Awesome
Schedoscope is no longer under development by OttoGroup. Feel free to fork!
Introduction
Schedoscope is a scheduling framework for painfree agile development, testing, (re)loading, and monitoring of your datahub, datalake, or whatever you choose to call your Hadoop data warehouse these days.
Schedoscope makes the headache go away you are certainly going to get when having to frequently rollout and retroactively apply changes to computation logic and data structures in your datahub with traditional ETL job schedulers such as Oozie.
With Schedoscope,
- you never have to create DDL and schema migration scripts;
- you do not have to manually determine which data must be deleted and recomputed in face of retroactive changes to logic or data structures;
- you specify Hive table structures (called "views"), partitioning schemes, storage formats, dependent views, as well as transformation logic in a concise Scala DSL;
- you have a wide range of options for expressing data transformations - from file operations and MapReduce jobs to Pig scripts, Hive queries, Spark jobs, and Oozie workflows;
- you benefit from Scala's static type system and your IDE's code completion to make less typos that hit you late during deployment or runtime;
- you can easily write unit tests for your transformation logic in ScalaTest and run them quickly right out of your IDE;
- you schedule jobs by expressing the views you need - Schedoscope takes care that all required dependencies - and only those- are computed as well;
- you can easily export view data in parallel to external systems such as Redis caches, JDBC, or Kafka topics;
- you have Metascope - a nice metadata management and data lineage tracing tool - at your disposal;
- you achieve a higher utilization of your YARN cluster's resources because job launchers are not YARN applications themselves that consume cluster capacitity.
Getting Started
Get a glance at
Build it:
[~]$ git clone https://github.com/ottogroup/schedoscope.git
[~]$ cd schedoscope
[~/schedoscope]$ MAVEN_OPTS='-XX:MaxPermSize=512m -Xmx1G' mvn clean install
Follow the Open Street Map tutorial to install and run Schedoscope in a standard Hadoop distribution image:
Take a look at the View DSL Primer to get more information about the capabilities of the Schedoscope DSL:
Read more about how Schedoscope actually performs its scheduling work:
More documentation can be found here:
Check out Metascope! It's an add-on to Schedoscope for collaborative metadata management, data discovery, exploration, and data lineage tracing:
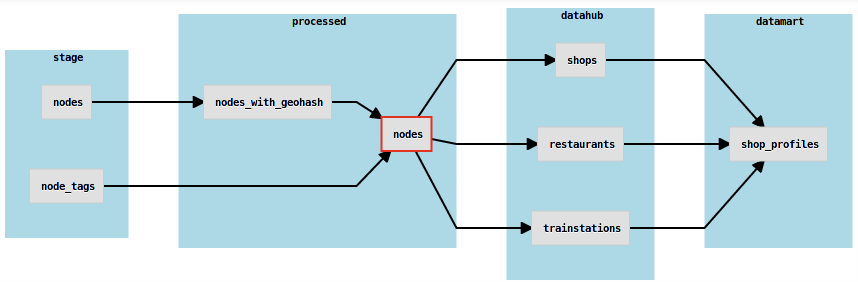
When is Schedoscope not for you?
Schedoscope is based on the following assumptions:
- data are largely relational and meaningfully representable as Hive tables;
- there is enough cluster time and capacity to actually allow for retroactive recomputation of data;
- it is acceptable to compile table structures, dependencies, and transformation logic into what is effectively a project-specific scheduler;
- it is acceptable that your scheduler creates and possibly drops Hive tables and databases it manages.
Should any of those assumptions not hold in your context, you should probably look for a different scheduler.
Origins
Schedoscope was conceived at the Business Intelligence department of Otto Group
Contributions
The following people have contributed to the various parts of Schedoscope so far:
Utz Westermann (maintainer), Kassem Tohme, Alexander Kolb, Christian Richter, Jan Hicken, Diogo Aurelio, Hans-Peter Zorn, Dominik Benz, Annika Seidler, Martin Sänger, Julian Keppel.
We would love to get contributions from you as well. We haven't got a formalized submission process yet. If you have an idea for a contribution or even coded one already, get in touch with Utz or just send us your pull request. We will work it out from there.
Please help making Schedoscope better!
News
05/08/2018 - Release 0.10.2
We have released Version 0.10.2 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
We have changed the materialization logic of materializeOnce views such that they no longer ask their child views to materialize if the materializeOnce views have been materialized already. This improves performance.
04/24/2018 - Release 0.10.1
We have released Version 0.10.1 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This is a bugfix release correcting the order of the TBLPROPERTIES and LOCATION clauses in the Hive DDL generated for views. Please do note that if you use the tblProperties clause in some views, this change affects the DDL checksum making Schedoscope drop and recreate the respective tables. Hence the version bump to 0.10.1.
Thanks to Julian Keppel for reporting the issue and providing the fix.
04/06/2018 - Release 0.9.13
We have released Version 0.9.13 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Removed derelict indirect CDH5.12.0 dependencies incurred by Cloudera's Spark 2.2.0-Cloudera2 dependency.
03/15/2018 - Release 0.9.11
We have released Version 0.9.11 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Added configuration parameter schedoscope.export.disableAll to globally disable all view exports. Useful in test environments.
03/09/2018 - Release 0.9.10
We have released Version 0.9.10 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Upgraded Cloudera dependencies to CDH 5.14.0.
01/25/2018 - Release 0.9.9
We have released Version 0.9.9 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Export your views to Google Cloud Platform's BigQuery via a simple exportAs() statement.
BigQuery export now compresses view data before sending it off to Google Cloud Storage.
01/24/2018 - Release 0.9.7
We have released Version 0.9.7 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Optimized performance of BigQuery export by moving more work to the map phase of the export job.
01/23/2018 - Release 0.9.6
We have released Version 0.9.6 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Corrected a problem with command line argument construction within BigQuery exportAs() clauses in a Kerberized cluster.
01/22/2018 - Release 0.9.5
We have released Version 0.9.5 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Export your views to Google Cloud Platform's BigQuery via a simple exportAs() statement.
10/12/2017 - Release 0.9.4
We have released Version 0.9.4 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Emergency bug fix for Schedoscope crashing upon exports. Do not use 0.9.3!
10/11/2017 - Release 0.9.3
We have released Version 0.9.3 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Minor bug fix. Show view name in resource manager also for transformations of views that have exportAs statements.
09/21/2017 - Release 0.9.2
We have released Version 0.9.2 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Minor bug fixes. Improved Metascope performance by optionally circumventing the Hive Metastore API and accessing the Metastore DB directly.
08/17/2017 - Release 0.9.1
We have released Version 0.9.1 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
We fixed a bug in the Spark driver that could lead to incomplete consumption of the error stream of the Spark submit subprocess resulting in transformation freezes.
08/11/2017 - Release 0.9.0
We have released Version 0.9.0 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This release upgrades Spark transformations from Spark version 1.6.0 to Spark version 2.2.0 based on Cloudera's CDH 5.12 Spark 2.2 beta parcel. As a consequence, Schedoscope has been lifted to Scala 2.11 and JDK8 as well.
This is an incompatible change likely requiring adaptation of Spark jobs, dependencies, and build pipelines of existing Schedoscope projects - hence the incrememtation of the minor release number.
08/04/2017 - Release 0.8.9
We have released Version 0.8.9 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This release contains the following enhancements and changes:
- Cloudera client libraries updated to CDH-5.12.0;
- a DistCp transformation for view materialization by parallel, cross-cluser file copying;
- a new development mode setup that helps developers to easily copy data from a production environment to the direct dependencies of the view they are developing;
- shell transformations had to be moved back into
schedoscope-coreto facilitate development mode; - a versioning issue with the Scala Maven compiler plugin with regard to Scala 2.10 was fixed so that finally Schedoscope compiles and runs under JDK8 as well.
07/04/2017 - Release 0.8.7
We have released Version 0.8.7 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This version contains a critical Metascope bugfix introduced with the last version preventing startup. Also, finally Metascope field lineage documentation has been provided in the View DSL Primer and the Metascope Primer.
06/23/2017 - Release 0.8.6
We have released Version 0.8.6 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This version includes support for field level data lineage - automatically inferred from Hive transformations, declaratively specifyable for other transformations - in Metascope. Also, Metascope lineage graph rendering has been reworked. Extensive documentation to come.
Schedoscope now fails immediately if a driver specified in schedoscope.conf cannot be found on the classpath.
05/26/2017 - Release 0.8.5
We have released Version 0.8.5 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This version adds support for float view fields to JDBC exports
05/24/2017 - Release 0.8.4
We have released Version 0.8.4 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This version removes a race condition the file system driver initialization that seems to have been introduced with CDH-5.10. Also, we have changed the way how we delete and recreate output folders for Map/Reduce transformations to avoid Hive partitions pointing to temporarily non-existing folders.
04/24/2017 - Release 0.8.3
We have released Version 0.8.3 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This version has been built against Cloudera's CDH 5.10.1 client libraries. The test framework no longer artificially sets the storage formats of views under test to text, making testing of Spark jobs writing Parquet files simpler. The robustness of the Schedoscope HTTP service has been improved in face of invalid view parameters.
03/24/2017 - Release 0.8.2
We have released Version 0.8.2 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This version provides significant performance improvements when initializing the scheduling state for a large number of views.
03/18/2017 - Release 0.8.1
We have released Version 0.8.1 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
This fixes a critical bug that could result in applying commands to all views in a table and not just the ones addressed. Do not use Release 0.8.0
03/17/2017 - Release 0.8.0
We have released Version 0.8.0 as a Maven artifact to our Bintray repository (see Setting Up A Schedoscope Project for an example pom).
Schedoscope 0.8.0 includes, among other things:
- significant rework of Schedoscope's actor system that supports testing and uses significantly fewer actors reducing stress for poor Akka;
- support for a lot more Hive storage formats;
- definition of arbitrary Hive table properties / SerDes;
- stability, performance, and UI improvements to Metascope;
- the names of views being transformed appear as the job name in the Hadoop resource manager.
Please note that Metascope's database schema has changed with this release, so back up your database before deploying.
Community / Forums
- Google Groups: Schedoscope Users
- Twitter: @Schedoscope
Build Status

License
Licensed under the Apache License 2.0