Awesome
FinQA
The FinQA dataset and code from EMNLP 2021 paper: FinQA: A Dataset of Numerical Reasoning over Financial Data https://arxiv.org/abs/2109.00122
Updates
05/15/2022 Refactor some code for easier testing the private test data, mostly in the finqa_utils.py files for both the retriever and the generator. In the config file for both retriever and the generator, you can set "mode" to "private" to test on the private data.
05/04/2022 Fixed the bug of table_row_to_text function, to be consistent with the table row format in the dataset. The original incorrect function causes label info leak and gives wrong results higher than actual ones for the retriever. The correct reuslts for FinQANet-Roberta-large should be 61.24 execution accuracy and 58.86 program accuracy. The results for all other baselines drop at the same magnitude. Please see the updated results in the leaderboards.
04/29/2022 Fixed the bug of inconsistent formatting issues for postive and negative examples in retriever/finqa_utils.py line 380.
Leaderboards
We have two test datasets, one with ground truth references as public test data, named "test.json" in the dataset folder; The other without the references as private test data, named "private_test.json" in the dataset folder.
Note that for submitting to both leaderboard, you should run end-to-end inferences of both the retriever and the generator. We do provide the gold retriever results, as well as the retriever results using our baseline model in the public test data, but this is only intended to help reproduce our results. The final evaluation of the FinQA challenge is based on the result on the private test data, which does not have any intermediate results or gold references.
The leaderboard for the public test data is Here.
The leaderboard for the private test data is Here.
Please follow the format description in section Evaluation Scripts to make submissions.
Requirements:
- pytorch 1.7.1
- huggingface transformers 4.4.2
Dataset
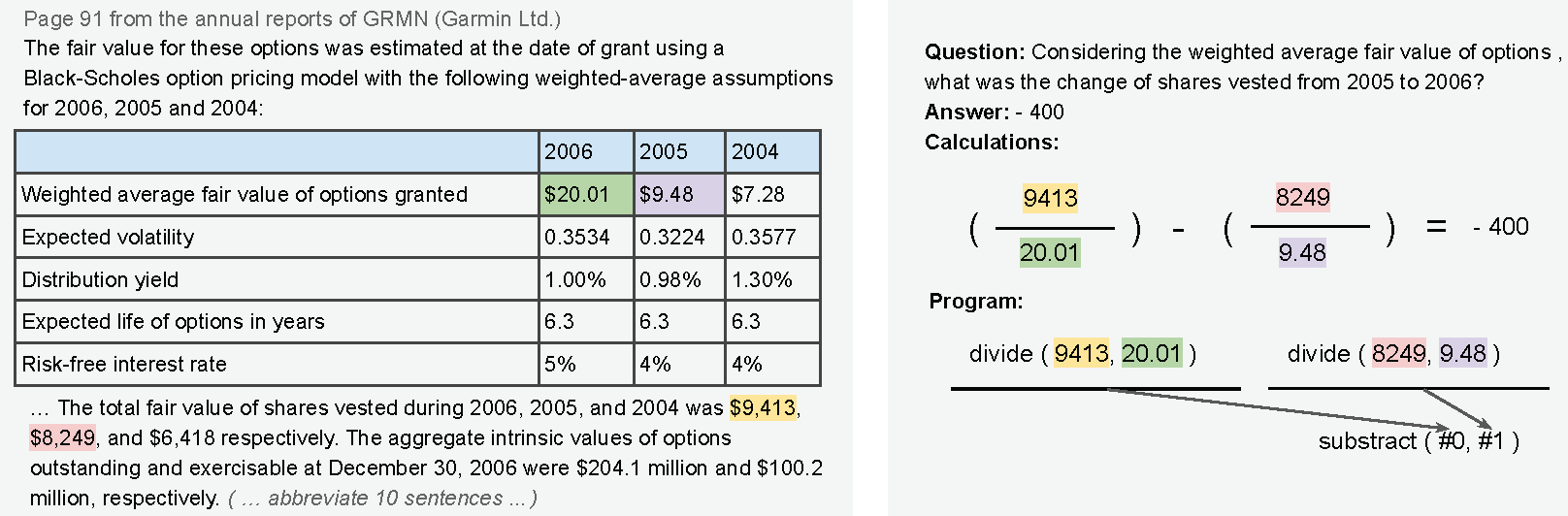
The dataset is stored as json files in folder "dataset", each entry has the following format:
"pre_text": the texts before the table;
"post_text": the text after the table;
"table": the table;
"id": unique example id. composed by the original report name plus example index for this report.
"qa": {
"question": the question;
"program": the reasoning program;
"gold_inds": the gold supporting facts;
"exe_ans": the gold execution result;
"program_re": the reasoning program in nested format;
}
In the private test data, we only have the "question" field, no reference provided.
Code
The retriever
Go to folder "retriever".
Train
To train the retriever, edit config.py to set your own project and data path. Set "model_save_name" to the name of the folder you want to save the checkpoints. You can also set other parameters here. Then run:
sh run.sh
You can observe the dev performance to select the checkpoint.
Inference
To run inference, edit config.py to change "mode" to "test", "saved_model_path" to the path of your selected checkpoint in the training, and "model_save_name" to the name of the folder to save the result files. Then run:
python Test.py
It will create an inference folder in the output directory and generate the files used for the program generator.
To train the program generator in the next step, we need to get the retriever inference results for all the train, dev, and test files. Edit config.py to set "test_file" as the path to the train file, dev file, and test file respectively, also set "model_save_name" correspondingly, and run Test.py to generate the results for all 3 of them.
The generator
Go to folder "generator".
Train
First we need to convert the results from the retriever to the files used for training. Edit the main entry in Convert.py to set the file paths to the retriever results path you specified in the previous step - for all 3 train, dev, and test files. Then run:
python Convert.py
to generate the train, dev, test files for the generator.
Edit other parameters in config.py, like your project path, data path, the saved model name, etc. To train the generator, run:
sh run.sh
You can observe the dev performance to select the checkpoint.
Inference
To run inference, edit config.py to change "mode" to "test", "saved_model_path" to the path of your selected checkpoint in the training, and "model_save_name" to the name of the folder to save the result files. Then run:
python Test.py
It will generate the result files in the created folder.
Evaluation Scripts
Go to folder "code/evaluate".
Prepare your prediction file into the following format, as a list of dictionaries, each dictionary contains two fields: the example id and the predicted program. The predicted program is a list of predicted program tokens with the 'EOF' as the last token. For example:
[
{
"id": "ETR/2016/page_23.pdf-2",
"predicted": [
"subtract(",
"5829",
"5735",
")",
"EOF"
]
},
{
"id": "INTC/2015/page_41.pdf-4",
"predicted": [
"divide(",
"8.1",
"56.0",
")",
"EOF"
]
},
...
]
You can also check the example prediction file 'example_predictions.json' in this folder for the format. Another file in this folder is the original test file 'test.json'.
To run evaluation, copy your prediction file here, and run with
python evaluate.py your_prediction_file test.json
Citation
If you find this project useful, please cite it using the following format
@article{chen2021finqa,
title={FinQA: A Dataset of Numerical Reasoning over Financial Data},
author={Chen, Zhiyu and Chen, Wenhu and Smiley, Charese and Shah, Sameena and Borova, Iana and Langdon, Dylan and Moussa, Reema and Beane, Matt and Huang, Ting-Hao and Routledge, Bryan and Wang, William Yang},
journal={Proceedings of EMNLP 2021},
year={2021}
}