Awesome
Artificial Argument Corpus
Code for generating the synthetic argumentative texts in the paper "Critical Thinking for Language Models", accepted for IWCS 2021.
G Betz, C Voigt and K Richardson: Critical Thinking for Language Models, IWCS 2021
This repository doesn't contain the actual datasets used in the paper, which, however, can be downloaded here.
The trained models are released via at Hugging Face's model hub.
Pipeline
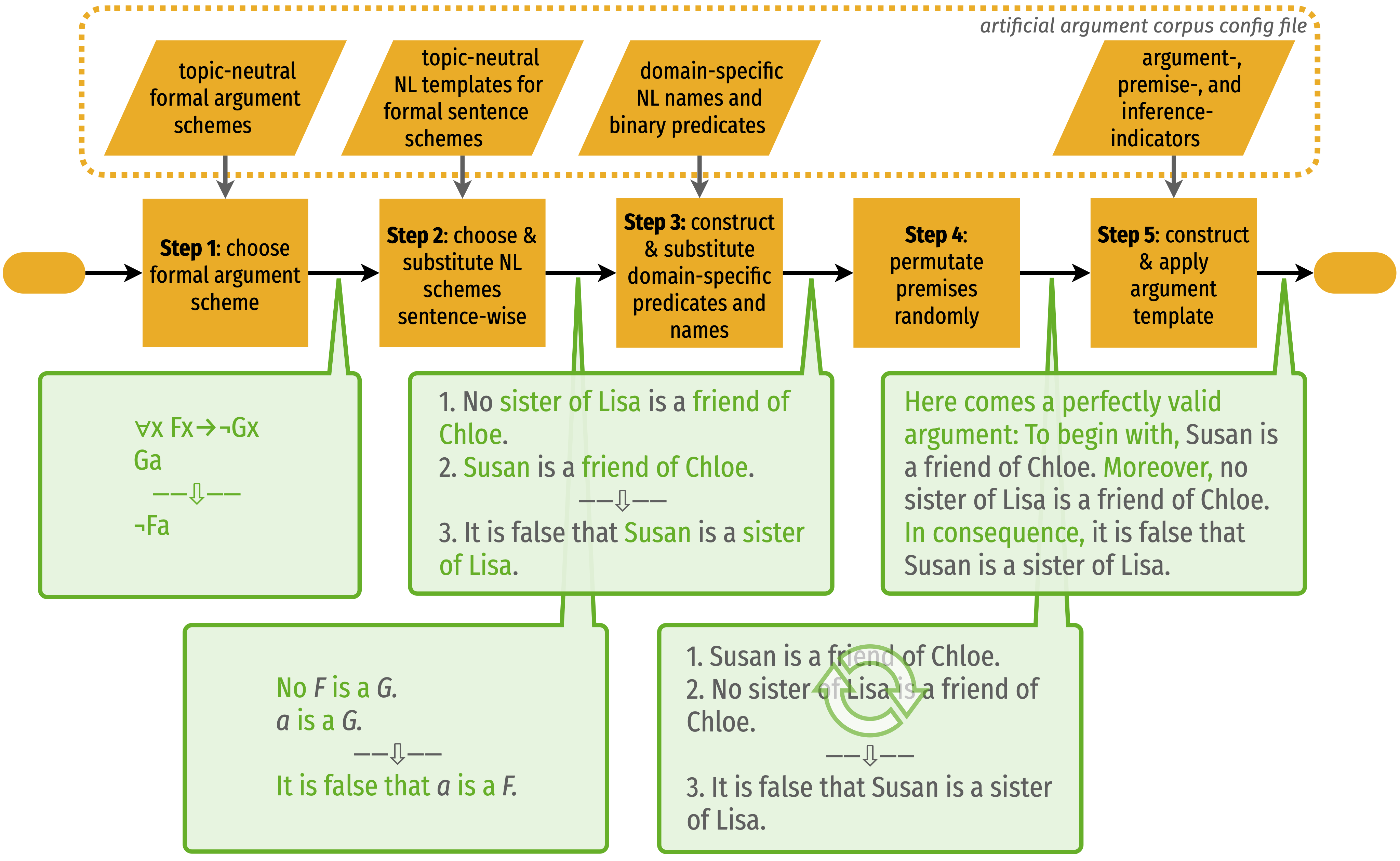
Step 1
In step 1, a formal argument scheme is chosen from the given config file (conf_syllogistic_corpus-01.json or conf_syllogistic_corpus-02.json), such as
{
"id": "mb1",
"base_scheme_group": "Modus barbara",
"scheme_variant": "negation_variant",
"scheme": [
["(x): ¬${A}x -> ${B}x", {"A": "${F}", "B": "${G}"}],
["¬${A}${a}", {"A": "${F}", "a": "${a}"}],
["${A}${a}", {"A": "${G}", "a": "${a}"}]
],
"predicate-placeholders": ["F","G"],
"entity-placeholders": ["a"]
}
Step 2
Next, each symbolic formula in the selected inference is replaced with a natural-language sentence scheme, e.g.
{
"scheme": [
"If someone is not a ${F}, then they are a ${G}.",
"${a} isn't a ${F}",
"${a} is a ${G}"
],
"predicate-placeholders": ["F","G"],
"entity-placeholders": ["a"]
}
while appropriate translations of symbolic formulas to natural-language sentence schemes are retrieved from the config file, e.g.:
{
"(x): ¬${A}x -> ${B}x" : [
"Whoever is not a ${A} is a ${B}. ",
"Nobody is neither a ${A} nor a ${B}. "
]
}
Step 3
In step 3, appropriate substitutions for the schemes' placeholders are retrieved from the config file, such as
{
"F": "supporter of FC Liverpool",
"G": "fan of Tottenham Hotspurs",
"a": "Mila"
}
Substitutes for predicate placeholders are actually generated from a binary predicate (x is a supporter of y) and an object term (FC Liverpool).
The config files (conf_syllogistic_corpus-01.json or conf_syllogistic_corpus-02.json) contain five (training and testing) respectively two (testing only) different domains: female_relatives, male_relatives, football_fans, consumers_personalcare and chemical_ingredients; dinos and philosophers.
Each domain used for training provides at least several hundreds of (complex) predicates.
Step 4
The premises are mixed.
Step 5
The argument (premise-conclusion list) is, finally, rendered as text paragraph by framing the argument and prepending premise and conclusion indicators to the corresponding sentences. These items are retrieved from the config file, too.
Requirements
create_trainfiles.py requires, as is, that spgutenberg and Reuters trc2 be available.