Awesome
JesterJ
A highly flexible, scalable, fault-tolerant document ingestion system designed for search.
![]()
![]()
Builds are run on infrastructure kindly donated by <img align="top" src="https://crave.io/wp-content/uploads/2022/09/Crave_logo_black_bg-e1663023213710.png" alt="" width="100px" height="26px">
The problem
Frequently, search projects start by feeding a few documents manually to a search engine, often via the "just for testing" built in processing features of Solr such as SolrCell or post.jar. These features are documented and included in order to help the user get a feel for what they can do with Solr with a minimum of painful setup.
This is good and that's how it should be for first explorations. Unfortunately it's also a potential trap.
All too often, users who don't know any better, and are perhaps mislead by the fact that these interfaces are documented in the reference manual (and assume anything documented must be "the right way" to do it) continue developing their search system by automating the use of those same interfaces. In fairness to those users, some older versions of the Solr Ref guide failed to identify the "just for testing" nature of the interface, sometimes because it took a while for the community to realize the pitfalls associated with it.
Unfortunately, large scale ingestion of documents for search is non-trivial and those indexing interfaces not meant for production use. The usual result is that it works "ok" for a small test corpus and then becomes unstable on a larger production corpus. The code written to feed into such interfaces often needs to be repeated for several types of documents or for various document formats, and can easily lead to duplication and cut and paste copying of common functionality. Also, after investing substantial engineering to get such solutions working on a large corpus, the next thing they discover is that they have no way to recover if indexing fails part way through. In the worst cases the failure is related to the size of the corpus and the failures become increasingly common as the corpus grows until the chance of completing and indexing run is small and the system eventually cannot be indexed or upgraded at all if the problem is allowed to fester. The result is a terrible, painful and potentially expensive set of growing pains.
JesterJ's solution
JesterJ endeavors to make it easy to start with a robust full featured indexing infrastructure, so that you don't have to re-invent the wheel. JesterJ is meant to be a system you won't need to abandon until you are working with extremely large numbers of documents (and hopefully by that point you are already making good profits that can pay for a large custom solution!). A variety of re-usable processing components are provided and writing your own custom processors is as simple as implementing a 4 method interface following some simple guidelines.
Often the first version of a system for indexing documents into Solr or other search engine is fairly linear and straight forward, but as time passes features and enhancements often add complexity. Other times, the system is complex from the very start, possibly because search is being added to an existing system. JesterJ is designed to handle complex indexing scenarios. Consider the following hypothetical indexing workflow:
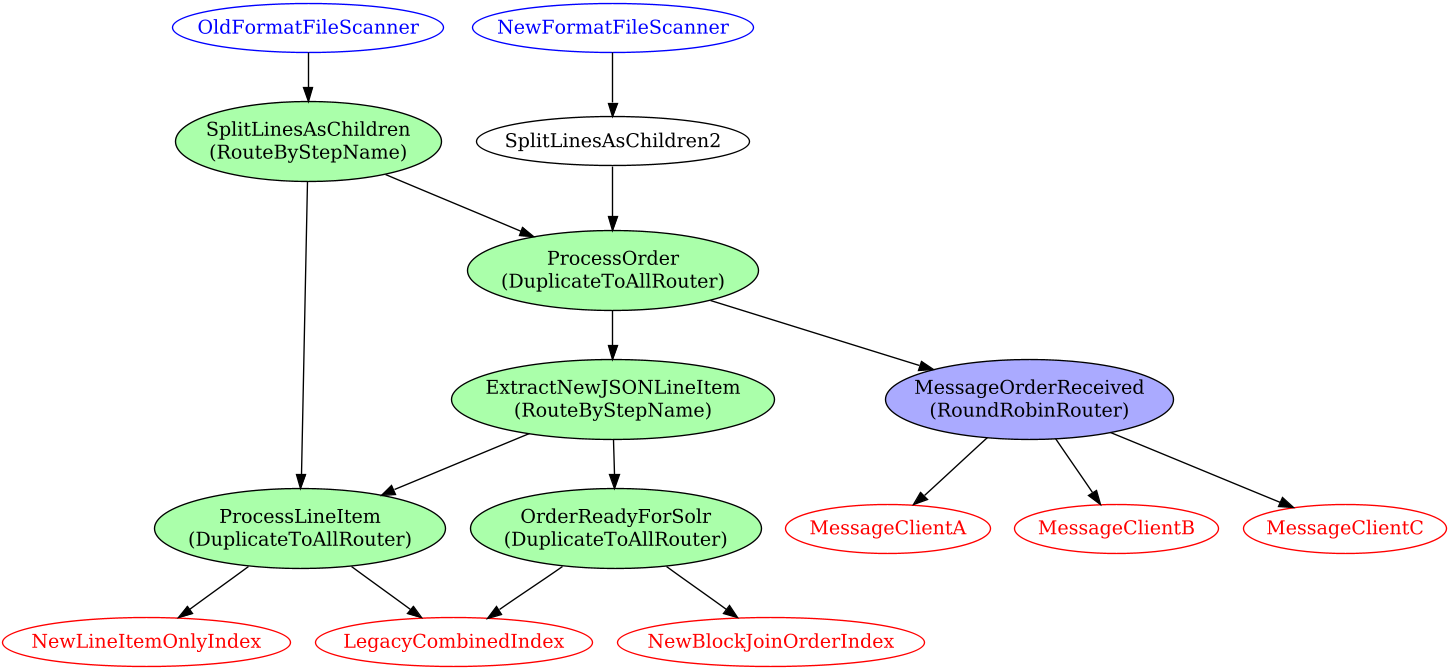
JesterJ handles such scenarios with a single centralized processing plan, and will ensure that if the system is unplugged, you won't get a second message about an order received. The default mode for JesterJ is to ensure at most once delivery for steps that are not marked safe or idempotent. Safe steps do not have external effects, and idempotent steps may be repeated en-route to the final processing end point.
See the website and the documentation for more info
Getting Started
Please see the documentation in the wiki
Project Status
Current release: 1.0-Beta3. This is the best version to use, and should be mostly functional. (known issue: https://github.com/nsoft/jesterj/issues/189)
Next Release: 1.0-Beta4 will be published soon if no serious issues are found in within two weeks 1.0 will be released.
NOTE: The current code and the upcoming 1.0 release target any design and load that can be serviced by a single machine. JesterJ is explicitly designed to take advantage of machines with many processors. You can design your plan with duplicates of your slowest step to alleviate bottlenecks. Each duplicate implies an additional thread working on that step. Automatic scaling of threads is planned for 1.1 and Scaling across many machines is a key priority for the 2.x releases. As always, if you want these features sooner, please start a discussion and contribute a PR if you are able!
JDK versions
Presently only JDK 11 has been tested regularly. Any Distribution of JDK 11 should work. Support for Java 17 and future LTS versions is planned for future releases.
Discord Server
Discuss features, ask questions etc on Discord: https://discord.gg/RmdTYvpXr9
Features:
In this release we have the following features
- Ability to visualize the structure of your plan (.dot or .png format: example from unit tests here )
- Simple filesystem scanner for locally mounted drives (replacement for post.jar)
- JDBC scanner (replacement for Data Import Handler!)
- Scanners can remember what documents they've seen (or not, boolean flag)
- Scanners can recognize updated content (or not, boolean flag)
- Send to Solr processor with tunable batch sizes
- Tika processor to extract content from Word/PDF/xml/html, etc (Replacement for SolrCell!)
- Stax extract processor for dissecting xml documents directly.
- Copy field processor to rename source fields to desired index field
- Regexp replace processor to edit field content, or drop fields that don't match
- Split field processor to split delimited values for multi-value fields
- Drop field processor to get rid of annoying excess fields.
- Field template processor for composing field content using a velocity template
- URL encode processor to encode the value of a field and make it safe for use in URLs
- Fetch URL processor for acquiring or enhancing content by contacting other systems
- Log and drop processor for when you identify an invalid docuemnt
- Date Reformat processor, because dates, formatting... always. (sigh)
- Human Readable File Size processor
- Solr sender to send documents to solr in batches.
- Pre-Analyze processor to move Solr analysis workload out of Solr (just give it your schema.xml!)
- Embedded Cassandra server (no need to install cassandra yourself!)
- Cassandra config and data location configurable, defaults to
~/.jj/cassandra - Support for fault tolerance writing status change events to the embedded cassandra server
- Initial API/process for user written document processors. (see documentation)
- 60% test coverage (jacoco)
- Simple, single java file to configure everything, non-java programmers need only follow a simple example (for use cases not requiring custom code)
- If you DO need custom code that code can be packaged as an uno-jar to provide all required dependencies and escape from any library versions that JesterJ uses! You only have to deal with your OWN jar hell, not ours! Of course, you can also just rely on whatever we already provide too. The classloaders for custom code prefer your uno-jar and then default back to whatever JesterJ has available on it's classpath.
- Runnable example to execute a plan that scans a filesystem, and indexes the documents in solr.
TODO for 1.0 final release
- Remaining issues
- Beta release, testing.
Release 1.0 is intended to be the usable for single node systems, and therefore suitable for use on small to medium-sized projects (tens of millions or maybe low hundreds of million of documents).
Road Map
The best guess at any time of what will be in future releases is given by the milestones filters on our issues page