Awesome
BORE (Burst-Oriented Response Enhancer) CPU Scheduler
BORE (Burst-Oriented Response Enhancer) is enhanced versions of CFS (Completely Fair Scheduler) and EEVDF (Earliest Eligible Virtual Deadline First) Linux schedulers. Developed with the aim of maintaining these schedulers' high performance while delivering resilient responsiveness to user input under as versatile load scenario as possible.
To achieve this, BORE introduces a dimension of flexibility known as "burstiness" for each individual tasks, partially departing from CFS's inherent "complete fairness" principle. Burstiness refers to the score derived from the accumulated CPU time a task consumes after explicitly relinquishing it, either by entering sleep, IO-waiting, or yielding. This score represents a broad range of temporal characteristics, spanning from nanoseconds to hundreds of seconds, varying across different tasks.
Leveraging this burstiness metric, BORE dynamically adjusts scheduling properties such as weights and delays for each task. Consequently, in systems experiencing diverse types of loads, BORE prioritizes tasks requiring high responsiveness, thereby improving overall system responsiveness and enhancing the user experience.
Demo
How it works
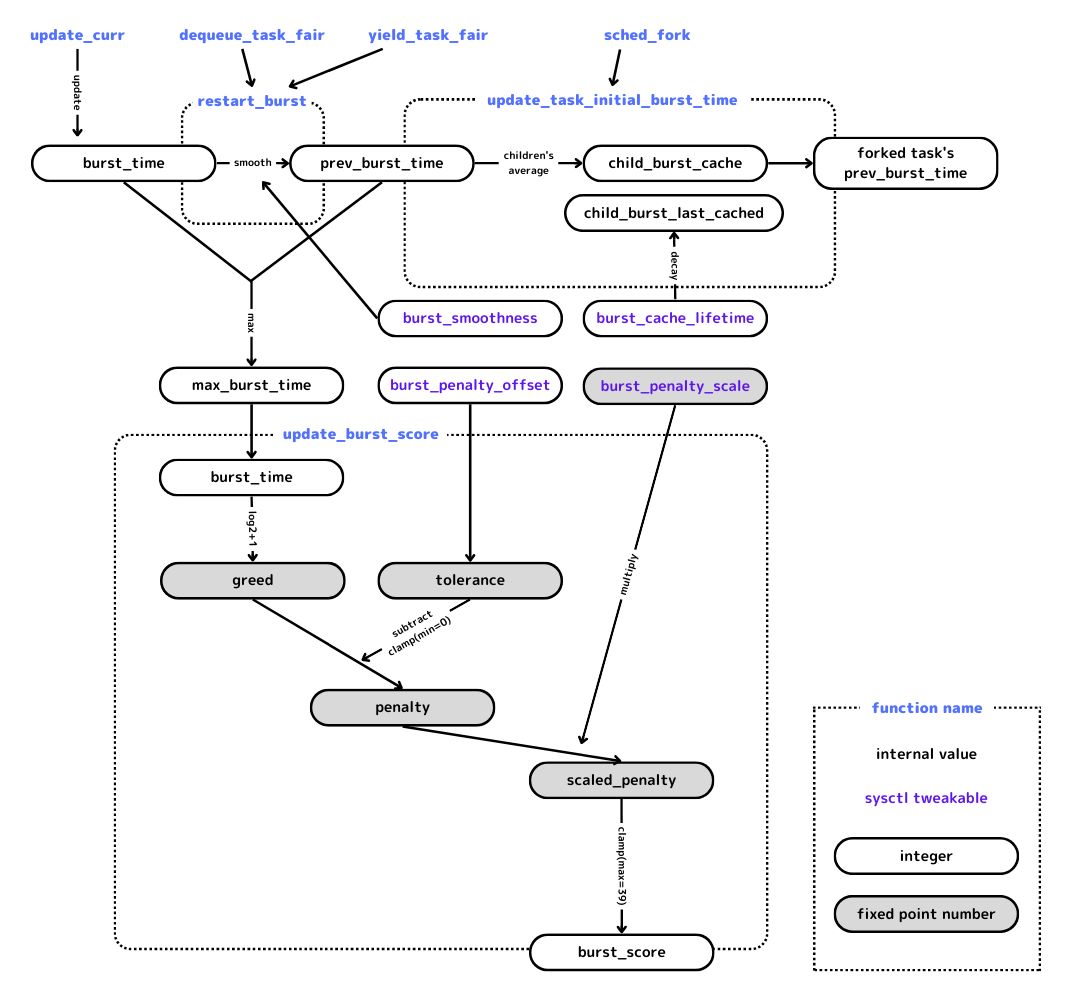
- The scheduler tracks each task's burst time, which is the amount of CPU time the task has consumed since it last yielded, slept, or waited for I/O.
- While a task is active, its burst score is continuously calculated by counting the bit count of its normalized burst time and adjusting it using pre-configured offset and coefficient.
- The burst score functions similarly to "niceness" and takes a value between 0-39. For each decrease in value by 1, the task can consume approximately 1.25x longer timeslice.
- This process acts as a radix conversion from binary logarithm to common logarithm, converting between two different magnitudes (nano-seconds-to-minutes timescale to about 0.01-100x scale) dimensionlessly.
- As a result, less "greedy" tasks are given more timeslice and wakeup preemption aggressiveness, while greedier tasks that yield their timeslice less frequently are weighted less.
- The burst score of newly-spawned processes is calculated in a unique way to prevent tasks like "make" from overwhelming interactive tasks by forking many CPU-hungry children.
- The final effect is an equilibrium between opposing greedy and weak tasks (usually CPU-bound batch tasks) and modest and strong tasks (usually I/O-bound interactive tasks), providing a more responsive user experience under the coexistence of various types of workloads.
Tunables
Example
$ sudo sysctl -w kernel.sched_bore=1
sched_bore (range: 0 - 1, default: 1)
1 Enables the BORE mechanism.
0 Disables the BORE mechanism.
sched_burst_cache_lifetime (range: 0 - 4294967295, default: 60000000)
How many nanoseconds to hold as cache the on-fork calculated average burst time of each task's child tasks.
Increasing this value results in less frequent re-calculation of average burst time, in barter of more coarse-grain (=low time resolution) on-fork burst time adjustments.
sched_burst_fork_atavistic (range: 0 - 3, default: 2)
0: Disables the inheritance of the average child burst time from ancestor processes.
1-3: Enables the inheritance of the average child burst time from ancestor processes using a topological hub/stub style hierarchy tree, rather than the traditional parent-to-child style.
When this feature is enabled, nodes with only one child process are ignored when finding and calculating ancestor/descendant processes for inheritance. Any number equal to or greater than 1 also represents the number of hub nodes (with a child process count of 2 or more) that update_child_burst_cache will recursively dig down for each direct child when traversing the process tree to calculate the average of descendant processes' max_burst_time.
Enabling this feature may improve system responsiveness in situations with massive process-forking, such as kernel builds.
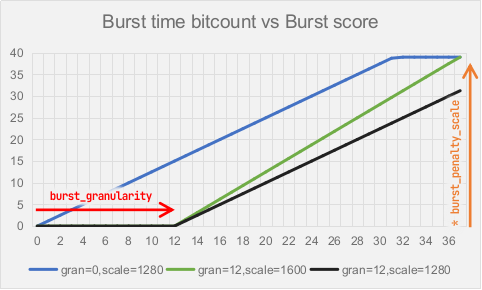
sched_burst_penalty_offset (range: 0 - 64, default: 22)
How many bits to reduce from burst time bit count when calculating burst score.
Increasing this value prevents tasks of shorter burst time from being too strong.
Increasing this value also lengthens the effective burst time range.
sched_burst_penalty_scale (range: 0 - 4095, default: 1280)
How strongly tasks are discriminated accordingly to their burst time ratio, scaled in 1/1024 of its precursor value.
Increasing this value makes burst score rapidly grow as the burst time grows. That means tasks that run longer without sleeping/yielding/iowaiting rapidly lose their power against those that run shorter.
Decreasing vice versa.
sched_burst_smoothness_long (range: 0 - 1, default: 1)
sched_burst_smoothness_short (range: 0 - 1, default: 0)
A task's actual burst score is the larger one of its latest calculated score or its "historical" score which inherits past score(s). This is done to smoothen the user experience under "burst spike" situations.
Every time burst score is updated (when the task is dequeued/yielded), its historical score is also updated by mixing burst_time / (2 ^ burst_smoothness) into prev_burst_time. but this mixing occurs only when prev_burst_time increases. burst_smoothness=0 means no smoothening.
sched_burst_exclude_kthreads (range: 0 - 1, default: 1)
1 BORE takes effect on non-kernel tasks.
0 BORE takes effect on non-kernel and kernel tasks.
sched_burst_parity_threshold (range: u8, default: 2)
The RUN_TO_PARITY sched feature flag is benefitial for throughput for slightly less responsiveness in trade-off, but it rapidly loses its advantage as task count in runqueue increases. Thus, instead of consistently take either behavior, an adaptive method is favorable.
When set to 0, BORE simply obeys RUN_TO_PARITY.
When set to greater than zero, RUN_TO_PARITY is adaptively disabled if there're more tasks than this value in a CFQ runqueue.
sched_deadline_boost_mask (range: u32, default: ENQUEUE_INITIAL | ENQUEUE_WAKEUP)
When a task is being enqueued with one of these flags, deadline is halved.
Special thanks
- Hamad Al Marri, the developer famous for his task schedulers Cachy, CacULE, Baby and TT. BORE has been massively inspired from his great works. He also helped me a lot in the development.
- Peter "ptr1337" Jung, the founder of CachyOS high-performance linux distribution, also being the admin of its development community. His continuous support, sharp analysis and dedicated tests and advice helped me shoot many problems.
- Ching-Chun "jserv" Huang from National Cheng Kung University of Taiwan, and Hui Chun "foxhoundsk" Feng from National Taiwan Ocean University, for detailed analysis and explanation of the scheduler in their excellent treatise.
- Piotr Górski a.k.a. "sir_lucjan" from the CachyOS community, for hosting BORE-powered CachyOS kernels for Fedora, as well as helping me shoot some bugs.
- dim-geo, for assisting me with optimization hints.
- Array, for helping me investigate a serious lockup bug and providing me usefultest reports.
- Mario Roy, for providing me good insights by various detailed test reports, hosting a BORE-powered, clearlinux-based optimized kernel, and also helping me integrating some early upstream patches for improvement, by curating them for me. He also helped me fix a bug that was causing massive slow-downs in combination with CGROUP v1.
- And many whom I haven't added here yet.
