Awesome
optillm
optillm is an OpenAI API compatible optimizing inference proxy which implements several state-of-the-art techniques that can improve the accuracy and performance of LLMs. The current focus is on implementing techniques that improve reasoning over coding, logical and mathematical queries. It is possible to beat the frontier models using these techniques across diverse tasks by doing additional compute at inference time.

![]()

Installation
Using pip
pip install optillm
optillm
2024-10-22 07:45:05,612 - INFO - Loaded plugin: privacy
2024-10-22 07:45:06,293 - INFO - Loaded plugin: memory
2024-10-22 07:45:06,293 - INFO - Starting server with approach: auto
Install from source
Clone the repository with git and use pip install to setup the dependencies.
git clone https://github.com/codelion/optillm.git
cd optillm
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
Set up the OPENAI_API_KEY environment variable (for OpenAI)
or the AZURE_OPENAI_API_KEY, AZURE_API_VERSION and AZURE_API_BASE environment variables (for Azure OpenAI)
or the AZURE_API_VERSION and AZURE_API_BASE environment variables and login using az login for Azure OpenAI with managed identity (see here).
You can then run the optillm proxy as follows.
python optillm.py
2024-09-06 07:57:14,191 - INFO - Starting server with approach: auto
2024-09-06 07:57:14,191 - INFO - Server configuration: {'approach': 'auto', 'mcts_simulations': 2, 'mcts_exploration': 0.2, 'mcts_depth': 1, 'best_of_n': 3, 'model': 'gpt-4o-mini', 'rstar_max_depth': 3, 'rstar_num_rollouts': 5, 'rstar_c': 1.4, 'base_url': ''}
* Serving Flask app 'optillm'
* Debug mode: off
2024-09-06 07:57:14,212 - INFO - WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:8000
* Running on http://192.168.10.48:8000
2024-09-06 07:57:14,212 - INFO - Press CTRL+C to quit
Usage
Once the proxy is running, you can use it as a drop in replacement for an OpenAI client by setting the base_url as http://localhost:8000/v1.
import os
from openai import OpenAI
OPENAI_KEY = os.environ.get("OPENAI_API_KEY")
OPENAI_BASE_URL = "http://localhost:8000/v1"
client = OpenAI(api_key=OPENAI_KEY, base_url=OPENAI_BASE_URL)
response = client.chat.completions.create(
model="moa-gpt-4o",
messages=[
{
"role": "user",
"content": "Write a Python program to build an RL model to recite text from any position that the user provides, using only numpy."
}
],
temperature=0.2
)
print(response)
The code above applies to both OpenAI and Azure OpenAI, just remember to populate the OPENAI_API_KEY env variable with the proper key.
There are multiple ways to control the optimization techniques, they are applied in the follow order of preference:
- You can control the technique you use for optimization by prepending the slug to the model name
{slug}-model-name. E.g. in the above code we are usingmoaor mixture of agents as the optimization approach. In the proxy logs you will see the following showing themoais been used with the base model asgpt-4o-mini.
2024-09-06 08:35:32,597 - INFO - Using approach moa, with gpt-4o-mini
2024-09-06 08:35:35,358 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:39,553 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,795 - INFO - HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2024-09-06 08:35:44,797 - INFO - 127.0.0.1 - - [06/Sep/2024 08:35:44] "POST /v1/chat/completions HTTP/1.1" 200 -
- Or, you can pass the slug in the
optillm_approachfield in theextra_body.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "" }],
temperature=0.2,
extra_body={"optillm_approach": "bon|moa|mcts"}
)
- Or, you can just mention the approach in either your
systemoruserprompt, within<optillm_approach> </optillm_approach>tags.
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{ "role": "user","content": "<optillm_approach>re2</optillm_approach> How many r's are there in strawberry?" }],
temperature=0.2
)
[!TIP] You can also combine different techniques either by using symbols
&and|. When you use&the techniques are processed in the order from left to right in a pipeline with response from previous stage used as request to the next. While, with|we run all the requests in parallel and generate multiple responses that are returned as a list.
Please note that the convention described above works only when the optillm server has been started with inference approach set to auto. Otherwise, the model attribute in the client request must be set with the model name only.
We now suport all LLM providers (by wrapping around the LiteLLM sdk). E.g. you can use the Gemini Flash model with moa by setting passing the api key in the environment variable os.environ['GEMINI_API_KEY'] and then calling the model moa-gemini/gemini-1.5-flash-002. In the output you will then see that LiteLLM is being used to call the base model.
9:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,011 - INFO -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
2024-09-29 19:43:21,481 - INFO - HTTP Request: POST https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-002:generateContent?key=[redacted] "HTTP/1.1 200 OK"
19:43:21 - LiteLLM:INFO: utils.py:988 - Wrapper: Completed Call, calling success_handler
2024-09-29 19:43:21,483 - INFO - Wrapper: Completed Call, calling success_handler
19:43:21 - LiteLLM:INFO: utils.py:2952 -
LiteLLM completion() model= gemini-1.5-flash-002; provider = gemini
[!TIP] optillm is a transparent proxy and will work with any LLM API or provider that has an OpenAI API compatible chat completions endpoint, and in turn, optillm also exposes the same OpenAI API compatible chat completions endpoint. This should allow you to integrate it into any existing tools or frameworks easily. If the LLM you want to use doesn't have an OpenAI API compatible endpoint (like Google or Anthropic) you can use LiteLLM proxy server that supports most LLMs.
The following sequence diagram illustrates how the request and responses go through optillm.
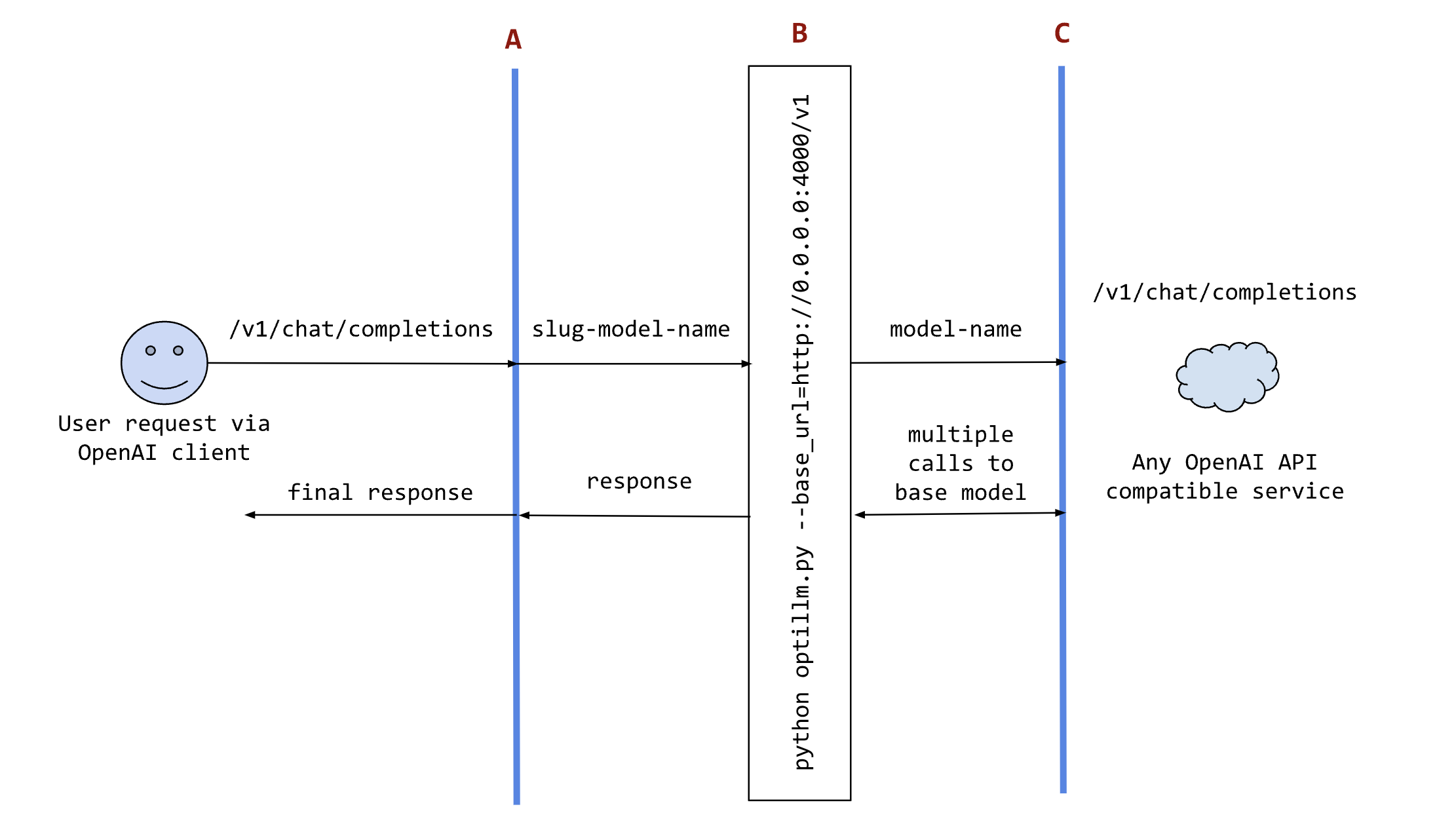
In the diagram:
Ais an existing tool (like oobabooga), framework (like patchwork) or your own code where you want to use the results from optillm. You can use it directly using any OpenAI client sdk.Bis the optillm service (running directly or in a docker container) that will send requests to thebase_url.Cis any service providing an OpenAI API compatible chat completions endpoint.
Local inference server
We support loading any HuggingFace model or LoRA directly in optillm. To use the built-in inference server set the OPTILLM_API_KEY to any value (e.g. export OPTILLM_API_KEY="optillm")
and then use the same in your OpenAI client. You can pass any HuggingFace model in model field. If it is a private model make sure you set the HF_TOKEN environment variable
with your HuggingFace key. We also support adding any number of LoRAs on top of the model by using the + separator.
E.g. The following code loads the base model meta-llama/Llama-3.2-1B-Instruct and then adds two LoRAs on top - patched-codes/Llama-3.2-1B-FixVulns and patched-codes/Llama-3.2-1B-FastApply.
You can specify which LoRA to use using the active_adapter param in extra_args field of OpenAI SDK client. By default we will load the last specified adapter.
OPENAI_BASE_URL = "http://localhost:8000/v1"
OPENAI_KEY = "optillm"
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct+patched-codes/Llama-3.2-1B-FastApply+patched-codes/Llama-3.2-1B-FixVulns",
messages=messages,
temperature=0.2,
logprobs = True,
top_logprobs = 3,
extra_body={"active_adapter": "patched-codes/Llama-3.2-1B-FastApply"},
)
You can also use the alternate decoding techniques like cot_decoding and entropy_decoding directly with the local inference server.
response = client.chat.completions.create(
model="meta-llama/Llama-3.2-1B-Instruct",
messages=messages,
temperature=0.2,
extra_body={
"decoding": "cot_decoding", # or "entropy_decoding"
# CoT specific params
"k": 10,
"aggregate_paths": True,
# OR Entropy specific params
"top_k": 27,
"min_p": 0.03,
}
)
Starting the optillm proxy with an external server (e.g. llama.cpp or ollama)
- Set the
OPENAI_API_KEYenv variable to a placeholder value- e.g.
export OPENAI_API_KEY="sk-no-key"
- e.g.
- Run
./llama-server -c 4096 -m path_to_modelto start the server with the specified model and a context length of 4096 tokens - Run
python3 optillm.py --base_url base_urlto start the proxy- e.g. for llama.cpp, run
python3 optillm.py --base_url http://localhost:8080/v1
- e.g. for llama.cpp, run
[!WARNING] Note that the Anthropic API, llama-server (and ollama) currently does not support sampling multiple responses from a model, which limits the available approaches to the following:
cot_reflection,leap,plansearch,rstar,rto,self_consistency,re2, andz3. For models on HuggingFace, you can use the built-in local inference server as it supports multiple responses.
Implemented techniques
| Approach | Slug | Description |
|---|---|---|
| CoT with Reflection | cot_reflection | Implements chain-of-thought reasoning with <thinking>, <reflection> and <output> sections |
| PlanSearch | plansearch | Implements a search algorithm over candidate plans for solving a problem in natural language |
| ReRead | re2 | Implements rereading to improve reasoning by processing queries twice |
| Self-Consistency | self_consistency | Implements an advanced self-consistency method |
| Z3 Solver | z3 | Utilizes the Z3 theorem prover for logical reasoning |
| R* Algorithm | rstar | Implements the R* algorithm for problem-solving |
| LEAP | leap | Learns task-specific principles from few shot examples |
| Round Trip Optimization | rto | Optimizes responses through a round-trip process |
| Best of N Sampling | bon | Generates multiple responses and selects the best one |
| Mixture of Agents | moa | Combines responses from multiple critiques |
| Monte Carlo Tree Search | mcts | Uses MCTS for decision-making in chat responses |
| PV Game | pvg | Applies a prover-verifier game approach at inference time |
| CoT Decoding | N/A for proxy | Implements chain-of-thought decoding to elicit reasoning without explicit prompting |
| Entropy Decoding | N/A for proxy | Implements adaptive sampling based on the uncertainty of tokens during generation |
Implemented plugins
| Plugin | Slug | Description |
|---|---|---|
| Router | router | Uses the optillm-bert-uncased model to route requests to different approaches based on the user prompt |
| Chain-of-Code | coc | Implements a chain of code approach that combines CoT with code execution and LLM based code simulation |
| Memory | memory | Implements a short term memory layer, enables you to use unbounded context length with any LLM |
| Privacy | privacy | Anonymize PII data in request and deanonymize it back to original value in response |
| Read URLs | readurls | Reads all URLs found in the request, fetches the content at the URL and adds it to the context |
| Execute Code | executecode | Enables use of code interpreter to execute python code in requests and LLM generated responses |
Available parameters
optillm supports various command-line arguments and environment variables for configuration.
| Parameter | Description | Default Value |
|---|---|---|
--approach | Inference approach to use | "auto" |
--simulations | Number of MCTS simulations | 2 |
--exploration | Exploration weight for MCTS | 0.2 |
--depth | Simulation depth for MCTS | 1 |
--best-of-n | Number of samples for best_of_n approach | 3 |
--model | OpenAI model to use | "gpt-4o-mini" |
--base-url | Base URL for OpenAI compatible endpoint | "" |
--rstar-max-depth | Maximum depth for rStar algorithm | 3 |
--rstar-num-rollouts | Number of rollouts for rStar algorithm | 5 |
--rstar-c | Exploration constant for rStar algorithm | 1.4 |
--n | Number of final responses to be returned | 1 |
--return-full-response | Return the full response including the CoT with <thinking> tags | False |
--port | Specify the port to run the proxy | 8000 |
--optillm-api-key | Optional API key for client authentication to optillm | "" |
When using Docker, these can be set as environment variables prefixed with OPTILLM_.
Running with Docker
optillm can optionally be built and run using Docker and the provided Dockerfile.
Using Docker Compose
-
Make sure you have Docker and Docker Compose installed on your system.
-
Either update the environment variables in the docker-compose.yaml file or create a
.envfile in the project root directory and add any environment variables you want to set. For example, to set the OpenAI API key, add the following line to the.envfile:OPENAI_API_KEY=your_openai_api_key_here -
Run the following command to start optillm:
docker compose up -dThis will build the Docker image if it doesn't exist and start the optillm service.
-
optillm will be available at
http://localhost:8000.
When using Docker, you can set these parameters as environment variables. For example, to set the approach and model, you would use:
OPTILLM_APPROACH=mcts
OPTILLM_MODEL=gpt-4
To secure the optillm proxy with an API key, set the OPTILLM_API_KEY environment variable:
OPTILLM_API_KEY=your_secret_api_key
When the API key is set, clients must include it in their requests using the Authorization header:
Authorization: Bearer your_secret_api_key
SOTA results on benchmarks with optillm
coc-claude-3-5-sonnet-20241022 on AIME 2024 pass@1 (Nov 2024)
| Model | Score |
|---|---|
| o1-mini | 56.67 |
| coc-claude-3-5-sonnet-20241022 | 46.67 |
| coc-gemini/gemini-exp-1121 | 46.67 |
| o1-preview | 40.00 |
| gemini-exp-1114 | 36.67 |
| claude-3-5-sonnet-20241022 | 20.00 |
| gemini-1.5-pro-002 | 20.00 |
| gemini-1.5-flash-002 | 16.67 |
readurls&memory-gpt-4o-mini on Google FRAMES Benchmark (Oct 2024)
| Model | Accuracy |
|---|---|
| readurls&memory-gpt-4o-mini | 61.29 |
| gpt-4o-mini | 50.61 |
| readurls&memory-Gemma2-9b | 30.1 |
| Gemma2-9b | 5.1 |
| Gemma2-27b | 30.8 |
| Gemini Flash 1.5 | 66.5 |
| Gemini Pro 1.5 | 72.9 |
plansearch-gpt-4o-mini on LiveCodeBench (Sep 2024)
| Model | pass@1 | pass@5 | pass@10 |
|---|---|---|---|
| plansearch-gpt-4o-mini | 44.03 | 59.31 | 63.5 |
| gpt-4o-mini | 43.9 | 50.61 | 53.25 |
| claude-3.5-sonnet | 51.3 | ||
| gpt-4o-2024-05-13 | 45.2 | ||
| gpt-4-turbo-2024-04-09 | 44.2 |
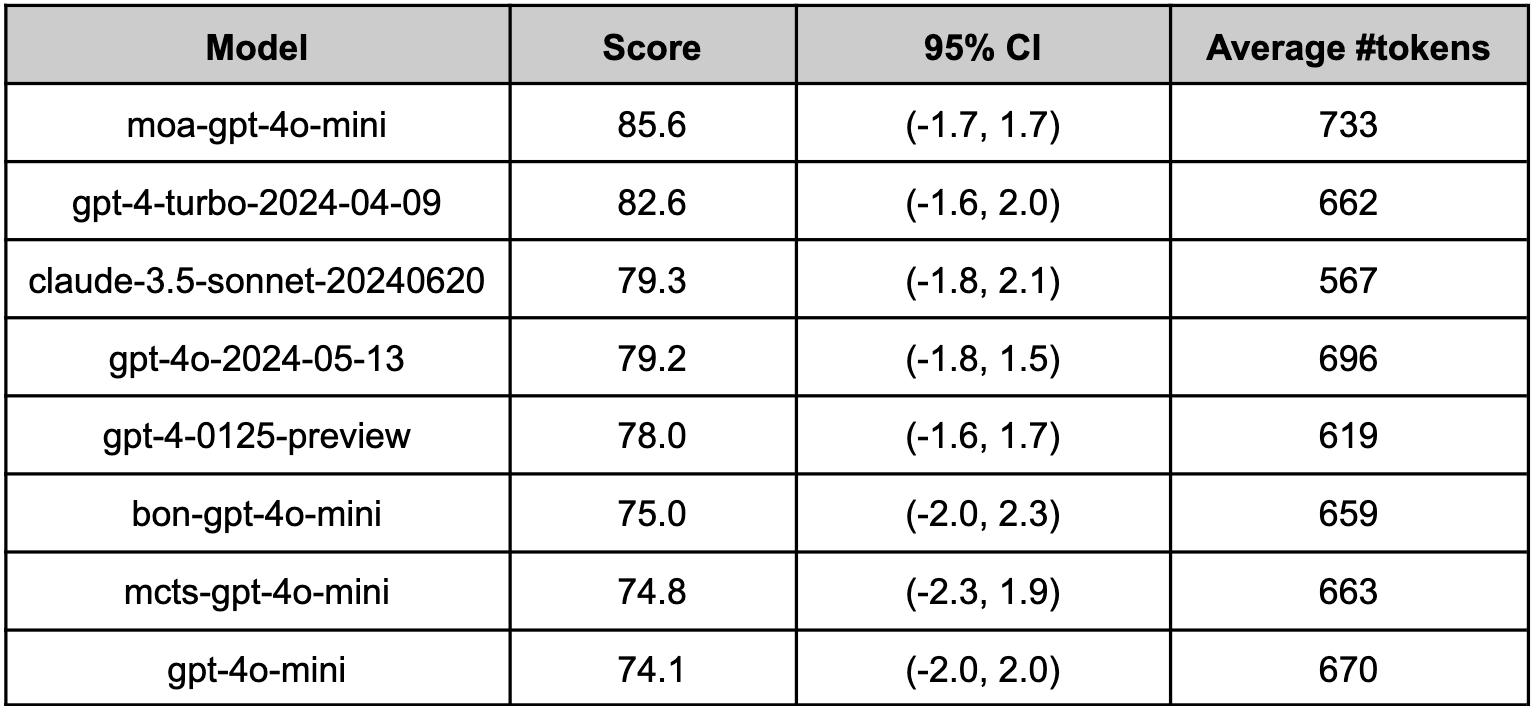
moa-gpt-4o-mini on Arena-Hard-Auto (Aug 2024)
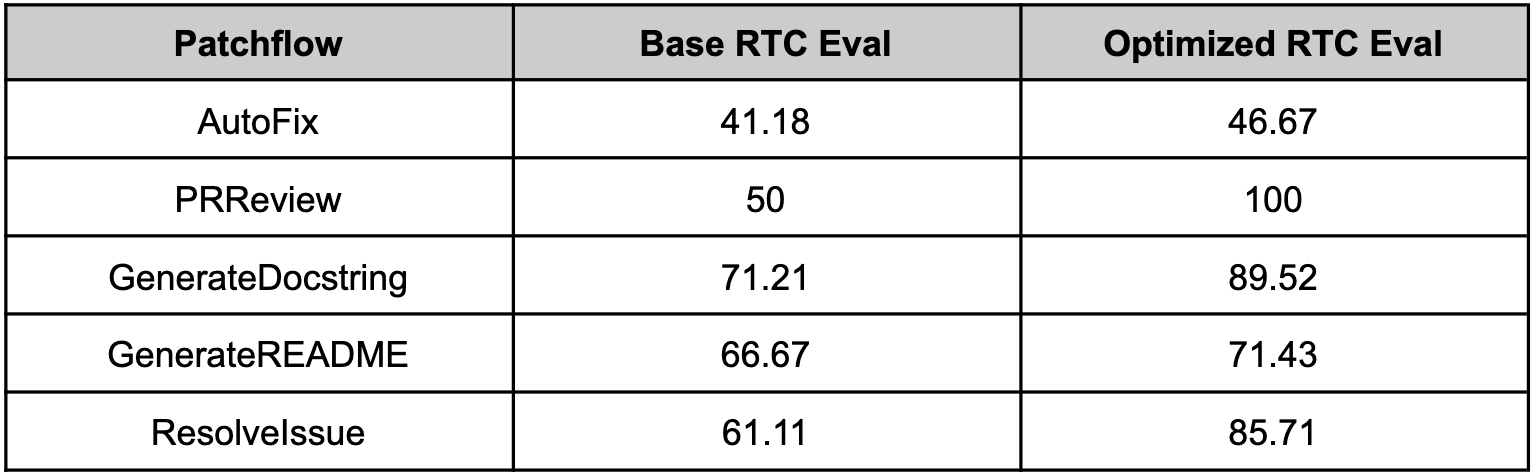
optillm with Patchwork (July 2024)
Since optillm is a drop-in replacement for OpenAI API you can easily integrate it with existing tools and frameworks using the OpenAI client. We used optillm with patchwork which is an open-source framework that automates development gruntwork like PR reviews, bug fixing, security patching using workflows called patchflows. We saw huge performance gains across all the supported patchflows as shown below when using the mixture of agents approach (moa).
References
- Chain of Code: Reasoning with a Language Model-Augmented Code Emulator - Implementation
- Entropy Based Sampling and Parallel CoT Decoding - Implementation
- Fact, Fetch, and Reason: A Unified Evaluation of Retrieval-Augmented Generation - Evaluation script
- Writing in the Margins: Better Inference Pattern for Long Context Retrieval - Inspired the implementation of the memory plugin
- Chain-of-Thought Reasoning Without Prompting - Implementation
- Re-Reading Improves Reasoning in Large Language Models - Implementation
- In-Context Principle Learning from Mistakes - Implementation
- Planning In Natural Language Improves LLM Search For Code Generation - Implementation
- Self-Consistency Improves Chain of Thought Reasoning in Language Models - Implementation
- Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers - Implementation
- Mixture-of-Agents Enhances Large Language Model Capabilities - Inspired the implementation of moa
- Prover-Verifier Games improve legibility of LLM outputs - Implementation
- Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning - Inspired the implementation of mcts
- Unsupervised Evaluation of Code LLMs with Round-Trip Correctness - Inspired the implementation of rto
- Patched MOA: optimizing inference for diverse software development tasks - Implementation
- Patched RTC: evaluating LLMs for diverse software development tasks - Implementation