Awesome
Multi-omics: state of the field

![]()
Analyses for State of the Field in Multi-Omics Research: From Computational Needs to Data Mining and Sharing.
Overview
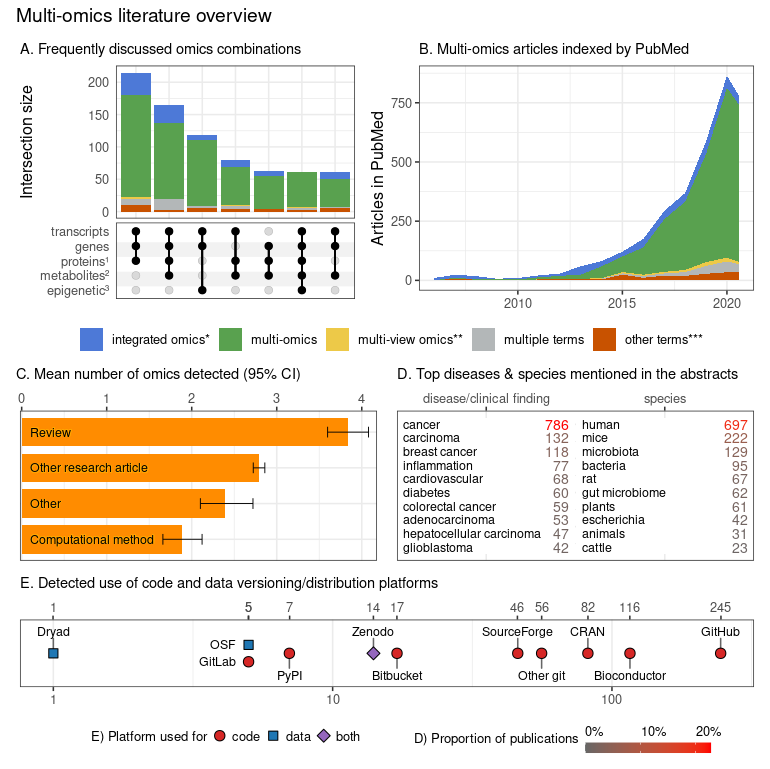
Figure 1. Characterization of multi-omics literature based on a systematic screen of PubMed indexed articles (up to July 2020).
The comprehensive search terms (see the online repository for details) were collapsed into four categories; integrated omics (*) includes integromics and integrative omics, multi-view (**) includes multi-view|block|source|modal omics, other terms (***) include pan-, trans-, poly-, cross-omics.
The subpanels present:
- A) Combinations of omics (grouped by the characterized entities) commonly discussed occurring together in multi-omics articles (intersections with ≥ 3 omics and at least 50 papers). The proteins group (1) also includes peptides; the metabolites group (2) includes other endogenous molecules; the epigenetic group (3) encompasses all epigenetic modifications.
- B) Trend plot representing the rapidly increasing number of multi-omics articles indexed in PubMed (also after adjusting for the number of articles published in matched journals - data not shown); the dip in 2020 can be attributed to indexing delay which was not accounted for in the current plot.
- C) Distribution of articles categories that mention different numbers of omics; while it is understandable that multi-omics Reviews category discuss many omics, the Computational method category articles appear to lag behind all other article category types. The detected number of omics may underestimate the actual numbers (due to the automated search strategy) but should put a useful lower bound on the number of omics discussed. Bootstrapped 95% confidence intervals around the mean are presented with the whiskers.
- D) The number of articles mentioning the most popular clinical findings, disease terms (here screening is based on ClinVar diseases list) and species (based upon NCBI Taxonomy database). Both databases were manually filtered down to remove ambiguous terms and merge plural/singular forms. Only the abstracts were screened here.
- E) The detected references to code, data versioning, distribution platforms and systems (links to repositories with deposited code/data); both the abstracts and full-texts (open-access subset, 44% of all articles) were screened. No manual curation to classify intent of the link inclusion (i.e. to share authors' code/data vs to report the use of a dataset/tool) was undertaken.
Methods
PubMed database was searched for articles pertaining to multi-omics on 25th July 2020, using fourteen terms (multi|pan|trans|poly|cross-omics, multi-table|source|view|modal|block omics, integrative omics, integrated omics and integromics) including plural/singular and hyphenated/unhyphenated variants combinations. The search was automated via Entrez E-utilities API and restricted to Text Words (to avoid matching articles based on the affiliation of authors to companies such as Panomics, Inc. or Integromics S.L.); the full text and additional metadata were retrieved from the PubMed Central (PMC) database for the open access subset of articles. The feature extraction was performed via n-gram matching against ClinVar (diseases & clinical findings) and NCBI Taxonomy (species) databases, while omics references annotation was based on regular expressions capturing phrases with suffix -ome or -omic (accounting for multi-omic phrases and plural variants). All matches were manually filtered down to exclude false or irrelevant matches and to merge plural forms. The article type was collated from five sources:
- MeSH PublicationType as provided by PubMed,
- community-maintained list of multi-omics software packages and methods: mikelove/awesome-multi-omics,
- PMC-derived:
- ArticleType and
- Subjects (journal-specific);
- manual annotation of articles published in Bioinformatics (Oxford, UK) due to lack of methods subject annotations in PMC data for this journal (performed by MK)
Flow diagram
<img src="https://github.com/krassowski/multi-omics-state-of-the-field/blob/master/figures/flowchart.png?raw=true" title="Flowchart with counts" width=500>Figure 2. A flow diagram of the semi-automated multi-omics literature screening effort (up to July 2020).
Code overview

Figure 3. Overview of the notebooks in this code repository. Click on the plot to display an interactive version, from where you can open respective notebooks by clicking on the analysis nodes.
Reference
This analysis was contributed to our introductory review of multi-omics field, now published in Frontiers in Genetics (open access):
Krassowski M, Das V, Sahu SK and Misra BB (2020) State of the Field in Multi-Omics Research: From Computational Needs to Data Mining and Sharing. Front. Genet. 11:610798. doi: 10.3389/fgene.2020.610798
Reproducing
Prerequisites:
- Ubuntu: 20.04 (x64)
- Python: 3.8.3
- R: 3.6.3
Install the minimal requirements for reproduction and download required data:
pip install -r setup/requirements.txt
Rscript helpers/restore.R
cd data
./download.sh
Development and contributing
Install additional requirements for development and testing:
pip install -r setup/requirements-dev.txt
Execute tests with:
python3 -m pytest
Freeze (snapshot) R requirements with:
Rscript helpers/freeze.R
Create the repository overview graph:
pip install nbpipeline
PYTHONPATH=$(pwd):$PYTHONPATH nbpipeline --dry_run -s -O figures/repository.svg --display_graph_with none