Awesome
AraVec 3.0
Advancements in neural networks have led to developments in fields like computer vision, speech recognition and natural language processing (NLP). One of the most influential recent developments in NLP is the use of word embeddings, where words are represented as vectors in a continuous space, capturing many syntactic and semantic relations among them.
AraVec is a pre-trained distributed word representation (word embedding) open source project which aims to provide the Arabic NLP research community with free to use and powerful word embedding models. The first version of AraVec provides six different word embedding models built on top of three different Arabic content domains; Tweets and Wikipedia This paper describes the resources used for building the models, the employed data cleaning techniques, the carried out preprocessing step, as well as the details of the employed word embedding creation techniques.
The third version of AraVec provides 16 different word embedding models built on top of two different Arabic content domains; Tweets and Wikipedia Arabic articles. The major difference between this version and the previous ones, is that the we produced two different types of models, unigrams and n-grams models. We utilized set of statistical techniques to genrate the most common used n-grams of each data domain.
- Twitter tweets
- Wikipedia Arabic articles
By total tokens of more than 1,169,075,128 tokens.
Take a look on how ngrams models are represented:

Please view the results page for more queries.
Citation
Abu Bakr Soliman, Kareem Eisa, and Samhaa R. El-Beltagy, “AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP”, in proceedings of the 3rd International Conference on Arabic Computational Linguistics (ACLing 2017), Dubai, UAE, 2017.
Read the Full-Text Paper
How To Use
These models were built using gensim Python library. Here's a simple code for loading and using one of the models by following these steps:
- Install
gensim>= 3.4 andnltk>= 3.2 using eitherpiporconda
pip install gensim nltk
conda install gensim nltk
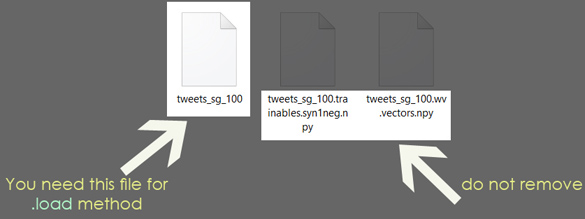
- extract the compressed model files to a directory [ e.g.
Twittert-CBOW] - keep the .npy files. You are gonna to load the file with no extension, like what you'll see in the following code.
- run this python code to load and use the model
How to integrate AraVec with Spacy.io
Code Samples
# -*- coding: utf8 -*-
import gensim
import re
import numpy as np
from nltk import ngrams
from utilities import * # import utilities.py module
# ============================
# ====== N-Grams Models ======
t_model = gensim.models.Word2Vec.load('models/full_grams_cbow_100_twitter.mdl')
# python 3.X
token = clean_str(u'ابو تريكه').replace(" ", "_")
# python 2.7
# token = clean_str(u'ابو تريكه'.decode('utf8', errors='ignore')).replace(" ", "_")
if token in t_model.wv:
most_similar = t_model.wv.most_similar( token, topn=10 )
for term, score in most_similar:
term = clean_str(term).replace(" ", "_")
if term != token:
print(term, score)
# تريكه 0.752911388874054
# حسام_غالي 0.7516342401504517
# وائل_جمعه 0.7244222164154053
# وليد_سليمان 0.7177559733390808
# ...
# =========================================
# == Get the most similar tokens to a compound query
# most similar to
# عمرو دياب + الخليج - مصر
pos_tokens=[ clean_str(t.strip()).replace(" ", "_") for t in ['عمرو دياب', 'الخليج'] if t.strip() != ""]
neg_tokens=[ clean_str(t.strip()).replace(" ", "_") for t in ['مصر'] if t.strip() != ""]
vec = calc_vec(pos_tokens=pos_tokens, neg_tokens=neg_tokens, n_model=t_model, dim=t_model.vector_size)
most_sims = t_model.wv.similar_by_vector(vec, topn=10)
for term, score in most_sims:
if term not in pos_tokens+neg_tokens:
print(term, score)
# راشد_الماجد 0.7094649076461792
# ماجد_المهندس 0.6979793906211853
# عبدالله_رويشد 0.6942606568336487
# ...
# ====================
# ====================
# ==============================
# ====== Uni-Grams Models ======
t_model = gensim.models.Word2Vec.load('models/full_uni_cbow_100_twitter.mdl')
# python 3.X
token = clean_str(u'تونس')
# python 2.7
# token = clean_str('تونس'.decode('utf8', errors='ignore'))
most_similar = t_model.wv.most_similar( token, topn=10 )
for term, score in most_similar:
print(term, score)
# ليبيا 0.8864325284957886
# الجزائر 0.8783721327781677
# السودان 0.8573237061500549
# مصر 0.8277812600135803
# ...
# get a word vector
word_vector = t_model.wv[ token ]
Download
N-Grams Models
to take a look on what we can retieve from the n-grams models using some most similar queries. Please view the results page
N-Grams Models
| Model | Docs No. | Vocabularies No. | Vec-Size | Download |
|---|---|---|---|---|
| Twitter-CBOW | 66,900,000 | 1,476,715 | 300 | Download |
| Twitter-CBOW | 66,900,000 | 1,476,715 | 100 | Download |
| Twitter-SkipGram | 66,900,000 | 1,476,715 | 300 | Download |
| Twitter-SkipGram | 66,900,000 | 1,476,715 | 100 | Download |
| Wikipedia-CBOW | 1,800,000 | 662,109 | 300 | Download |
| Wikipedia-CBOW | 1,800,000 | 662,109 | 100 | Download |
| Wikipedia-SkipGram | 1,800,000 | 662,109 | 300 | Download |
| Wikipedia-SkipGram | 1,800,000 | 662,109 | 100 | Download |
Unigrams Models
| Model | Docs No. | Vocabularies No. | Vec-Size | Download |
|---|---|---|---|---|
| Twitter-CBOW | 66,900,000 | 1,259,756 | 300 | Download |
| Twitter-CBOW | 66,900,000 | 1,259,756 | 100 | Download |
| Twitter-SkipGram | 66,900,000 | 1,259,756 | 300 | Download |
| Twitter-SkipGram | 66,900,000 | 1,259,756 | 100 | Download |
| Wikipedia-CBOW | 1,800,000 | 320,636 | 300 | Download |
| Wikipedia-CBOW | 1,800,000 | 320,636 | 100 | Download |
| Wikipedia-SkipGram | 1,800,000 | 320,636 | 300 | Download |
| Wikipedia-SkipGram | 1,800,000 | 320,636 | 100 | Download |
Citation
Abu Bakr Soliman, Kareem Eisa, and Samhaa R. El-Beltagy, “AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP”, in proceedings of the 3rd International Conference on Arabic Computational Linguistics (ACLing 2017), Dubai, UAE, 2017.