Awesome
<p align="center"> <picture> <img alt="MInference" src="https://raw.githubusercontent.com/microsoft/MInference/main/images/MInference_logo.png" width=70%> </picture> </p> <h2 align="center">MInference: Million-Tokens Prompt Inference for Long-context LLMs</h2> <p align="center"> | <a href="https://aka.ms/MInference"><b>Project Page</b></a> | <a href="https://arxiv.org/abs/2407.02490"><b>Paper</b></a> | <a href="https://huggingface.co/spaces/microsoft/MInference"><b>HF Demo</b></a> | <a href="https://aka.ms/SCBench"><b>SCBench</b></a> | </p>https://github.com/microsoft/MInference/assets/30883354/52613efc-738f-4081-8367-7123c81d6b19
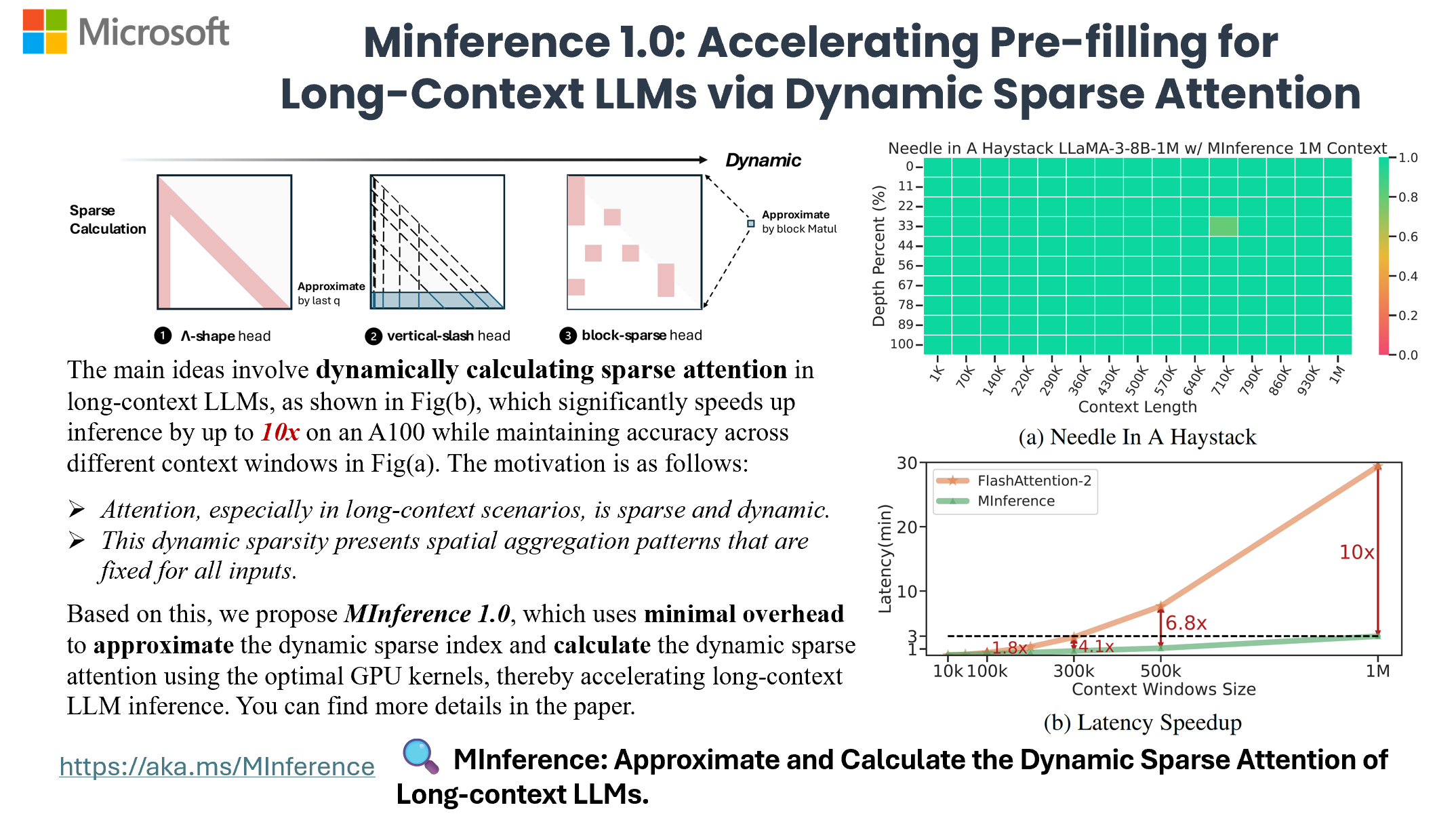
Now, you can process 1M context 10x faster in a single A100 using Long-context LLMs like LLaMA-3-8B-1M, GLM-4-1M, with even better accuracy, try MInference 1.0 right now!
News
- 🍩 [24/12/13] We are excited to announce the release of our KV cache-centric analysis work, SCBench, which evaluates long-context methods from a KV cache perspective.
- 🧤 [24/09/26] MInference has been accepted as spotlight at NeurIPS'24. See you in Vancouver!
- 👘 [24/09/16] We are pleased to announce the release of our KV cache offloading work, RetrievalAttention, which accelerates long-context LLM inference via vector retrieval.
- 🥤 [24/07/24] MInference support meta-llama/Meta-Llama-3.1-8B-Instruct now.
- 🪗 [24/07/07] Thanks @AK for sponsoring. You can now use MInference online in the HF Demo with ZeroGPU.
- 📃 [24/07/03] Due to an issue with arXiv, the PDF is currently unavailable there. You can find the paper at this link.
- 🧩 [24/07/03] We will present MInference 1.0 at the Microsoft Booth and ES-FoMo at ICML'24. See you in Vienna!
TL;DR
MInference 1.0 leverages the dynamic sparse nature of LLMs' attention, which exhibits some static patterns, to speed up the pre-filling for long-context LLMs. It first determines offline which sparse pattern each head belongs to, then approximates the sparse index online and dynamically computes attention with the optimal custom kernels. This approach achieves up to a 10x speedup for pre-filling on an A100 while maintaining accuracy.
- MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention (NeurIPS'24 spotlight, ES-FoMo @ ICML'24)<br> Huiqiang Jiang†, Yucheng Li†, Chengruidong Zhang†, Qianhui Wu, Xufang Luo, Surin Ahn, Zhenhua Han, Amir H. Abdi, Dongsheng Li, Chin-Yew Lin, Yuqing Yang and Lili Qiu
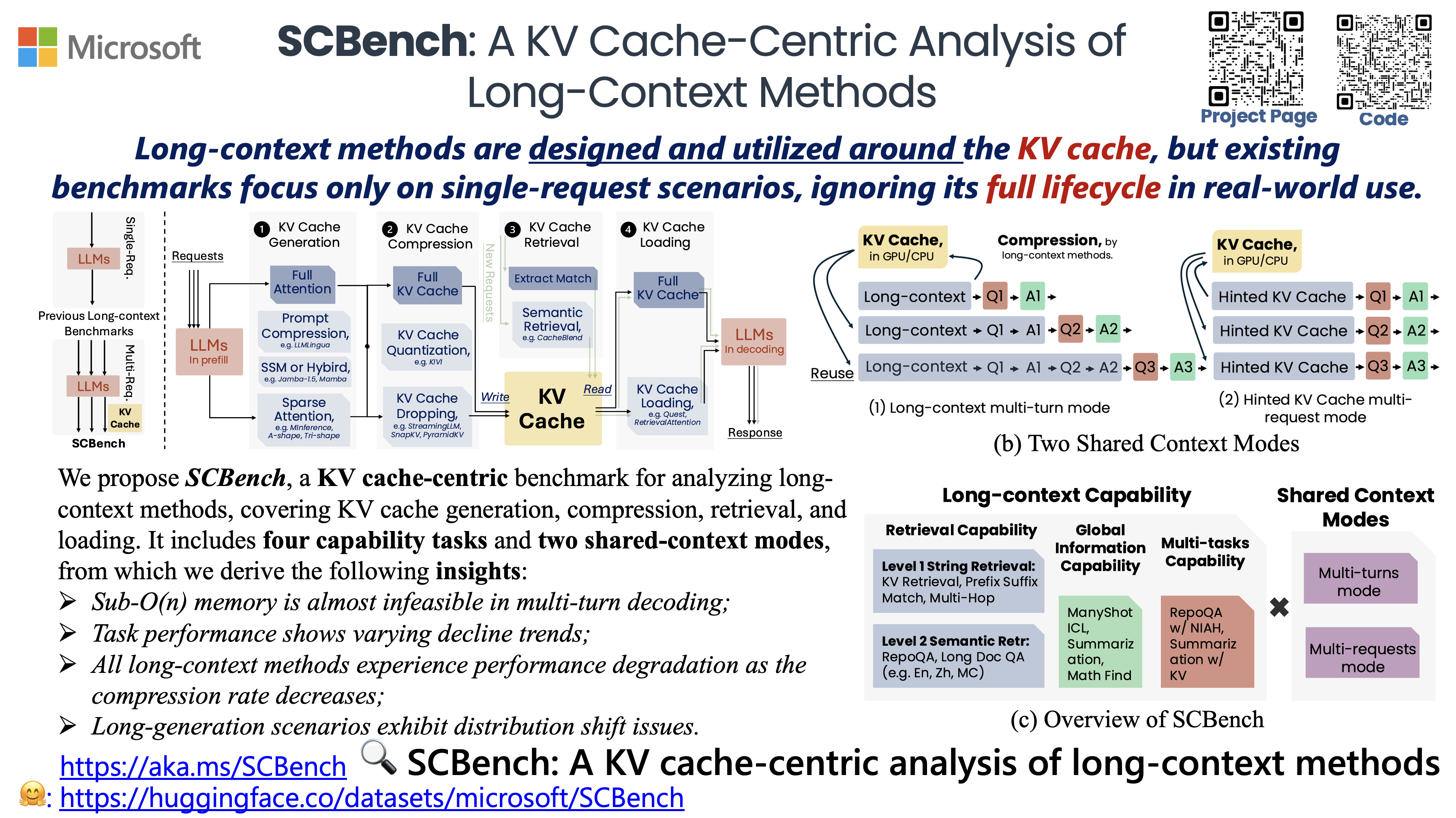
SCBench analyzes long-context methods from a KV cache-centric perspective across the full KV cache lifecycle (e.g., KV cache generation, compression, retrieval, and loading). It evaluates 12 tasks under two shared context modes, covering four categories of long-context capabilities: string retrieval, semantic retrieval, global information, and multi-task scenarios.
- SCBench: A KV Cache-Centric Analysis of Long-Context Methods (Under Review, ENLSP @ NeurIPS'24)<br> Yucheng Li, Huiqiang Jiang, Qianhui Wu, Xufang Luo, Surin Ahn, Chengruidong Zhang, Amir H. Abdi, Dongsheng Li, Jianfeng Gao, Yuqing Yang and Lili Qiu
🎥 Overview
🎯 Quick Start
Requirements
- Torch
- FlashAttention-2 (Optional)
- Triton == 2.1.0
To get started with MInference, simply install it using pip:
pip install minference
Supported Models
General MInference supports any decoding LLMs, including LLaMA-style models, and Phi models. We have adapted nearly all open-source long-context LLMs available in the market. If your model is not on the supported list, feel free to let us know in the issues, or you can follow the guide to manually generate the sparse heads config.
You can get the complete list of supported LLMs by running:
from minference import get_support_models
get_support_models()
Currently, we support the following LLMs:
- LLaMA-3.1: meta-llama/Meta-Llama-3.1-8B-Instruct
- LLaMA-3: gradientai/Llama-3-8B-Instruct-262k, gradientai/Llama-3-8B-Instruct-Gradient-1048k, gradientai/Llama-3-8B-Instruct-Gradient-4194k, gradientai/Llama-3-70B-Instruct-Gradient-262k, gradientai/Llama-3-70B-Instruct-Gradient-1048k
- GLM-4: THUDM/glm-4-9b-chat-1m
- Yi: 01-ai/Yi-9B-200K
- Phi-3: microsoft/Phi-3-mini-128k-instruct
- Qwen2: Qwen/Qwen2-7B-Instruct
How to use MInference
for HF,
from transformers import pipeline
+from minference import MInference
pipe = pipeline("text-generation", model=model_name, torch_dtype="auto", device_map="auto")
# Patch MInference Module,
# If you use the local path, please use the model_name from HF when initializing MInference.
+minference_patch = MInference("minference", model_name)
+pipe.model = minference_patch(pipe.model)
pipe(prompt, max_length=10)
for vLLM,
For now, please use vllm>=0.4.1
from vllm import LLM, SamplingParams
+ from minference import MInference
llm = LLM(model_name, enforce_eager=True, max_model_len=128_000, enable_chunked_prefill=False)
# Patch MInference Module,
# If you use the local path, please use the model_name from HF when initializing MInference.
+minference_patch = MInference("vllm", model_name)
+llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)
for vLLM w/ TP,
- Copy
minference_patch_vllm_tpandminference_patch_vllm_executorfromminference/patch.pyto the end of theWorkerclass invllm/worker/worker.py. Make sure to indentminference_patch_vllm_tp. - When calling VLLM, ensure
enable_chunked_prefill=Falseis set. - Refer to the script in https://github.com/microsoft/MInference/blob/hjiang/support_vllm_tp/experiments/benchmarks/run_e2e_vllm_tp.sh
from vllm import LLM, SamplingParams
+ from minference import MInference
llm = LLM(model_name, enforce_eager=True, max_model_len=128_000, enable_chunked_prefill=False, tensor_parallel_size=2)
# Patch MInference Module,
# If you use the local path, please use the model_name from HF when initializing MInference.
+minference_patch = MInference("vllm", model_name)
+llm = minference_patch(llm)
outputs = llm.generate(prompts, sampling_params)
using only the kernel,
from minference import vertical_slash_sparse_attention, block_sparse_attention, streaming_forward
attn_output = vertical_slash_sparse_attention(q, k, v, vertical_topk, slash)
attn_output = block_sparse_attention(q, k, v, topk)
attn_output = streaming_forward(q, k, v, init_num, local_window_num)
for a local gradio demo <a href='https://github.com/gradio-app/gradio'><img src='https://img.shields.io/github/stars/gradio-app/gradio'></a>
git clone https://huggingface.co/spaces/microsoft/MInference
cd MInference
pip install -r requirments.txt
pip install flash_attn
python app.py
For more details, please refer to our Examples and Experiments. You can find more information about the dynamic compiler PIT in this paper and on GitHub.
SCBench
Load Data
You can download and load the SCBench data through the Hugging Face datasets (🤗 HF Repo):
from datasets import load_dataset
datasets = ["scbench_kv", "scbench_prefix_suffix", "scbench_vt", "scbench_repoqa", "scbench_qa_eng", "scbench_qa_chn", "scbench_choice_eng", "scbench_many_shot", "scbench_summary", "scbench_mf", "scbench_summary_with_needles", "scbench_repoqa_and_kv"]
for dataset in datasets:
data = load_dataset('microsoft/SCBench', dataset, split='train')
Data Format
All data in SCBench are standardized to the following format:
{
"id": "Random id for each piece of data.",
"context": "The long context required for the task, such as repo-code, long-document, and many-shot.",
"multi_turns": [{"input": "multi-turn question.", "answer": "multi-turn reference answer."}],
}
Experiments
We implement Multi-Turn and Multi-Request modes with HF and vLLM in GreedySearch and GreedySearch_vllm two class. Please refer the follow scripts to run the experiments.
cd scbench
bash scripts/run_all_tasks.sh
FAQ
For more insights and answers, visit our FAQ section.
Q1: How to effectively evaluate the impact of dynamic sparse attention on the capabilities of long-context LLMs?
To evaluate long-context LLM capabilities using models like LLaMA-3-8B-Instruct-1M and GLM-4-9B-1M, we tested: 1) context window with RULER, 2) general tasks with InfiniteBench, 3) retrieval tasks with Needle in a Haystack, and 4) language model prediction with PG-19.<br/> We found traditional methods perform poorly in retrieval tasks, with difficulty levels as follows: <font color="#337ab7"><b>KV retrieval > Needle in a Haystack > Retrieval.Number > Retrieval PassKey</b></font>. The main challenge is the semantic difference between needles and the haystack. Traditional methods excel when this difference is larger, as in passkey tasks. KV retrieval requires higher retrieval capabilities since any key can be a target, and multi-needle tasks are even more complex.<br/> We will continue to update our results with more models and datasets in future versions.
Q2: Does this dynamic sparse attention pattern only exist in long-context LLMs that are not fully trained?
Firstly, attention is dynamically sparse, a characteristic inherent to the mechanism. We selected state-of-the-art long-context LLMs, GLM-4-9B-1M and LLaMA-3-8B-Instruct-1M, with effective context windows of 64K and 16K. With MInference, these can be extended to 64K and 32K, respectively. We will continue to adapt our method to other advanced long-context LLMs and update our results, as well as explore the theoretical basis for this dynamic sparse attention pattern.
Q3: Does this dynamic sparse attention pattern only exist in Auto-regressive LMs or RoPE based LLMs?
Similar vertical and slash line sparse patterns have been discovered in BERT[1] and multi-modal LLMs[2]. Our analysis of T5's attention patterns, shown in the figure, reveals these patterns persist across different heads, even in bidirectional attention.<br/> [1] SparseBERT: Rethinking the Importance Analysis in Self-Attention, ICML 2021.<br/> [2] LOOK-M: Look-Once Optimization in KV Cache for Efficient Multimodal Long-Context Inference, 2024.<br/>
<p align="center"> <img src="https://raw.githubusercontent.com/microsoft/MInference/main/images/t5_sparse_pattern.png" width="600px" style="margin:auto;border-radius: 5px;display: inline-block;padding: 0 0 0 10px;" alt=''> </p> <p align="center">Figure 1. The sparse pattern in T5 Encoder.</p>Q4: What is the relationship between MInference, SSM, Linear Attention, and Sparse Attention?
All four approaches (MInference, SSM, Linear Attention, and Sparse Attention) efficiently optimize attention complexity in Transformers, each introducing inductive bias differently. The latter three require training from scratch. Recent works like Mamba-2 and Unified Implicit Attention Representation unify SSM and Linear Attention as static sparse attention, with Mamba-2 itself being a block-wise sparse method. While these approaches show potential due to sparse redundancy in attention, static sparse attention may struggle with dynamic semantic associations in complex tasks. In contrast, dynamic sparse attention is better suited for managing these relationships.
Citation
If you find MInference useful or relevant to your project and research, please kindly cite our paper:
@article{jiang2024minference,
title={MInference 1.0: Accelerating Pre-filling for Long-Context LLMs via Dynamic Sparse Attention},
author={Jiang, Huiqiang and Li, Yucheng and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Han, Zhenhua and Abdi, Amir H and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili},
journal={arXiv preprint arXiv:2407.02490},
year={2024}
}
Contributing
This project welcomes contributions and suggestions. Most contributions require you to agree to a Contributor License Agreement (CLA) declaring that you have the right to, and actually do, grant us the rights to use your contribution. For details, visit https://cla.opensource.microsoft.com.
When you submit a pull request, a CLA bot will automatically determine whether you need to provide a CLA and decorate the PR appropriately (e.g., status check, comment). Simply follow the instructions provided by the bot. You will only need to do this once across all repos using our CLA.
This project has adopted the Microsoft Open Source Code of Conduct. For more information see the Code of Conduct FAQ or contact opencode@microsoft.com with any additional questions or comments.
Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow Microsoft's Trademark & Brand Guidelines. Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party's policies.