Awesome
twitter-to-sqlite


![]()
![]()
Save data from Twitter to a SQLite database.
This tool currently uses Twitter API v1. You may be unable to use it if you do not have an API key for that version of the API.
<!-- toc -->- How to install
- Authentication
- Retrieving tweets by specific accounts
- Retrieve user profiles in bulk
- Retrieve tweets in bulk
- Retrieving Twitter followers
- Retrieving friends
- Retrieving favorited tweets
- Retrieving Twitter lists
- Retrieving Twitter list memberships
- Retrieving just follower and friend IDs
- Retrieving tweets from your home timeline
- Retrieving your mentions
- Providing input from a SQL query with --sql and --attach
- Running searches
- Capturing tweets in real-time with track and follow
- Importing data from your Twitter archive
- Design notes
How to install
$ pip install twitter-to-sqlite
Authentication
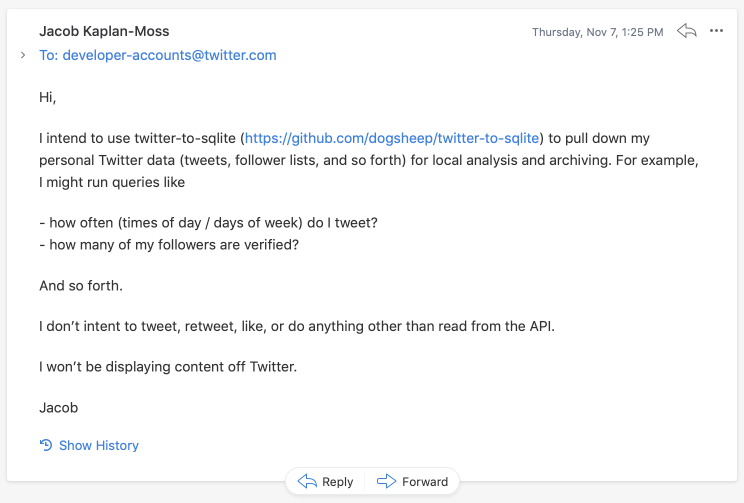
First, you will need to create a Twitter application at https://developer.twitter.com/en/apps. You may need to apply for a Twitter developer account - if so, you may find this example of an email application useful that has been approved in the past.
{kind=link}
Once you have created your application, navigate to the "Keys and tokens" page and make note of the following:
- Your API key
- Your API secret key
- Your access token
- Your access token secret
You will need to save all four of these values to a JSON file in order to use this tool.
You can create that JSON file by running the following command and pasting in the values at the prompts:
$ twitter-to-sqlite auth
Create an app here: https://developer.twitter.com/en/apps
Then navigate to 'Keys and tokens' and paste in the following:
API key: xxx
API secret key: xxx
Access token: xxx
Access token secret: xxx
This will create a file called auth.json in your current directory containing the required values. To save the file at a different path or filename, use the --auth=myauth.json option.
Retrieving tweets by specific accounts
The user-timeline command retrieves all of the tweets posted by the specified user accounts. It defaults to the account belonging to the authenticated user:
$ twitter-to-sqlite user-timeline twitter.db
Importing tweets [#####-------------------------------] 2799/17780 00:01:39
All of these commands assume that there is an auth.json file in the current directory. You can provide the path to your auth.json file using -a:
$ twitter-to-sqlite user-timeline twitter.db -a /path/to/auth.json
To load tweets for other users, pass their screen names as arguments:
$ twitter-to-sqlite user-timeline twitter.db cleopaws nichemuseums
Twitter's API only returns up to around 3,200 tweets for most user accounts, but you may find that it returns all available tweets for your own user account.
You can pass numeric Twitter user IDs instead of screen names using the --ids parameter.
You can use --since to retrieve every tweet since the last time you imported for that user, or --since_id=xxx to retrieve every tweet since a specific tweet ID.
This command also accepts --sql and --attach options, documented below.
Retrieve user profiles in bulk
If you have a list of Twitter screen names (or user IDs) you can bulk fetch their fully inflated Twitter profiles using the users-lookup command:
$ twitter-to-sqlite users-lookup users.db simonw cleopaws
You can pass user IDs instead using the --ids option:
$ twitter-to-sqlite users-lookup users.db 12497 3166449535 --ids
This command also accepts --sql and --attach options, documented below.
Retrieve tweets in bulk
If you have a list of tweet IDS you can bulk fetch them using the statuses-lookup command:
$ twitter-to-sqlite statuses-lookup tweets.db 1122154819815239680 1122154178493575169
The --sql and --attach options are supported.
Here's a recipe to retrieve any tweets that existing tweets are in-reply-to which have not yet been stored in your database:
$ twitter-to-sqlite statuses-lookup tweets.db \
--sql='
select in_reply_to_status_id
from tweets
where in_reply_to_status_id is not null' \
--skip-existing
The --skip-existing option means that tweets that have already been stored in the database will not be fetched again.
Retrieving Twitter followers
The followers command retrieves details of every follower of the specified accounts. You can use it to retrieve your own followers, or you can pass one or more screen names to pull the followers for other accounts.
The following command pulls your followers and saves them in a SQLite database file called twitter.db:
$ twitter-to-sqlite followers twitter.db
This command is extremely slow, because Twitter impose a rate limit of no more than one request per minute to this endpoint! If you are running it against an account with thousands of followers you should expect this to take several hours.
To retrieve followers for another account, use:
$ twitter-to-sqlite followers twitter.db cleopaws
This command also accepts the --ids, --sql and --attach options.
See Analyzing my Twitter followers with Datasette for the original inspiration for this command.
Retrieving friends
The friends command works like the followers command, but retrieves the specified (or currently authenticated) user's friends - defined as accounts that the user is following.
$ twitter-to-sqlite friends twitter.db
It takes the same options as the followers command.
Retrieving favorited tweets
The favorites command retrieves tweets that have been favorited by a specified user. Called without any extra arguments it retrieves tweets favorited by the currently authenticated user:
$ twitter-to-sqlite favorites faves.db
You can also use the --screen_name or --user_id arguments to retrieve favorite tweets for another user:
$ twitter-to-sqlite favorites faves-obama.db --screen_name=BarackObama
Use the --stop_after=xxx argument to retrieve only the most recent number of favorites, e.g. to get the authenticated user's 50 most recent favorites:
$ twitter-to-sqlite favorites faves.db --stop_after=50
Retrieving Twitter lists
The lists command retrieves all of the lists belonging to one or more users.
$ twitter-to-sqlite lists lists.db simonw dogsheep
This command also accepts the --sql and --attach and --ids options.
To additionally fetch the list of members for each list, use --members.
Retrieving Twitter list memberships
The list-members command can be used to retrieve details of one or more Twitter lists, including all of their members.
$ twitter-to-sqlite list-members members.db simonw/the-good-place
You can pass multiple screen_name/list_slug identifiers.
If you know the numeric IDs of the lists instead, you can use --ids:
$ twitter-to-sqlite list-members members.db 927913322841653248 --ids
Retrieving just follower and friend IDs
It's also possible to retrieve just the numeric Twitter IDs of the accounts that specific users are following ("friends" in Twitter's API terminology) or followed-by:
$ twitter-to-sqlite followers-ids members.db simonw cleopaws
This will populate the following table with followed_id/follower_id pairs for the two specified accounts, listing every account ID that is following either of those two accounts.
$ twitter-to-sqlite friends-ids members.db simonw cleopaws
This will do the same thing but pull the IDs that those accounts are following.
Both of these commands also support --sql and --attach as an alternative to passing screen names as direct command-line arguments. You can use --ids to process the inputs as user IDs rather than screen names.
The underlying Twitter APIs have a rate limit of 15 requests every 15 minutes - though they do return up to 5,000 IDs in each call. By default both of these subcommands will wait for 61 seconds between API calls in order to stay within the rate limit - you can adjust this behaviour down to just one second delay if you know you will not be making many calls using --sleep=1.
Retrieving tweets from your home timeline
The home-timeline command retrieves up to 800 tweets from the home timeline of the authenticated user - generally this means tweets from people you follow.
$ twitter-to-sqlite home-timeline twitter.db
Importing timeline [#################--------] 591/800 00:01:14
The tweets are stored in the tweets table, and a record is added to the timeline_tweets table noting that this tweet came in due to being spotted in the timeline of your user.
You can use --since to retrieve just tweets that have been posted since the last time this command was run, or --since_id=xxx to explicitly pass in a tweet ID to use as the last position.
You can then view your timeline in Datasette using the following URL:
/tweets/tweets?_where=id+in+(select+tweet+from+[timeline_tweets])&_sort_desc=id&_facet=user
This will filter your tweets table to just tweets that appear in your timeline, ordered by most recent first and use faceting to show you which users are responsible for the most tweets.
Retrieving your mentions
The mentions-timeline command works like home-timeline except it retrieves tweets that mention the authenticated user's account. It records the user account that was mentioned in a mentions_tweets table.
It supports --since and --since_id in the same was as home-timeline does.
Providing input from a SQL query with --sql and --attach
This option is available for some subcommands - run twitter-to-sqlite command-name --help to check.
You can provide Twitter screen names (or user IDs or tweet IDs) directly as command-line arguments, or you can provide those screen names or IDs by executing a SQL query.
For example: consider a SQLite database with an attendees table listing names and Twitter accounts - something like this:
| First | Last | |
|---|---|---|
| Simon | Willison | simonw |
| Avril | Lavigne | AvrilLavigne |
You can run the users-lookup command to pull the Twitter profile of every user listed in that database by loading the screen names using a --sql query:
$ twitter-to-sqlite users-lookup my.db --sql="select Twitter from attendees"
If your database table contains Twitter IDs, you can select those IDs and pass the --ids argument. For example, to fetch the profiles of users who have had their user IDs inserted into the following table using the twitter-to-sqlite friends-ids command:
$ twitter-to-sqlite users-lookup my.db --sql="select follower_id from following" --ids
Or to avoid re-fetching users that have already been fetched:
$ twitter-to-sqlite users-lookup my.db \
--sql="select followed_id from following where followed_id not in (
select id from users)" --ids
If your data lives in a separate database file you can attach it using --attach. For example, consider the attendees example above but the data lives in an attendees.db file, and you want to fetch the user profiles into a tweets.db file. You could do that like this:
$ twitter-to-sqlite users-lookup tweets.db \
--attach=attendees.db \
--sql="select Twitter from attendees.attendees"
The filename (without the extension) will be used as the database alias within SQLite. If you want a different alias for some reason you can specify that with a colon like this:
$ twitter-to-sqlite users-lookup tweets.db \
--attach=foo:attendees.db \
--sql="select Twitter from foo.attendees"
Running searches
The search command runs a search against the Twitter standard search API.
$ twitter-to-sqlite search tweets.db "dogsheep"
This will import up to around 320 tweets that match that search term into the tweets table. It will also create a record in the search_runs table recording that the search took place, and many-to-many records in the search_runs_tweets table recording which tweets were seen for that search at that time.
You can use the --since parameter to check for previous search runs with the same arguments and only retrieve tweets that were posted since the last retrieved matching tweet.
The following additional options for search are supported:
--geocode:latitude,longitude,radiuswhere radius is a number followed by mi or km--lang: ISO 639-1 language code e.g.enores--locale: Locale: onlyjais currently effective--result_type:mixed,recentorpopular. Defaults tomixed--count: Number of results per page, defaults to the maximum of 100--stop_after: Stop after this many results--since_id: Pull tweets since this Tweet ID. You probably want to use--sinceinstead of this.
Capturing tweets in real-time with track and follow
This functionality is experimental. Please file bug reports if you find any!
Twitter provides a real-time API which can be used to subscribe to tweets as they happen. twitter-to-sqlite can use this API to continually update a SQLite database with tweets matching certain keywords, or referencing specific users.
track
To track keywords, use the track command:
$ twitter-to-sqlite track tweets.db kakapo
This command will continue to run until you hit Ctrl+C. It will capture any tweets mentioning the keyword kakapo and store them in the tweets.db database file.
You can pass multiple keywords as a space separated list. This will capture tweets matching either of those keywords:
$ twitter-to-sqlite track tweets.db kakapo raccoon
You can enclose phrases in quotes to search for tweets matching both of those keywords:
$ twitter-to-sqlite track tweets.db 'trash panda'
See the Twitter track documentation for advanced tips on using this command.
Add the --verbose option to see matching tweets (in their verbose JSON form) displayed to the terminal as they are captured:
$ twitter-to-sqlite track tweets.db raccoon --verbose
follow
The follow command will capture all tweets that are relevant to one or more specific Twitter users.
$ twitter-to-sqlite follow tweets.db nytimes
This includes tweets by those users, tweets that reply to or quote those users and retweets by that user. See the Twitter follow documentation for full details.
The command accepts one or more screen names.
You can feed it numeric Twitter user IDs instead of screen names by using the --ids flag.
The command also supports the --sql and --attach options, and the --verbose option for displaying tweets as they are captured.
Here's how to start following tweets from every user ID currently represented as being followed in the following table (populated using the friends-ids command):
$ twitter-to-sqlite follow tweets.db \
--sql="select distinct followed_id from following" \
--ids
Importing data from your Twitter archive
You can request an archive of your Twitter data by following these instructions.
Twitter will send you a link to download a .zip file. You can import the contents of that file into a set of tables in a new database file called archive.db (each table beginning with the archive_ prefix) using the import command:
$ twitter-to-sqlite import archive.db ~/Downloads/twitter-2019-06-25-b31f2.zip
This command does not populate any of the regular tables, since Twitter's export data does not exactly match the schema returned by the Twitter API.
It will delete and recreate the corresponding archive_* tables every time you run it. If this is not what you want, run the command against a new SQLite database file name rather than running it against one that already exists.
If you have already decompressed your archive, you can run this against the directory that you decompressed it to:
$ twitter-to-sqlite import archive.db ~/Downloads/twitter-2019-06-25-b31f2/
You can also run it against one or more specific files within that folder. For example, to import just the follower.js and following.js files:
$ twitter-to-sqlite import archive.db \
~/Downloads/twitter-2019-06-25-b31f2/follower.js \
~/Downloads/twitter-2019-06-25-b31f2/following.js
You may want to use other commands to populate tables based on data from the archive. For example, to retrieve full API versions of each of the tweets you have favourited in your archive, you could run the following:
$ twitter-to-sqlite statuses-lookup archive.db \
--sql='select tweetId from archive_like' \
--skip-existing
If you want these imported tweets to then be reflected in the favorited_by table, you can do so by applying the following SQL query:
$ sqlite3 archive.db
SQLite version 3.22.0 2018-01-22 18:45:57
Enter ".help" for usage hints.
sqlite> INSERT OR IGNORE INTO favorited_by (tweet, user)
...> SELECT tweetId, 'YOUR_TWITTER_ID' FROM archive_like;
<Ctrl+D>
Replace YOUR_TWITTER_ID with your numeric Twitter ID. If you don't know that ID you can find it out by running the following:
$ twitter-to-sqlite fetch \
"https://api.twitter.com/1.1/account/verify_credentials.json" \
| grep '"id"' | head -n 1
Design notes
- Tweet IDs are stored as integers, to afford sorting by ID in a sensible way
- While we configure foreign key relationships between tables, we do not ask SQLite to enforce them. This is used by the
followingtable to allow thefollowers-idsandfriends-idscommands to populate it with user IDs even if the user accounts themselves are not yet present in theuserstable.