Awesome
arrcmp
high performance alternative to glibc's memcmp. Also demonstrating concept of using TMP with intrinsics for optimised assembly code.
This approach was presented as a lightning talk at C++ On Sea 2022, titled: "C++ your friendly meta assembler - or how to beat memcmp" https://www.youtube.com/watch?v=v6ENImXcsPE
Installing dependencies (for ubuntu)
# Google test and Google Benchmark
sudo apt install libgtest-dev libbenchmark-dev
# Google Benchmark plot
git submodule update --init --recursive
# the benchmark executable links against asmlib for comparison.
# the object file for the gcc/clang/intel 64-bit ELF version of asmlib in included in /ext
# and will be automatically linked against.
Building
Best results with clang-14 or newer:
cmake -B build -S . -DCMAKE_BUILD_TYPE=RELEASE -DCMAKE_CXX_COMPILER=clang++-14 -DCMAKE_C_COMPILER=clang-14
cmake --build build
Tests and benchmarks will be run automatically
run bench/run_and_graph_results.sh to produce CSV results and plot them with google_benchmark_plot/plot.py.
For the impatient the results, are included as CSV and png in bench folder and below...
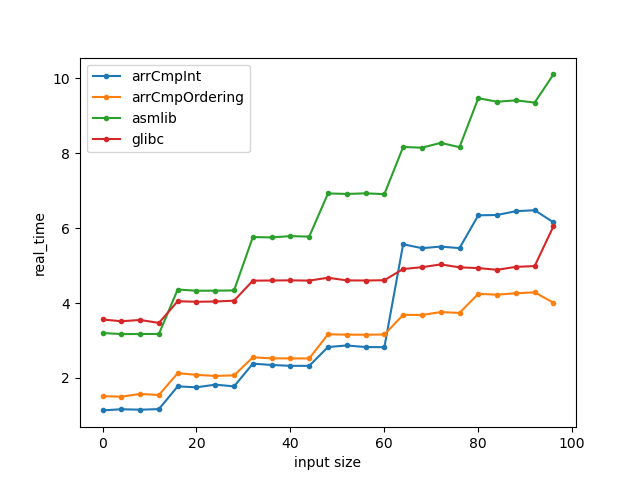
Sandybridge i7 CPU (SSE2) - glibc 2.35
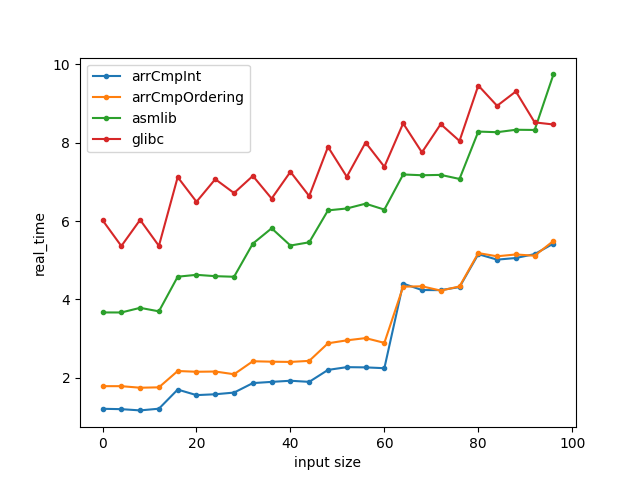
Skylake i7 CPU (AVX2) - glibc 2.35
Changes with glibc 2.39
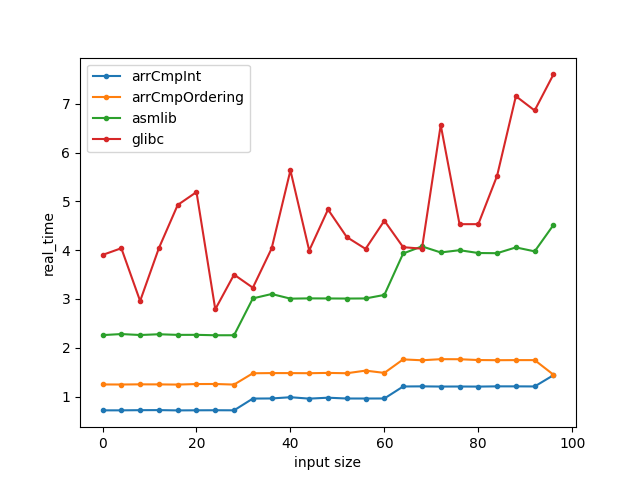
Some improvements were made in glibc, which now means asmlib is not faster anymore, but arrcmp still is:
Ivy Bridge i5 CPU (SSE2) - glibc 2.39 - clang
some weird artifacts about 60bytes for gcc
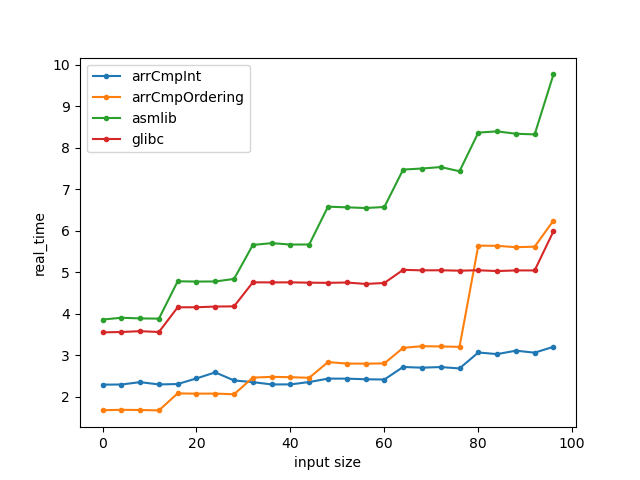
Ivy Bridge i5 CPU (SSE2) - glibc 2.39 - gcc