Awesome
PyTorch implementation of Interpretable Explanations of Black Boxes by Meaningful Perturbation
The paper: https://arxiv.org/abs/1704.03296
What makes the deep learning network think the image label is 'pug, pug-dog' and 'tabby, tabby cat':


A perturbation of the dog that caused the dog category score to vanish:

What makes the deep learning network think the image label is 'flute, transverse flute':

Usage: python explain.py <path_to_image>
This is a PyTorch impelentation of
"Interpretable Explanations of Black Boxes by Meaningful Perturbation. Ruth Fong, Andrea Vedaldi" with some deviations.
This uses VGG19 from torchvision. It will be downloaded when used for the first time.
This learns a mask of pixels that explain the result of a black box. The mask is learned by posing an optimization problem and solving directly for the mask values.
This is different than other visualization techniques like Grad-CAM that use heuristics like high positive gradient values as an indication of relevance to the network score.
In our case the black box is the VGG19 model, but this can use any differentiable model.
How it works
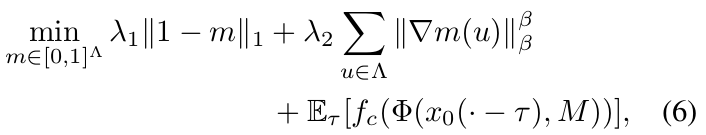
Taken from the paper https://arxiv.org/abs/1704.03296
The goal is to solve for a mask that explains why did the network output a score for a certain category.
We create a low resolution (28x28) mask, and use it to perturb the input image to a deep learning network.
The perturbation combines a blurred version of the image, the regular image, and the up-sampled mask.
Wherever the mask contains low values, the input image will become more blurry.
We want to optimize for the next properties:
- When using the mask to blend the input image and it's blurred versions, the score of the target category should drop significantly. The evidence of the category should be removed!
- The mask should be sparse. Ideally the mask should be the minimal possible mask to drop the category score. This translates to a L1(1 - mask) term in the cost function.
- The mask should be smooth. This translates to a total variation regularization in the cost function.
- The mask shouldn't over-fit the network. Since the network activations might contain a lot of noise, it can be easy for the mask to just learn random values that cause the score to drop without being visually coherent. In addition to the other terms, this translates to solving for a lower resolution 28x28 mask.
Deviations from the paper
The paper uses a gaussian kernel with a sigma that is modulated by the value of the mask. This is computational costly to compute since the mask values are updated during the iterations, meaning we need a different kernel for every mask pixel for every iteration.
Initially I tried approximating this by first filtering the image with a filter bank of varying gaussian kernels. Then during optimization, the input image pixel would use the quantized mask value to select an appropriate filter bank output pixel (high mask value -> lower channel).
This was done using the PyTorch variable gather/select_index functions. But it turns out that the gather and select_index functions in PyTorch are not differentiable by the indexes.
Instead, we just compute a perturbed image once, and then blend the image and the perturbed image using:
input_image = (1 - mask) * image + mask * perturbed_image
And it works well in practice.
The perturbed image here is the average of the gaussian and median blurred image, but this can really be changed to many other combinations (try it out and find something better!).
Also now gaussian noise with a sigma of 0.2 is added to the preprocssed image at each iteration, inspired by google's SmoothGradient.