Awesome
Just Ask: Learning to Answer Questions from Millions of Narrated Videos
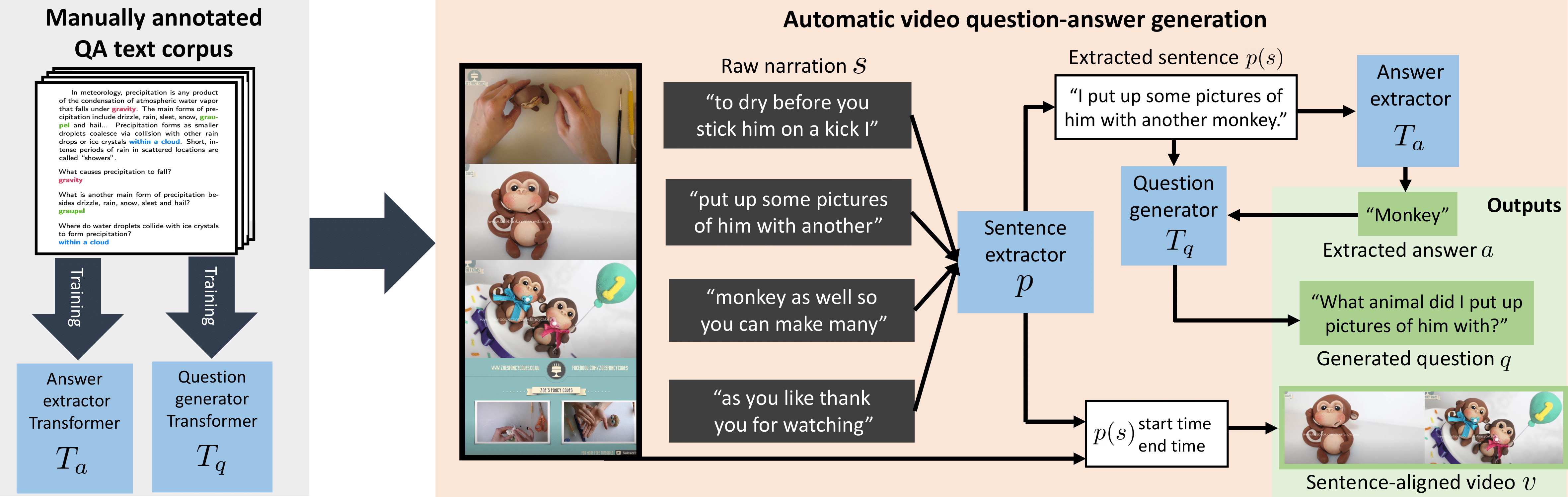
In this work, we automatically generate large-scale video question answering data from narrated videos, leverage contrastive learning to train on large vocabularies on answers, and show the first zero-shot video question answering results, without any manual annotation of visual data.
This repository provides the code for our paper, including:
- Data downloading instructions, including our released iVQA, HowToVQA69M and WebVidVQA3M datasets
- Data preprocessing and feature extraction scripts, as well as preprocessed data and features
- VideoQA automatic generation pipeline
- Training scripts and pretrained checkpoints, both for pretraining and downstream VideoQA datasets
- Evaluation scripts
News 26/09/2022: If you find this work interesting, you may check our related NeurIPS 2022 repository: Zero-Shot Video Question Answering via Frozen Bidirectional Language Models.
News 25/04/2022: The extended version of Just Ask has been accepted to the TPAMI Special Issue on the Best Papers of ICCV 2021. This repository now includes functionalities related to this extension (WebVidVQA3M + VideoQA feature probing).
Paths and Requirements
Fill the empty paths in the file global_parameters.py.
To install requirements, run:
pip install -r requirements.txt
Quick Start
If you wish to start VideoQA training or inference quickly.
For downstream datasets
To download pretrained checkpoints, pre-processed data and features, run:
bash download/download_checkpoints.sh <DEFAULT_CKPT_DIR>
bash download/download_downstream.sh <DEFAULT_DATASET_DIR>
If you have issues with gshell, you can access the preprocessed data here and the checkpoints here.
Another possibility is to use gdown instead.
This requires having about 8Gb free in DEFAULT_CKPT_DIR and 3.6Gb free in DEFAULT_DATASET_DIR.
For HowToVQA69M Pretraining
<details> <summary>Click for details... </summary>If you want to reproduce the pretraining, download HowToVQA69M:
bash download/download_howtovqa.sh <DEFAULT_DATASET_DIR>
If you have issues with gshell, you can access the files here.
This requires having about 6Gb free in DEFAULT_DATASET_DIR. You will also need to download features for videos from HowTo100M from the data providers in HOWTO_FEATURES_PATH.
For WebVidVQA3M Pretraining
<details> <summary>Click for details... </summary>If you want to reproduce the pretraining, download WebVidVQA3M:
bash download/download_webvidvqa.sh <DEFAULT_DATASET_DIR>
If you have issues with gshell, you can access the files here.
This requires having about 1Gb free in DEFAULT_DATASET_DIR. You will also need to download videos from WebVid from the data providers, and extract features following the instructions below in WEBVID_FEATURES_PATH.
Long Start
If you wish to reproduce the data preprocessing, video feature extraction or HowToVQA69M/WebVidVQA3M generation procedure.
Download Raw Data
<details> <summary>Click for details... </summary>The following folders should be created in DEFAULT_DATASET_DIR, and should also contain a video subfolder containing the videos downloaded from each dataset.
HowToVQA69M: We provide the HowToVQA69M dataset at this link.
The HowToVQA69M folder should contain howtovqa.pkl, train_howtovqa.csv and val_howtovqa.csv.
iVQA: We provide the iVQA dataset at this link.
The iVQA folder should contain train.csv, val.csv and test.csv.
MSRVTT-QA: Download it from the data providers.
The MSRVTT-QA folder should contain train_qa.json, val_qa.json, test_qa.json, and also train_val_videodatainfo.json and test_videodatainfo.json.
The two last files are from the MSR-VTT dataset, and are used to filter out video IDs in HowTo100M that are in the validation and test sets of MSRVTT-QA.
MSVD-QA: Download it from the data providers.
The MSVD-QA folder should contain train_qa.json, val_qa.json, test_qa.json and youtube_mapping.txt.
The last file is used to filter out videos IDs in HowTo100M that are in the validation and test sets of MSVD-QA.
ActivityNet-QA: Download it from the data providers.
The ActivityNet-QA folder should contain train_q.json, train_a.json, val_q.json, val_a.json, test_q.json and test_a.json.
How2QA: Download it from the data providers.
The How2QA folder should contain how2QA_train_release.csv and how2QA_val_release.csv.
HowTo100M: Download it from the data providers.
The HowTo100M folder should contain caption_howto100m_with_stopwords.pkl and s3d_features.csv.
Note that for the VQA-T pretraining on HowTo100M baseline, we also do zero-shot validation on YouCook2 and MSR-VTT video retrieval. We followed MIL-NCE for the preprocessing of these datasets. You should have in the YouCook2 folder a pickle file with processed data and features youcook_unpooled_val.pkl, and in the MSR-VTT folder a file of processed data MSRVTT_JSFUSION_test.csv and a file of features msrvtt_test_unpooled_s3d_features.pth.
WebVid2M Download it from the data providers.
The WebVid folder should contain train_2M_results.csv and val_2M_results.csv.
Data Preprocessing
<details> <summary>Click for details... </summary>VideoQA: To process data for each VideoQA dataset, use:
python preproc/preproc_ivqa.py
python preproc/preproc_msrvttqa.py
python preproc/preproc_msvdqa.py
python preproc/preproc_activitynetqa.py
python preproc/preproc_how2qa.py
This will save train, validation and test dataframe files (train.csv, val.csv, test.csv), and the vocabulary map (vocab.json) in the open-ended setting, in each dataset folder.
Note that the How2QA preprocessing script should be used after feature extraction (see below) and will also merge features into one file.
HowTo100M: To preprocess HowTo100M by removing potential intersection with the validation and test sets of VideoQA datasets, and removing repetition in the ASR data, use:
python preproc/howto100m_remove_intersec.py
python preproc/howto100m_remove_repet.py
This will save caption_howto100m_sw_nointersec.pickle, caption_howto100m_sw_nointersec_norepeat.pickle and s3d_features_nointersec.csv in HOWTO_PATH.
Extract video features
<details> <summary>Click for details... </summary>We provide in the extract folder the code to extract features with the S3D feature extractor. It requires downloading the S3D model weights available at this repository. The s3d_howto100m.pth checkpoint and s3d_dict.npy dictionary should be in DEFAULT_MODEL_DIR.
Extraction: You should prepare for each dataset a csv with columns video_path (typically in the form of <dataset_path>/video/<video_path>), and feature_path (typically in the form of <dataset_path>/features/<video_path>.npy). Then use (you may launch this script on multiple GPUs to fasten the extraction process):
python extract/extract.py --csv <csv_path>
Merging: To merge the extracted features into a single file for each VideoQA dataset, use (for ActivityNet-QA that contains long videos, add --pad 120):
python extract/merge_features.py --folder <features_path> \
--output_path <DEFAULT_DATASET_DIR>/s3d.pth --dataset <dataset>
For HowTo100M, the features should be stored in HOWTO_FEATURES_PATH, one file per video. Similarly, for WebVid2M, the features should be stored in WEBVID_FEATURES_PATH, one file per video. SSD_PATH should preferably on a SSD disk for optimized on-the-fly reading operation time during pretraining.
HowToVQA69M Generation
<details> <summary>Click for details... </summary>This requires downloading the pretrained BRNN model weights from Punctuator2. The INTERSPEECH-T-BRNN.pcl file should be in DEFAULT_MODEL_DIR.
Punctuating: First, we punctuate the speech data at the video level and split the video into clips temporally aligned with infered sentences (you may launch this script on multiple CPUs to fasten the process):
python videoqa_generation/punctuate.py
Merging infered speech sentences: Second, we merge the punctuated data into one file:
python videoqa_generation/merge_punctuations.py
Extracting answers: Third, we extract answers from speech transcripts. This requires having cloned this repository in QG_REPO_DIR. Then use (you may launch this script on multiple GPUs to fasten the process):
python videoqa_generation/extract_answers.py
Merging extracted answers: Fourth, we merge the extracted answers into one file:
python videoqa_generation/merge_answers.py
Generating questions: Fifth, we generate questions pairs from speech and extracted answers. Use (you may launch this script on multiple GPUs to fasten the process):
python videoqa_generation/generate_questions.py
Merging generated question-answer pairs: Finally, we merge the generated question-answer pairs into one file (this will save howtovqa.pkl, train_howtovqa.csv and val_howtovqa.csv):
python videoqa_generation/merge_qas.py
WebVidVQA3M Generation
<details> <summary>Click for details... </summary>This requires downloading the pretrained BRNN model weights from Punctuator2. The INTERSPEECH-T-BRNN.pcl file should be in DEFAULT_MODEL_DIR.
Extracting answers: First, we extract answers from speech transcripts. This requires having cloned this repository in QG_REPO_DIR. Then use (you may launch this script on multiple GPUs to fasten the process):
python videoqa_generation/extract_answers_webvid.py
Merging extracted answers: Second, we merge the extracted answers into one file:
python videoqa_generation/merge_answers_webvid.py
Generating questions: Third, we generate questions pairs from speech and extracted answers. Use (you may launch this script on multiple GPUs to fasten the process):
python videoqa_generation/generate_questions_webvid.py
Merging generated question-answer pairs: Finally, we merge the generated question-answer pairs into one file (this will save webvidvqa.pkl, train_webvidvqa.csv and val_webvidvqa.csv):
python videoqa_generation/merge_qas_webvid.py
Training
Pretraining
If you wish to train a VideoQA model on Web videos.
Training VQA-T on HowToVQA69M:
<details> <summary>Click for details... </summary> To train on HowToVQA69M with contrastive loss and MLM loss (it takes less than 48H on 8 NVIDIA Tesla V100), run: ``` python main_howtovqa.py --dataset="howtovqa" --epochs=10 --checkpoint_dir="pthowtovqa" \ --batch_size=128 --batch_size_val=256 --n_pair=32 --freq_display=10 ``` Note that it runs a validation once per epoch, which consists in retrieving answer within the batch, given video and question. Also note that DistilBERT tokenizer and model checkpoints will be automatically downloaded from [Hugging Face](https://huggingface.co/transformers/) in `DEFAULT_MODEL_DIR/transformers`. </details>Training VQA-T on WebVidVQA3M:
<details> <summary>Click for details... </summary> To train on WebVidVQA3M with contrastive loss and MLM loss (it takes less than 3H on 8 NVIDIA Tesla V100), ``` python main_howtovqa.py --dataset="webvidvqa" --epochs=10 --checkpoint_dir="ptwebvidvqa" \ --batch_size=4096 --batch_size_val=8192 --freq_display=10 ``` Note that it runs a validation once per epoch, which consists in retrieving answer within the batch, given video and question. To train on HowToVQA69M then on WebVidVQA3M, simply run the training on HowToVQA69M and pass the checkpoint path to the `pretrain_path` argument. </details>Baselines:
<details> <summary>Click for details... </summary>The pretraining of QA-T on HowToVQA69M is done with the previous command complemented with --baseline qa. To train VQA-T on HowTo100M with MLM and cross-modal matching objectives (it takes less than 2 days on 8 NVIDIA Tesla V100), run:
python main_htm.py --dataset="howto100m" --epochs=10 --checkpoint_dir="pthtm" \
--batch_size=128 --batch_size_val=3500 --n_pair=32 --freq_display=10
Note that the previous command runs a zero-shot video retrieval validation on YouCook2 and MSR-VTT once per epoch.
</details>Training on downstream VideoQA datasets
<details> <summary>Click for details... </summary>Finetuning: To finetune a pretrained model on a downstream VideoQA dataset (for MSRVTT-QA, which is the largest downstream dataset, it takes less than 4 hours on 4 NVIDIA Tesla V100), run:
python main_videoqa.py --checkpoint_dir=ft<dataset> --dataset=<dataset> --lr=0.00001 \
--pretrain_path=<CKPT_PATH>
Feature probe: VQA-T feature probing is simply obtained by running the previous script with --probe.
Training from scratch: VQA-T trained from scratch is simply obtained by running the previous script with no pretrain_path set.
Available checkpoints
| Training data | iVQA | MSRVTT-QA | MSVD-QA | ActivityNet-QA | How2QA | url | size |
|---|---|---|---|---|---|---|---|
| HowToVQA69M | 12.2 | 2.9 | 7.5 | 12.2 | 51.1 | Drive | 600MB |
| WebVidVQA3M | 7.3 | 5.3 | 12.3 | 6.2 | 49.8 | Drive | 600MB |
| HowToVA69M + WebVidVQA3M | 13.3 | 5.6 | 13.5 | 12.3 | 53.1 | Drive | 600MB |
| HowToVQA69M + iVQA | 35.4 | Drive | 600MB | ||||
| HowToVQA69M + MSRVTT-QA | 41.5 | Drive | 600MB | ||||
| HowToVQA69M + MSVD-QA | 46.3 | Drive | 600MB | ||||
| HowToVQA69M + ActivityNet-QA | 38.9 | Drive | 600MB | ||||
| HowToVQA69M + How2QA | 84.4 | Drive | 600MB | ||||
| HowToVQA69M + WebVidVQA3M + MSRVTT-QA | 41.8 | Drive | 600MB | ||||
| HowToVQA69M + WebVidVQA3M + MSVD-QA | 47.5 | Drive | 600MB | ||||
| HowToVQA69M + WebVidVQA3M + ActivityNet-QA | 39.0 | Drive | 600MB | ||||
| HowToVQA69M + WebVidVQA3M + How2QA | 85.3 | Drive | 600MB |
Inference
Evaluating on downstream VideoQA datasets
VQA-T To evaluate VQA-T on a downstream VideoQA dataset, run (for zero-shot VideoQA, simply use the checkpoint trained on HowToVQA69M and/or WebVidVQA3M only):
python main_videoqa.py --checkpoint_dir=ft<dataset> --dataset=<dataset> \
--pretrain_path=<CKPT_PATH> --test 1
Baselines In the case of QA-T, use the command above with the corresponding checkpoint and add --baseline qa.
In the case of Zero-Shot VideoQA for VQA-T pretrained on HowTo100M, run:
python eval_videoqa_cm.py --checkpoint_dir=pthtmzeroshot<dataset> --dataset=<dataset> \
--pretrain_path=<CKPT_PATH>
Detailed evaluation
Using a trained checkpoint, to perform evaluation segmented per question type and answer quartile, use:
python eval_videoqa.py --dataset <dataset> --pretrain_path <CKPT_PATH>
VideoQA Demo
Using a trained checkpoint, you can also run a VideoQA example with a video file of your choice, and the question of your choice. For that, use (the dataset indicated here is only used for the definition of the answer vocabulary):
python demo_videoqa.py --dataset <dataset> --pretrain_path <CKPT_PATH> \
--question_example <question> --video_example <video_path>
Note that we also host an online demo at this link.
Misc.
<details> <summary>Click for details... </summary> In the folder misc, you can find a notebook with code for the plots and data statistics showed in the paper.You can also find there the html code used for iVQA data collection on Amazon Mechanical Turk.
Moreover, you can find the manually evaluated samples from generated data at this link.
Finally, you can find the html and python code for the online demo.
</details>Acknowledgements
The video feature extraction code is inspired by this repository. The model implementation of our multi-modal transformer (as well as the masked language modeling setup) is inspired by Hugging Face. The comparison with Heilman et al was done using the original Java implementation.
Citation
If you found this work useful, consider giving this repository a star and citing our papers as followed:
@inproceedings{yang2021justask,
title={Just Ask: Learning to Answer Questions from Millions of Narrated Videos},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
booktitle={ICCV},
year={2021}}
@article{yang2022learningta,
title={Learning to Answer Visual Questions from Web Videos},
author={Antoine Yang and Antoine Miech and Josef Sivic and Ivan Laptev and Cordelia Schmid},
journal={IEEE TPAMI},
year={2022}}