Awesome
distribute_crawler
使用scrapy,redis, mongodb,graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现, 爬虫状态显示使用graphite实现。
这个工程是我对垂直搜索引擎中分布式网络爬虫的探索实现,它包含一个针对http://www.woaidu.org/ 网站的spider, 将其网站的书名,作者,书籍封面图片,书籍概要,原始网址链接,书籍下载信息和书籍爬取到本地:
- 分布式使用redis实现,redis中存储了工程的request,stats信息,能够对各个机器上的爬虫实现集中管理,这样可以 解决爬虫的性能瓶颈,利用redis的高效和易于扩展能够轻松实现高效率下载:当redis存储或者访问速度遇到瓶颈时,可以 通过增大redis集群数和爬虫集群数量改善。
- 底层存储实现了两种方式:
- 将书名,作者,书籍封面图片文件系统路径,书籍概要,原始网址链接,书籍下载信息,书籍文件系统路径保存到mongodb 中,此时mongodb使用单个服务器,对图片采用图片的url的hash值作为文件名进行存储,同时可以定制生成各种大小尺寸的缩略 图,对文件动态获得文件名,将其下载到本地,存储方式和图片类似,这样在每次下载之前会检查图片和文件是否曾经下载,对 已经下载的不再下载;
- 将书名,作者,书籍封面图片文件系统路径,书籍概要,原始网址链接,书籍下载信息,书籍保存到mongodb中,此时mongodb 采用mongodb集群进行存储,片键和索引的选择请看代码,文件采用mongodb的gridfs存储,图片仍然存储在文件系统中,在每次下载 之前会检查图片和文件是否曾经下载,对已经下载的不再下载;
- 避免爬虫被禁的策略:
- 禁用cookie
- 实现了一个download middleware,不停的变user-aget
- 实现了一个可以访问google cache中的数据的download middleware(默认禁用)
- 调试策略的实现:
- 将系统log信息写到文件中
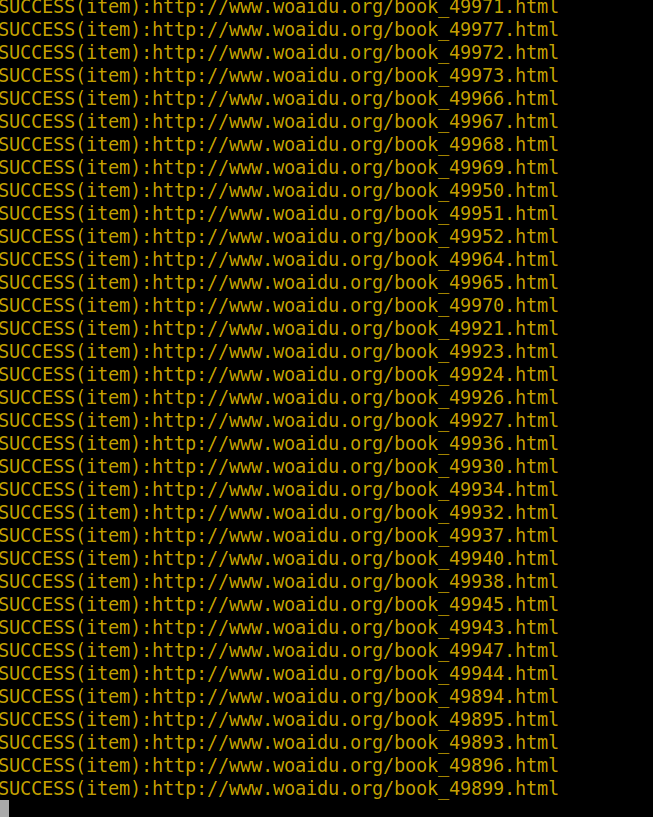
- 对重要的log信息(eg:drop item,success)采用彩色样式终端打印
- 文件,信息存储:
- 实现了FilePipeline可以将指定扩展名的文件下载到本地
- 实现了MongodbWoaiduBookFile可以将文件以gridfs形式存储在mongodb集群中
- 实现了SingleMongodbPipeline和ShardMongodbPipeline,用来将采集的信息分别以单服务器和集群方式保存到mongodb中
- 访问速度动态控制:
- 跟据网络延迟,分析出scrapy服务器和网站的响应速度,动态改变网站下载延迟
- 配置最大并行requests个数,每个域名最大并行请求个数和并行处理items个数
- 爬虫状态查看:
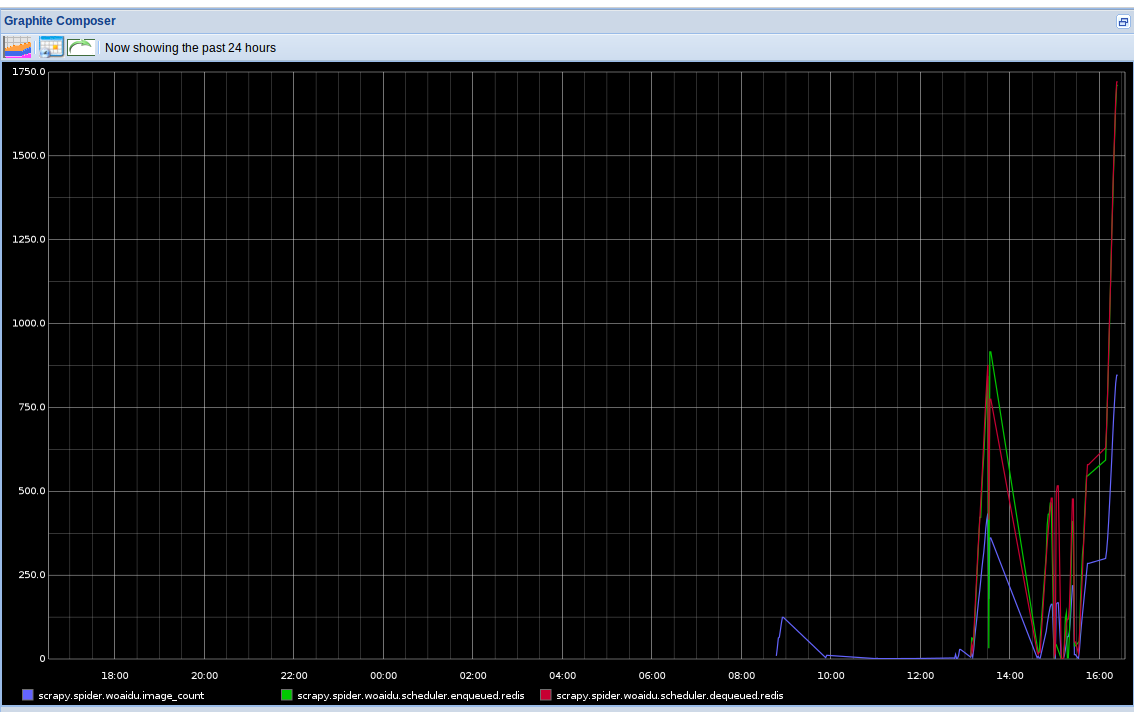
- 将爬虫stats信息(请求个数,文件下载个数,图片下载个数等)保存到redis中
- 实现了一个针对分布式的stats collector,并将其结果用graphite以图表形式动态实时显示
- mongodb集群部署:在commands目录下有init_sharding_mongodb.py文件,可以方便在本地部署
需要的其他的库
- scrapy(最好是最新版)
- graphite(针对他的配置可以参考:statscol/graphite.py)
- redis
- mongodb
可重用的组件
- 终端彩色样式显示(utils/color.py)
- 在本地建立一个mongodb集群(commands/init_sharding_mongodb.py),使用方法:
sudo python init_sharding_mongodb.py --path=/usr/bin
- 单机graphite状态收集器(statscol.graphite.GraphiteStatsCollector)
- 基于redis分布式的graphite状态收集器(statscol.graphite.RedisGraphiteStatsCollector)
- scrapy分布式处理方案(scrapy_redis)
- rotate user-agent download middleware(contrib.downloadmiddleware.rotate_useragent.RotateUserAgentMiddleware)
- 访问google cache的download middleware(contrib.downloadmiddleware.google_cache.GoogleCacheMiddleware)
- 下载指定文件类型的文件并实现避免重复下载的pipeline(pipelines.file.FilePipeline)
- 下载制定文件类型的文件并提供mongodb gridfs存储的pipeline(pipelines.file.MongodbWoaiduBookFile)
- item mongodb存储的pipeline(pipelines.mongodb.SingleMongodbPipeline and ShardMongodbPipeline)
使用方法
#mongodb集群存储
- 安装scrapy
- 安装redispy
- 安装pymongo
- 安装graphite(如何配置请查看:statscol/graphite.py)
- 安装mongodb
- 安装redis
- 下载本工程
- 启动redis server
- 搭建mongodb集群
cd woaidu_crawler/commands/
sudo python init_sharding_mongodb.py --path=/usr/bin
- 在含有log文件夹的目录下执行:
scrapy crawl woaidu
- 打开http://127.0.0.1/ 通过图表查看spider实时状态信息
- 要想尝试分布式,可以在另外一个目录运行此工程
#mongodb
- 安装scrapy
- 安装redispy
- 安装pymongo
- 安装graphite(如何配置请查看:statscol/graphite.py)
- 安装mongodb
- 安装redis
- 下载本工程
- 启动redis server
- 搭建mongodb服务器
cd woaidu_crawler/commands/
python init_single_mongodb.py
- 设置settings.py:
ITEM_PIPELINES = ['woaidu_crawler.pipelines.cover_image.WoaiduCoverImage',
'woaidu_crawler.pipelines.bookfile.WoaiduBookFile',
'woaidu_crawler.pipelines.drop_none_download.DropNoneBookFile',
'woaidu_crawler.pipelines.mongodb.SingleMongodbPipeline',
'woaidu_crawler.pipelines.final_test.FinalTestPipeline',]
- 在含有log文件夹的目录下执行:
scrapy crawl woaidu
- 打开http://127.0.0.1/ (也就是你运行的graphite-web的url) 通过图表查看spider实时状态信息
- 要想尝试分布式,可以在另外一个目录运行此工程
注意
每次运行完之后都要执行commands/clear_stats.py文件来清除redis中的stats信息
python clear_stats.py
Screenshots