Awesome
![]()
SARosPerceptionKitti
ROS package for the Perception (Sensor Processing, Detection, Tracking and Evaluation) of the KITTI Vision Benchmark
Demo
<p align="center"> <img src="./videos/semantic.gif"> </p> <p align="center"> <img src="./videos/rviz.gif"> </p>Setup
Sticking to this folder structure is highly recommended:
~ # Home directory
├── catkin_ws # Catkin workspace
│ ├── src # Source folder
│ └── SARosPerceptionKitti # Repo
├── kitti_data # Dataset
│ ├── 0012 # Demo scenario 0012
│ │ └── synchronized_data.bag # Synchronized ROSbag file
- Install ROS and create a catkin workspace in your home directory:
mkdir -p ~/catkin_ws/src
- Clone this repository into the catkin workspace's source folder (src) and build it:
cd ~/catkin_ws/src
git clone https://github.com/appinho/SARosPerceptionKitti.git
cd ~/catkin_ws
catkin_make
source devel/setup.bash
- Download a preprocessed scenario and unzip it into a separate
kitti_datadirectory, also stored under your home directory:
mkdir ~/kitti_data && cd ~/kitti_data/
mv ~/Downloads/0012.zip .
unzip 0012.zip
rm 0012.zip
Usage
- Launch one of the following ROS nodes to perform and visualize the pipeline (Sensor Processing -> Object Detection -> Object Tracking) step-by-step:
source devel/setup.bash
roslaunch sensor_processing sensor_processing.launch home_dir:=/home/YOUR_USERNAME
roslaunch detection detection.launch home_dir:=/home/YOUR_USERNAME
roslaunch tracking tracking.launch home_dir:=/home/YOUR_USERNAME
- Default parameters:
- scenario:=0012
- speed:=0.2
- delay:=3
Without assigning any of the abovementioned parameters the demo scenario 0012 is replayed at 20% of its speed with a 3 second delay so RViz has enough time to boot up.
- Write the results to file and evaluate them:
roslaunch evaluation evaluation.launch home_dir:=/home/YOUR_USERNAME
cd ~/catkin_ws/src/SARosPerceptionKitti/benchmark/python
python evaluate_tracking.py
Results for demo scenario 0012
| Class | MOTA | MOTP | MOTAL | MODA | MODP |
|---|---|---|---|---|---|
| Car | 0.881119 | 0.633595 | 0.881119 | 0.881119 | 0.642273 |
| Pedestrian | 0.546875 | 0.677919 | 0.546875 | 0.546875 | 0.836921 |
Contact
If you have any questions, things you would love to add or ideas how to actualize the points in the Area of Improvements, send me an email at simonappel62@gmail.com ! More than interested to collaborate and hear any kind of feedback.
<!-- ### DIY: Data generation 0000 -> 0005 0001 -> 0009 0002 -> 0011 0003 -> 0013 0004 -> 0014 0006 -> 0018 0010 -> 0056 0011 -> 0059 0012 -> 0060 0013 -> 0091 1) [Install Kitti2Bag](https://github.com/tomas789/kitti2bag) ``` pip install kitti2bag ``` 2) Convert scenario `0060` into a ROSbag file: * Download and unzip the `synced+rectified data` file and its `calibration` file from the [KITTI Raw Dataset](http://www.cvlibs.net/datasets/kitti/raw_data.php) * Merge both files into one ROSbag file ``` cd ~/kitti_data/ kitti2bag -t 2011_09_26 -r 0060 raw_synced ``` 3) Synchronize the sensor data: * The script matches the timestamps of the Velodyne point cloud data with the camara data to perform Sensor Fusion in a synchronized way within the ROS framework ``` cd ~/catkim_ws/src/ROS_Perception_Kitti_Dataset/pre_processing/ python sync_rosbag.py raw_synced.bag ``` 4) Store preprocessed semantic segmentated images: * The camera data is preprocessed within a Deep Neural Network to create semantic segmentated images. With this step a "real-time" performance on any device (CPU usage) can be guaranteed ``` mkdir ~/kitti_data/0060/segmented_semantic_images/ cd ~/kitti_data/0060/segmented_semantic_images/ ``` * For any other scenario follow this steps: Well pre-trained network with an IOU of 73% can be found here: [Finetuned Google's DeepLab on KITTI Dataset](https://github.com/hiwad-aziz/kitti_deeplab) ### Troubleshooting * Make sure to close RVIz and restart the ROS launch command if you want to execute the scenario again. Otherwise it seems like the data isn't moving anymore ([see here](https://github.com/appinho/SARosPerceptionKitti/issues/7)) * Semenatic images warning: Go to sensor.cpp line 543 in sensor_processing_lib and hardcode your personal home directory! ([see full discussion here](https://github.com/appinho/SARosPerceptionKitti/issues/10)) * Make sure the scenario is encoded as 4 digit number, like above `0060` * Make sure the images are encoded as 10 digit numbers starting from `0000000000.png` * Make sure the resulting semantic segmentated images have the color encoding of the [Cityscape Dataset](https://www.cityscapes-dataset.com/examples/) ### Results Evaluation results for 7 Scenarios `0011,0013,0014,0018,0056,0059,0060` | Class | MOTP | MODP | | ------------ |:-------:|:-------:| | Car | 0.715273| 0.785403| | Pedestrian | 0.581809| 0.988038| ### Area for Improvements * Friendly solution to not hard code the user's home directory path * Record walk through video of entire project * Find a way to run multiple scenarios with one execution * Improving the Object Detection: * Visualize Detection Grid * Incorporate features of the shape of cars * Handle false classification within the semantic segmentation * Replace MinAreaRect with better fitting of the object's bounding box * Integrate view of camera image to better group clusters since point clouds can be spare for far distances * Improving the Object Tracking: * Delete duplicated tracks * Soften yaw estimations * Improve evaluation * Write out FP FN * Try different approaches: * Applying the VoxelNet ### To Do * Make smaller gifs * Double check * transformation from camera 02 to velo * grid to point cloud has any errors * Reduce street pavement error prone cells * Objects to free space or not ## Evaluation for 7 Scenarios 0011,0013,0014,0018,0056,0059,0060 | Class | MOTA | MOTP | MOTAL | MODA | MODP | | ------------ |:-------:|:-------:|:-------:|:-------:|:-------:| | CAR | 0.250970| 0.715273| 0.274552| 0.274903| 0.785403| | PEDESTRIAN |-0.015038| 0.581809|-0.015038|-0.015038| 0.988038| [157, 154, 280, 306, 378, 1283, 17] [64, 10, 10, 72, 11, 196, 0] [39, 75, 120, 39, 33, 569, 0] [8, 0, 1, 0, 4, 18, 18] [3, 0, 2, 0, 0, 52, 0] [172, 0, 63, 0, 25, 177, 46] ## Pipeline ### 1a) Sensor Fusion: Velodyne Point Cloud Processing * [Ground extraction & Free space estimation](http://wiki.ros.org/but_velodyne_proc) ### 1b) Sensor Fusion: Raw Image Processing * [Semantic segmentation](https://github.com/martinkersner/train-DeepLab) ### 1c) Sensor Fusion: Mapping Point Cloud and Image ### 2 Detection: DBSCAN Clustering ### 3 Tracking: UKF Tracker Video image linker example [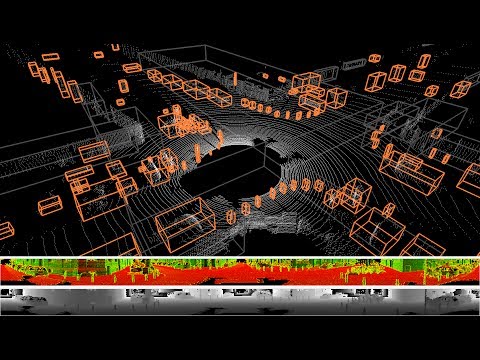](https://www.youtube.com/watch?v=UXHX9kFGXfg "Segmentation") -->