Awesome
AdaGlimpse: Active Visual Exploration with Arbitrary Glimpse Position and Scale (ECCV 2024)
Project Page | Paper | Checkpoints
Official PyTorch implementation of the paper: "AdaGlimpse: Active Visual Exploration with Arbitrary Glimpse Position and Scale"
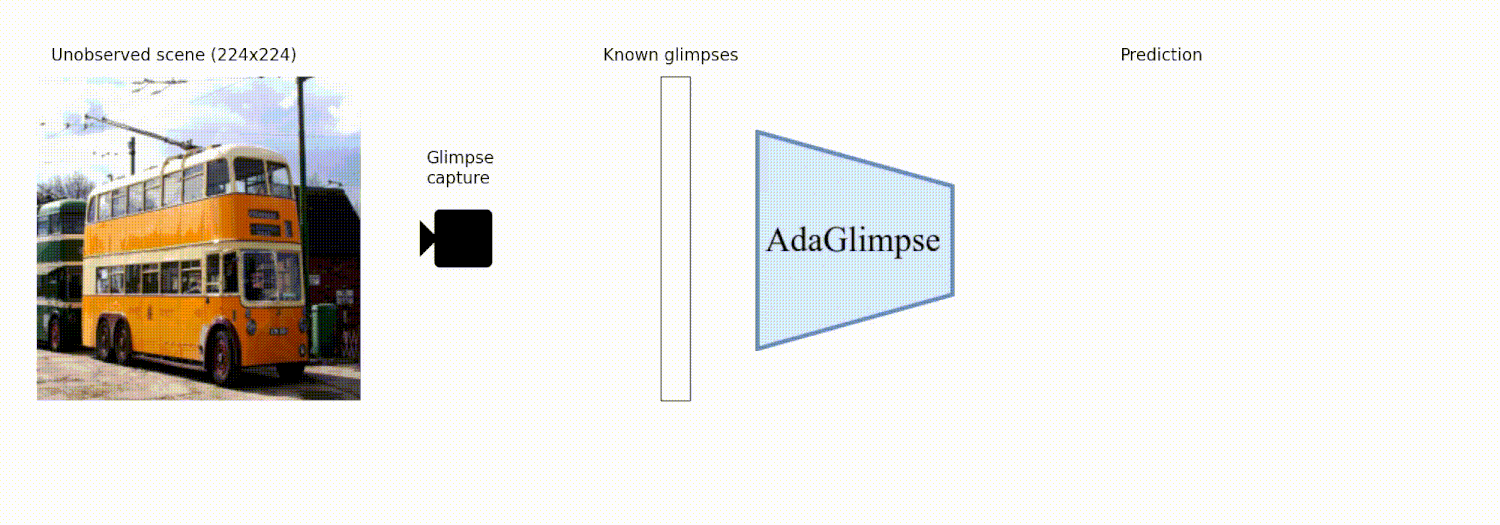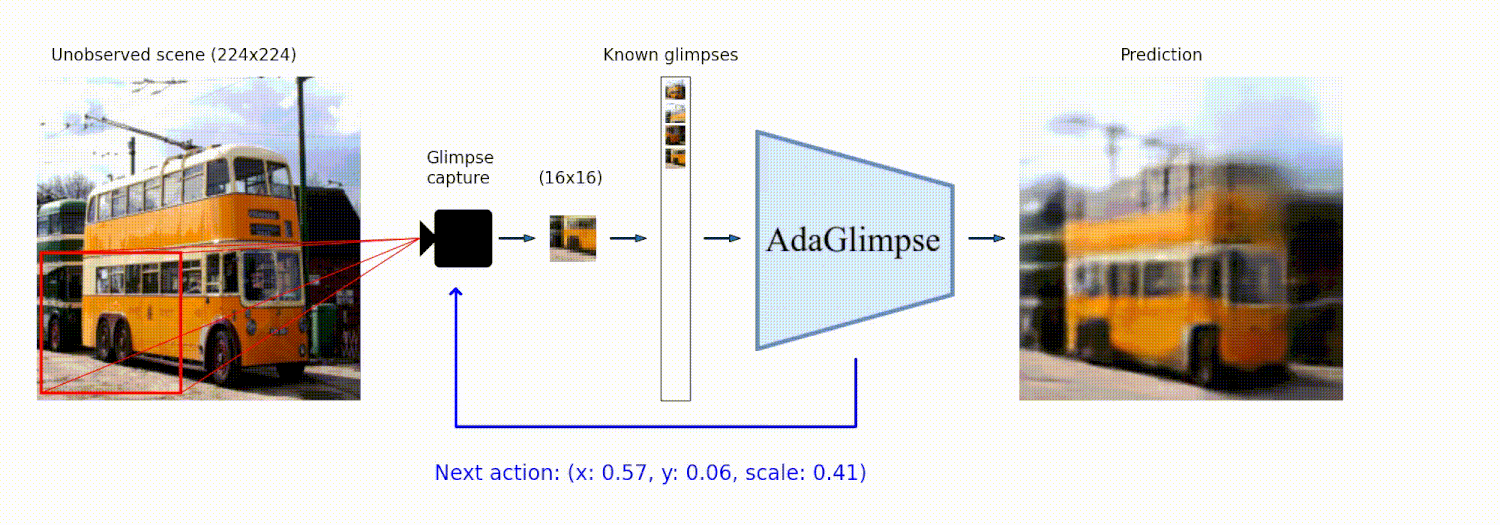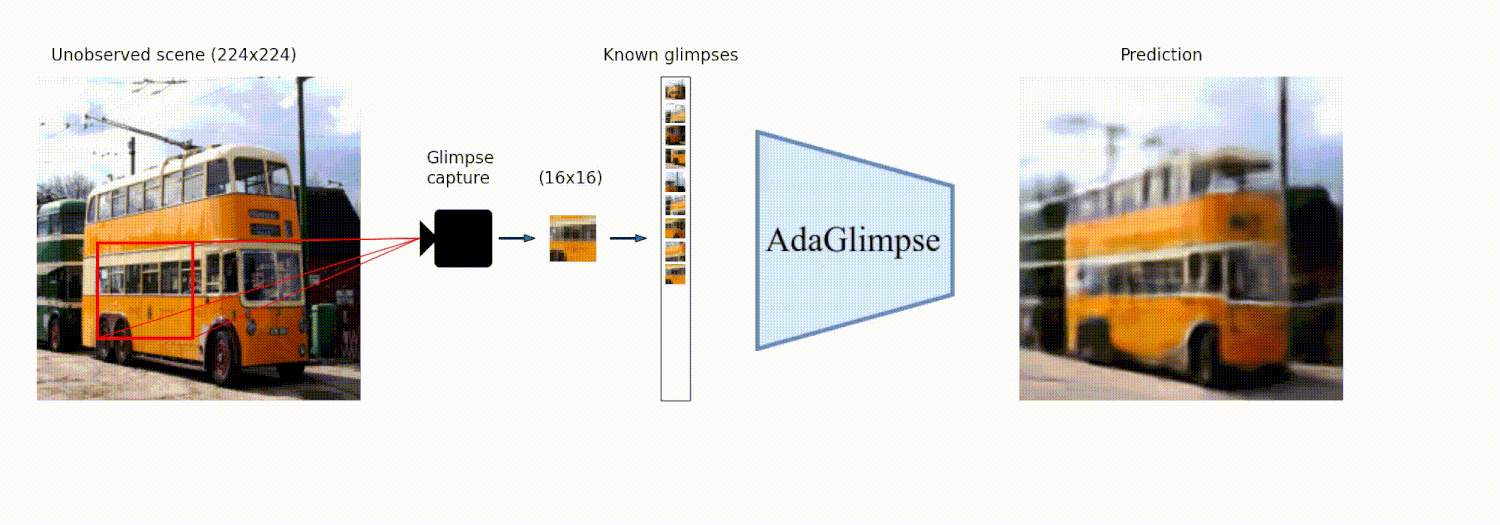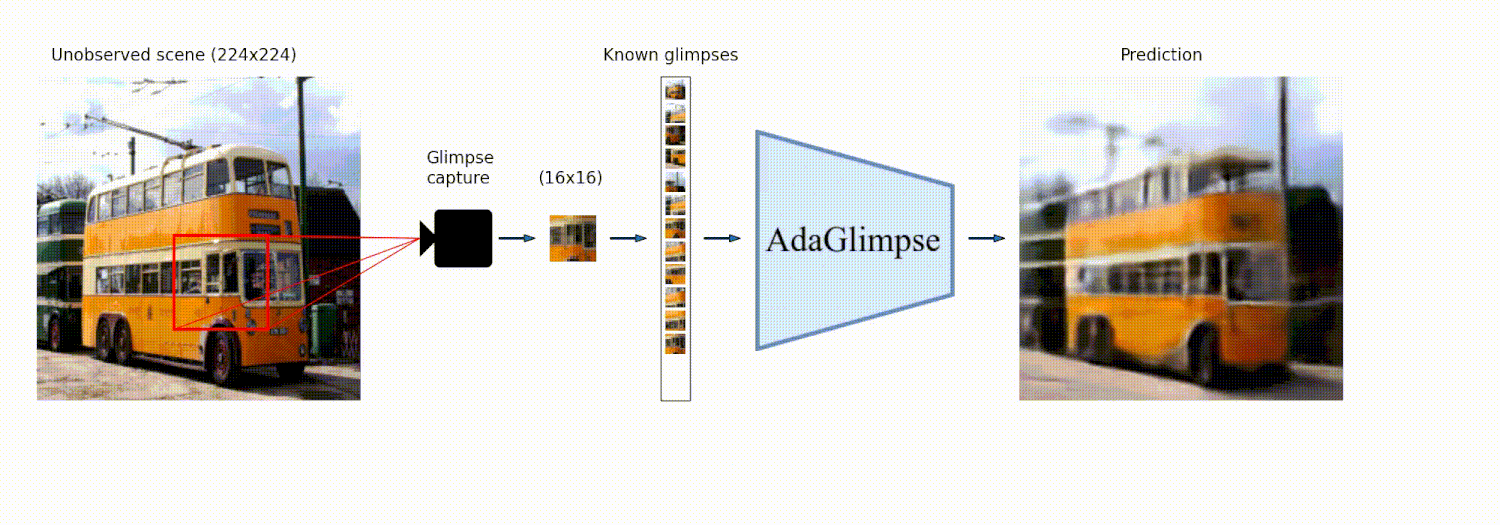
AdaGlimpse: Active Visual Exploration with Arbitrary Glimpse Position and Scale<br> Adam Pardyl, Michał Wronka, Maciej Wołczyk, Kamil Adamczewski, Tomasz Trzciński, Bartosz Zieliński<br> https://arxiv.org/abs/2404.03482<br>
Abstract: Active Visual Exploration (AVE) is a task that involves dynamically selecting observations (glimpses), which is critical to facilitate comprehension and navigation within an environment. While modern AVE methods have demonstrated impressive performance, they are constrained to fixed-scale glimpses from rigid grids. In contrast, existing mobile platforms equipped with optical zoom capabilities can capture glimpses of arbitrary positions and scales. To address this gap between software and hardware capabilities, we introduce AdaGlimpse. It uses Soft Actor-Critic, a reinforcement learning algorithm tailored for exploration tasks, to select glimpses of arbitrary position and scale. This approach enables our model to rapidly establish a general awareness of the environment before zooming in for detailed analysis. Experimental results demonstrate that AdaGlimpse surpasses previous methods across various visual tasks while maintaining greater applicability in realistic AVE scenarios.
Setup
git clone https://github.com/apardyl/AdaGlimpse.git && cd AdaGlimpse
conda env create -f environment.yml -n AdaGlimpse # we recommend using mamba instead of conda (better performance)
conda activate AdaGlimpse
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
conda install timm lightning wandb rich scipy -c conda-forge
conda config --set pip_interop_enabled True
pip install torchrl
Train
- download and extract the requested dataset
- run training with:
python train.py <dataset> <model> [params]
where dataset is one of:
- Reconstruction task:
- ADE20KReconstruction
- Coco2014Reconstruction
- Sun360Reconstruction
- TestImageDirReconstruction (any directory with jpg files)
- ImageNet1k
- Segmentation task:
- ADE20KSegmentation
- Classification task:
- Sun360Classification
- ImageNet1k
and the model is:
- ClassificationRlMAE for classification
- ReconstructionRlMAE for reconstruction
- SegmentationRlMAE for segmentation
Example: Run reconstruction task on ImageNet-1k:
python train.py ImageNet1k ReconstructionRlMAE --data-dir DATASET_DIR --train-batch-size 128 --eval-batch-size 128 --rl-batch-size 128 --num-workers 8 --parallel-games 2 --num-glimpses 12
Run classification task on ImageNet-1k:
python train.py ImageNet1k ClassificationRlMAE --data-dir $DATASET_DIR --wandb --train-batch-size 256 --eval-batch-size 256 --rl-batch-size 256 --num-workers 8 --parallel-games 2 --num-glimpses 14 --pretrained-mae-path elastic_base.pth --teacher-type vit --teacher-path deit_3_base_224_21k.pth
Batch size should be adjusted to fit the available GPU memory, the above examples assume NVIDIA A100 GPUs.
Training takes a long time, for ImageNet-1k tasks it takes around 1 week on 4x A100 GPUs.
Run python train.py <dataset> <model> --help for all available training params.
Visualizations form the paper and website can be generated using predict.py
(use --help param for more information).
Trained models
- AdaGlimpse final training checkpoints can be downloaded from: https://huggingface.co/apardyl/AdaGlimpse
- Pre-trained ViT backbone model for ImageNet-1k for training AdaGlimpse can be found at: https://huggingface.co/apardyl/BeyondGrids/blob/main/base_224.pth
- ViT teacher model for ImageNet-1k classification: https://dl.fbaipublicfiles.com/deit/deit_3_base_224_21k.pth