Awesome
Incremental Learning in Semantic Segmentation from Image Labels
Fabio Cermelli, Dario Fontanel, Antonio Tavera, Marco Ciccone, Barbara Caputo -- CVPR 22 Paper Supp
Official PyTorch Implementation
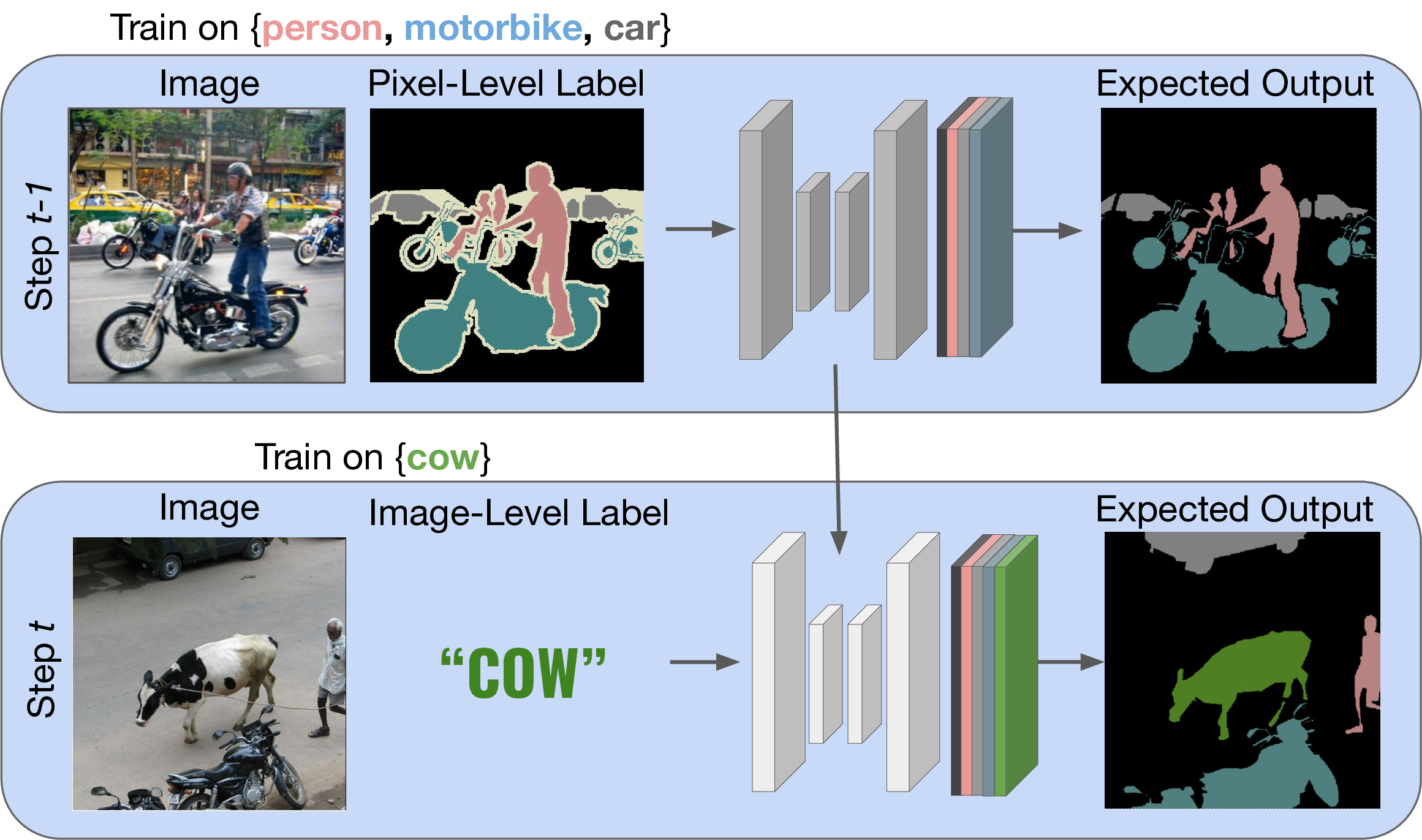
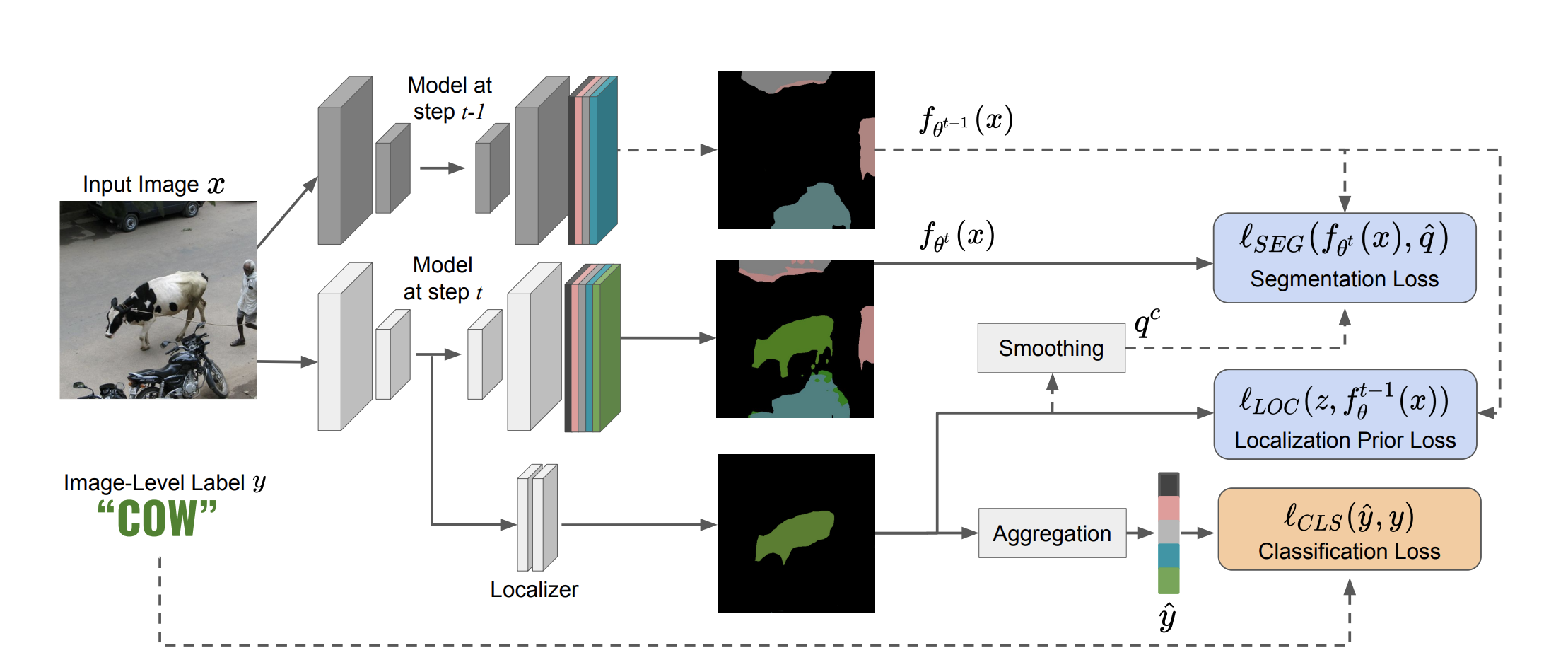
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.
How to run
Requirements
We have simple requirements: The main requirements are:
python > 3.1
pytorch > 1.6
If you want to install a custom environment for this code, you can run the following using conda:
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
conda install tensorboard
conda install jupyter
conda install matplotlib
conda install tqdm
conda install imageio
pip install inplace-abn # this should be done using CUDA compiler (same version as pytorch)
pip install wandb # to use the WandB logger
Datasets
In the benchmark there are two datasets: Pascal-VOC 2012 and COCO (object only). For the COCO dataset, we followed the COCO-stuff splits and annotations, that you can see here.
To download dataset, follow the scripts: data/download_voc.sh, data/download_coco.sh
To use the annotations of COCO-Stuff in our setting, you should preprocess it by running the provided script.
Please, remember to change the path in the script before launching it!
python data/coco/make_annotation.py
If your datasets are in a different folder, make a soft-link from the target dataset to the data folder. We expect the following tree:
data/voc/
SegmentationClassAug/
<Image-ID>.png
JPEGImages/
<Image-ID>.png
split/
... other files
data/coco/
annotations/
train2017/
<Image-ID>.png
val2017/
<Image-ID>.png
images/
train2017/
<Image-ID>.png
val2017/
<Image-ID>.png
... other files
:warning: Bee sure not to override the current voc directory of the repository.
We suggest to link the folders inside the voc directory.
Finally, to prepare the COCO-to-VOC setting we need to map the VOC labels into COCO. Do that by running
python data/make_cocovoc.py
ImageNet Pretrained Models
After setting the dataset, you download the models pretrained on ImageNet using InPlaceABN.
Download the ResNet-101 model (we only need it but you can also download other networks if you want to change it).
Then, put the pretrained model in the pretrained folder.
Run!
We provide different an example script to run the experiments (see run.sh, coco.sh).
In the following, we describe the basic parameter to run an experiment.
First, we assume that we have a command
exp='python -m torch.distributed.launch --nproc_per_node=<num GPUs> --master_port <PORT> run.py --num_workers <N_Workers>'`
that allow us to setup the distributed data parallel script.
The first to replicate us, is to obtain the model on the step 0 (base step, fully supervised). You can run:
exp --name Base --step 0 --lr 0.01 --bce --dataset <dataset> --task <task> --batch_size 24 --epochs 30 --val_interval 2 [--overlap]
where we use --bce to train the classifier with the binary cross-entropy. dataset can be voc or coco-voc. The task
are,
voc: (you can set overlap here)
15-5, 10-10
coco: (overlap is not used)
voc
After this, you can run the incremental steps using only image level labels (set the weakly parameter).
exp --name ours --step 1 --weakly --lr 0.001 --alpha 0.5 --step_ckpt <pretr> --loss_de 1 --lr_policy warmup --affinity \
--dataset <dataset> --task <task> --batch_size 24 --epochs 40 [--overlap]
where pretr should be the path to the pretrained model (usually checkpoints/step/<dataset>-<task>/<name>.pth).
Please, set --alpha 0.9 on the COCO dataset.
If you want to run the fully-supervised baselines, please refer to the MiB's code.
Qualitative Results
 From left to right: image, CAM, SEAM, Single-Stage, EPS, Ours, and finally the ground-truth.
From left to right: image, CAM, SEAM, Single-Stage, EPS, Ours, and finally the ground-truth.
Cite us!
Please, cite the following article when referring to this code/method.
@InProceedings{cermelli2022incremental,
title={Incremental Learning in Semantic Segmentation from Image Labels},
author={Fabio Cermelli, Dario Fontanel, Antonio Tavera, Marco Ciccone, Barbara Caputo},
booktitle={Proceedings of the IEEE/CVF Computer Vision and Patter Recognition Conference (CVPR)},
month={June},
year={2022}
}