Awesome
PAR Scrape



PAR Scrape is a versatile web scraping tool with options for Selenium or Playwright, featuring AI-powered data extraction and formatting.

Screenshots
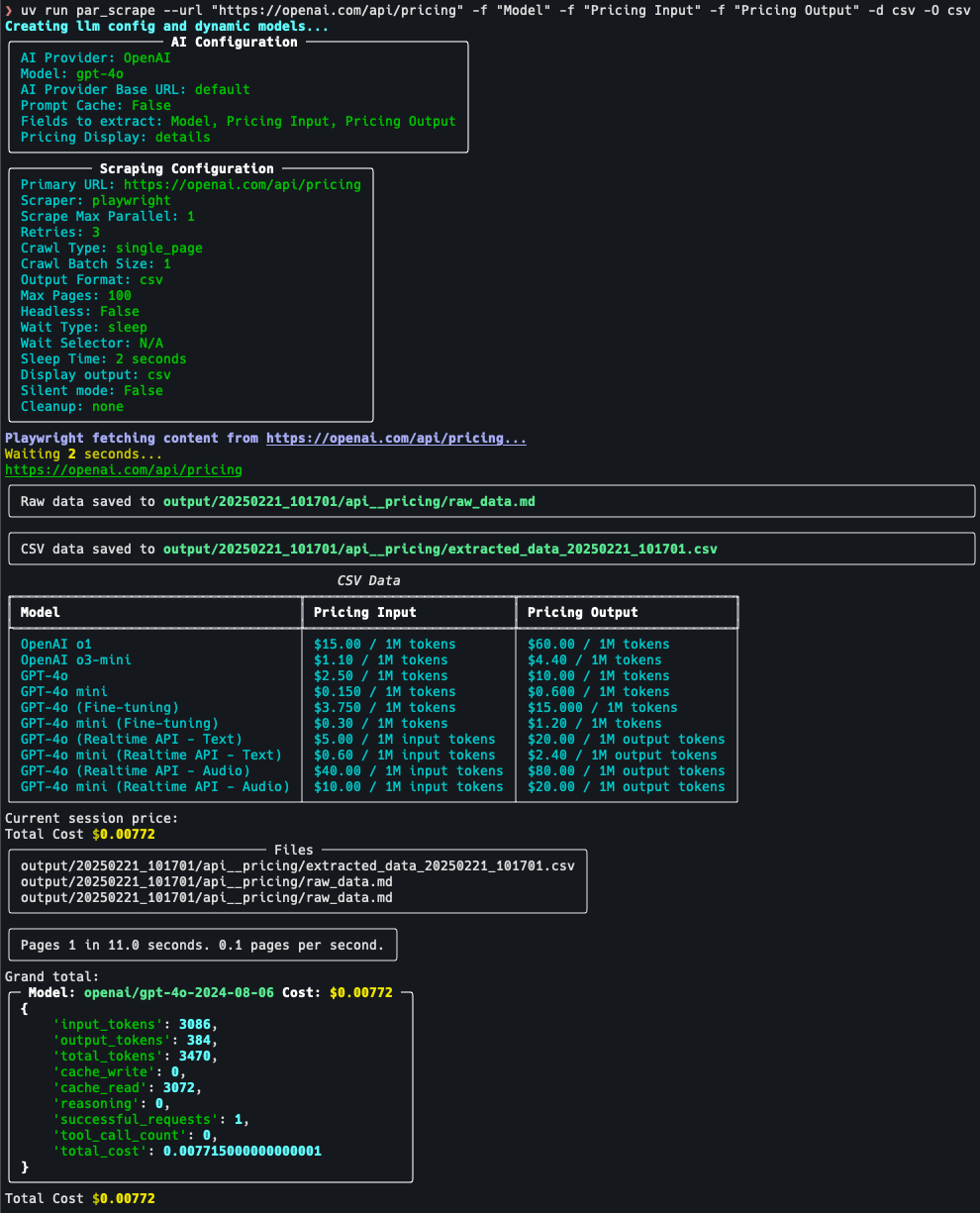
Features
- Web scraping using Playwright or Selenium
- AI-powered data extraction and formatting
- Supports multiple output formats (JSON, Excel, CSV, Markdown)
- Customizable field extraction
- Token usage and cost estimation
- Prompt cache for Anthropic provider
Known Issues
- Selenium silent mode on windows still shows message about websocket. There is no simple way to get rid of this.
- Providers other than OpenAI are hit-and-miss depending on provider / model / data being extracted.
Prompt Cache
- OpenAI will auto cache prompts that are over 1024 tokens.
- Anthropic will only cache prompts if you specify the --prompt-cache flag. Due to cache writes costing more only enable this if you intend to run multiple scrape jobs against the same url, also the cache will go stale within a couple of minutes so to reduce cost run your jobs as close together as possible.
Prerequisites
To install PAR Scrape, make sure you have Python 3.11.
uv is recommended
Linux and Mac
curl -LsSf https://astral.sh/uv/install.sh | sh
Windows
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Installation
Installation From Source
Then, follow these steps:
-
Clone the repository:
git clone https://github.com/paulrobello/par_scrape.git cd par_scrape -
Install the package dependencies using uv:
uv sync
Installation From PyPI
To install PAR Scrape from PyPI, run any of the following commands:
uv tool install par_scrape
pipx install par_scrape
Playwright Installation
To use playwright as a scraper, you must install it and its browsers using the following commands:
uv tool install playwright
playwright install chromium
Usage
To use PAR Scrape, you can run it from the command line with various options. Here's a basic example:
Ensure you have the AI provider api key in your environment.
You can also store your api keys in the file ~/.par_scrape.env as follows:
GROQ_API_KEY= # is required for Groq. Get a free key from https://console.groq.com/
ANTHROPIC_API_KEY= # is required for Anthropic. Get a key from https://console.anthropic.com/
OPENAI_API_KEY= # is required for OpenAI. Get a key from https://platform.openai.com/account/api-keys
GITHUB_TOKEN= # is required for GitHub Models. Get a free key from https://github.com/marketplace/models
GOOGLE_API_KEY= # is required for Google Models. Get a free key from https://console.cloud.google.com
LANGCHAIN_API_KEY= # is required for Langchain Langsmith tracing. Get a free key from https://smith.langchain.com/settings
AWS_PROFILE= # is used for Bedrock authentication. The environment must already be authenticated with AWS.
# No key required to use with Ollama models.
Running from source
uv run par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" -f "Cache Price" --model gpt-4o-mini --display-output md
Running if installed from PyPI
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" -f "Cache Price" --model gpt-4o-mini --display-output md
Options
--url,-u: The URL to scrape or path to a local file (default: "https://openai.com/api/pricing/")--fields,-f: Fields to extract from the webpage (default: ["Model", "Pricing Input", "Pricing Output"])--scraper,-s: Scraper to use: 'selenium' or 'playwright' (default: "playwright")--headless,-h: Run in headless mode (for Selenium) (default: False)--wait-type,-w: Method to use for page content load waiting [none|pause|sleep|idle|selector|text] (default: sleep).--wait-selector,-i: Selector or text to use for page content load waiting.--sleep-time,-t: Time to sleep (in seconds) before scrolling and closing browser (default: 5)--ai-provider,-a: AI provider to use for processing (default: "OpenAI")--model,-m: AI model to use for processing. If not specified, a default model will be used based on the provider.--prompt-cache: Enable prompt cache for Anthropic provider. (default: False)--display-output,-d: Display output in terminal (md, csv, or json)--output-folder,-o: Specify the location of the output folder (default: "./output")--silent,-q: Run in silent mode, suppressing output (default: False)--run-name,-n: Specify a name for this run--version,-v: Show the version and exit--pricing: Enable pricing summary display ('details','cost', 'none') (default: 'none')--cleanup,-c: How to handle cleanup of output folder (choices: none, before, after, both) (default: none)--extraction-prompt,-e: Path to alternate extraction prompt file--ai-base-url,-b: Override the base URL for the AI provider.
Examples
- Basic usage with default options:
par_scrape --url "https://openai.com/api/pricing/" -f "Model" -f "Pricing Input" -f "Pricing Output" --pricing -w text -i gpt-4o
- Using Playwright and displaying JSON output:
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --scraper playwright -d json --pricing -w text -i gpt-4o
- Specifying a custom model and output folder:
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --model gpt-4 --output-folder ./custom_output --pricing -w text -i gpt-4o
- Running in silent mode with a custom run name:
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --silent --run-name my_custom_run --pricing -w text -i gpt-4o
- Using the cleanup option to remove the output folder after scraping:
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --cleanup --pricing
- Using the pause option to wait for user input before scrolling:
par_scrape --url "https://openai.com/api/pricing/" -f "Title" -f "Description" -f "Price" --pause --pricing
- Using Anthropic provider with prompt cache enabled and detailed pricing breakdown:
par_scrape -a Anthropic --prompt-cache -d csv -p details -f "Title" -f "Description" -f "Price" -f "Cache Price"
Whats New
- Version 0.4.8:
- Added Anthropic prompt cache option.
- Version 0.4.7:
- BREAKING CHANGE: --pricing cli option now takes a string value of 'details', 'cost', or 'none'.
- Added pool of user agents that gets randomly pulled from.
- Updating pricing data.
- Pricing token capture and compute now much more accurate.
- Version 0.4.6:
- Minor bug fixes.
- Updating pricing data.
- Added support for Amazon Bedrock
- Removed some unnecessary dependencies.
- Code cleanup.
- Version 0.4.5:
- Added new option --wait-type that allows you to specify the type of wait to use such as pause, sleep, idle, text or selector.
- Removed --pause option as it is no longer needed with --wait-type option.
- Playwright scraping now honors the headless mode.
- Playwright is now the default scraper as it is much faster.
- Version 0.4.4:
- Better Playwright scraping.
- Version 0.4.3:
- Added option to override the base URL for the AI provider.
- Version 0.4.2:
- The url parameter can now point to a local rawData_*.md file for easier testing of different models without having to re-fetch the data.
- Added ability to specify file with extraction prompt.
- Tweaked extraction prompt to work with Groq and Anthropic. Google still does not work.
- Remove need for ~/.par-scrape-config.json
- Version 0.4.1:
- Minor bug fixes for pricing summary.
- Default model for google changed to "gemini-1.5-pro-exp-0827" which is free and usually works well.
- Version 0.4.0:
- Added support for Anthropic, Google, Groq, and Ollama. (Not well tested with any providers other than OpenAI)
- Add flag for displaying pricing summary. Defaults to False.
- Added pricing data for Anthropic.
- Better error handling for llm calls.
- Updated cleanup flag to handle both before and after cleanup. Removed --remove-output-folder flag.
- Version 0.3.1:
- Add pause and sleep-time options to control the browser and scraping delays.
- Default headless mode to False so you can interact with the browser.
- Version 0.3.0:
- Fixed location of config.json file.
Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
License
This project is licensed under the MIT License - see the LICENSE file for details.
Author
Paul Robello - probello@gmail.com