\\w)?)$');
5.3.3 Convert repeated substrings
const regexp = RegExpBuilder.from(['aa', 'bcbc', 'defdefdef'])
.withConversionOfRepetitions()
.build();
console.assert(regexp === '^(?:a{2}|(?:bc){2}|(?:def){3})$');
By default, grex converts each substring this way which is at least a single character long and which is subsequently repeated at least once. You can customize these two parameters if you like.
In the following example, the test case aa is not converted to a{2} because the repeated substring
a has a length of 1, but the minimum substring length has been set to 2.
const regexp = RegExpBuilder.from(['aa', 'bcbc', 'defdefdef'])
.withConversionOfRepetitions()
.withMinimumSubstringLength(2)
.build();
console.assert(regexp === '^(?:aa|(?:bc){2}|(?:def){3})$');
Setting a minimum number of 2 repetitions in the next example, only the test case defdefdef will be
converted because it is the only one that is repeated twice.
const regexp = RegExpBuilder.from(['aa', 'bcbc', 'defdefdef'])
.withConversionOfRepetitions()
.withMinimumRepetitions(2)
.build();
console.assert(regexp === '^(?:bcbc|aa|(?:def){3})$');
5.3.4 Escape non-ascii characters
const regexp = RegExpBuilder.from(['You smell like 💩.'])
.withEscapingOfNonAsciiChars(false)
.build();
console.assert(regexp === '^You smell like \\u{1f4a9}\\.$');
Old versions of JavaScript do not support Unicode escape sequences for the astral code planes
(range U+010000 to U+10FFFF). In order to support these symbols in JavaScript regular
expressions, the conversion to surrogate pairs is necessary. More information on that matter
can be found here.
const regexp = RegExpBuilder.from(['You smell like 💩.'])
.withEscapingOfNonAsciiChars(true)
.build();
console.assert(regexp === '^You smell like \\u{d83d}\\u{dca9}\\.$');
5.3.5 Case-insensitive matching
The regular expressions that grex generates are case-sensitive by default. Case-insensitive matching can be enabled like so:
const regexp = RegExpBuilder.from(['big', 'BIGGER'])
.withCaseInsensitiveMatching()
.build();
console.assert(regexp === '(?i)^big(?:ger)?$');
5.3.6 Capturing Groups
Non-capturing groups are used by default. Extending the previous example, you can switch to capturing groups instead.
const regexp = RegExpBuilder.from(['big', 'BIGGER'])
.withCaseInsensitiveMatching()
.withCapturingGroups()
.build();
console.assert(regexp === '(?i)^big(ger)?$');
5.3.7 Verbose mode
If you find the generated regular expression hard to read, you can enable verbose mode. The expression is then put on multiple lines and indented to make it more pleasant to the eyes.
const regexp = RegExpBuilder.from(['a', 'b', 'bcd'])
.withVerboseMode()
.build();
console.assert(regexp ===
`(?x)
^
(?:
b
(?:
cd
)?
|
a
)
$`);
5.3.8 Disable anchors
By default, the anchors ^ and $ are put around every generated regular expression in order
to ensure that it matches only the test cases given as input. Often enough, however, it is
desired to use the generated pattern as part of a larger one. For this purpose, the anchors
can be disabled, either separately or both of them.
const regexp = RegExpBuilder.from(['a', 'aa', 'aaa'])
.withoutAnchors()
.build();
console.assert(regexp === 'a(?:aa?)?');
6. How does it work?
-
A deterministic finite automaton (DFA) is created from the input strings.
-
The number of states and transitions between states in the DFA is reduced by applying Hopcroft's DFA minimization algorithm.
-
The minimized DFA is expressed as a system of linear equations which are solved with Brzozowski's algebraic method, resulting in the final regular expression.