Awesome
Visual Prompting via Image Inpainting
Amir Bar*, Yossi Gandelsman*, Trevor Darrell, Amir Globerson, Alexei A. Efros
This repository is the implementation of the paper, for more info about this work see Project Page. You can experiment with visual prompting using this (demo)[demo.ipynb].
Abstract
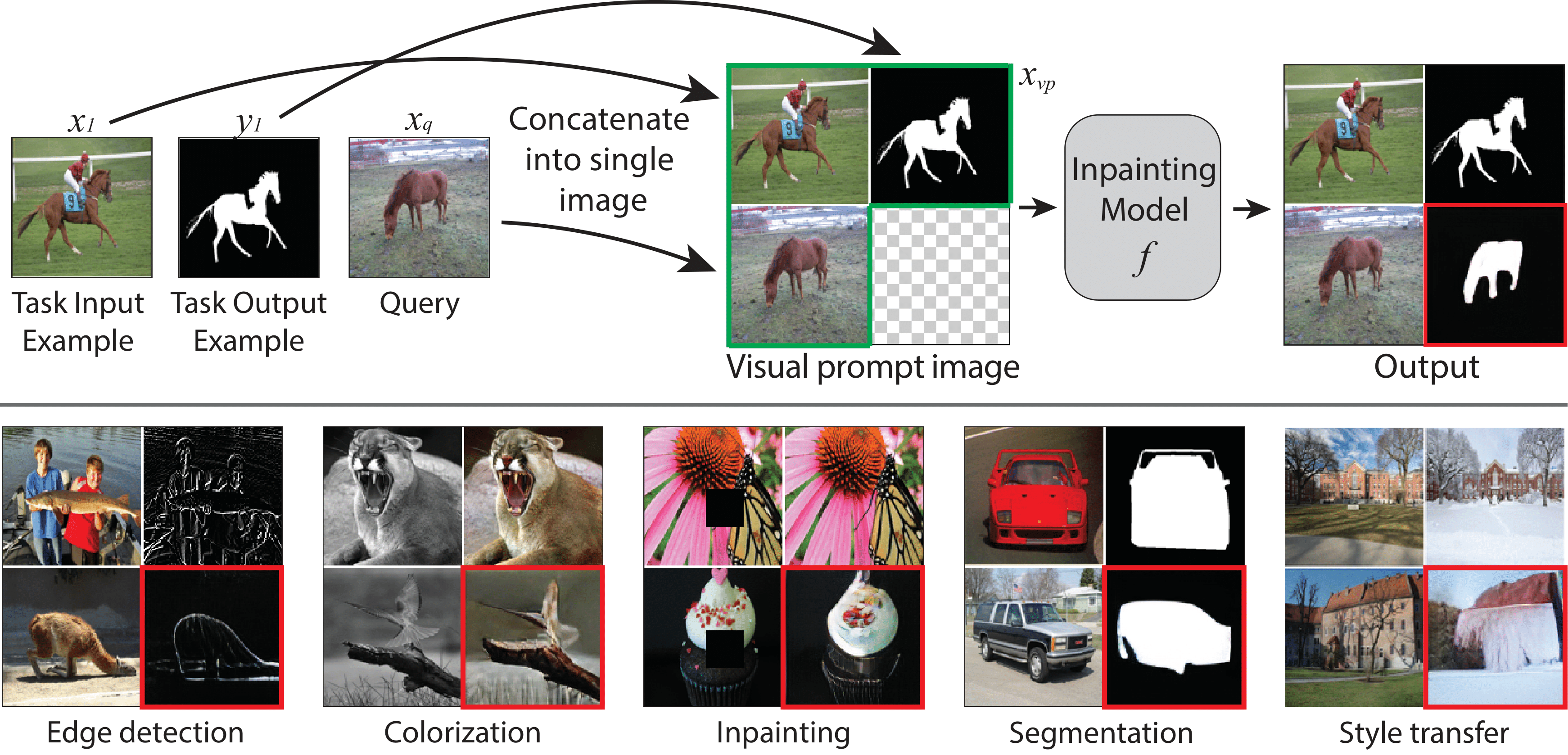
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the correct output image, consistent with the example(s) task. We show that posing this problem as a simple image inpainting task - literally just filling in a hole in a concatenated visual prompt image - turns out to be surprisingly effective, given that the inpainting algorithm has been trained on the right data. We train masked auto-encoding models on a new dataset that we curated - 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
Computer Vision Figures Dataset
To download the dataset run:
cd figures_dataset
sudo apt-get install poppler-utils
pip install -r requirements.txt
Download train/val:
python download_links.py --output_dir <path_to_output_dir> --split train
python download_links.py --output_dir <path_to_output_dir> --split val
Note: the paper sources are hosted by arXiv and download time might take 2-3 days. <br>For inquiries/questions about this please email the authors directly.
Train
Prerequisites
pytorch/pytorch-lightining installation, set cudatoolkit to your cuda version or choose an installation using these instructions.
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cudatoolkit=11.1 pytorch-lightning==1.6.2 -c pytorch -c conda-forge
Then install the following requirements:
pip install -r requirements.txt
Download pretrained VQGAN codebook checkpoint and config vqgan_imagenet_f16_1024, place both last.ckpt and model.yaml on the repository root.
Pretrain a model on CVF dataset with 8 V100 gpus:
python -m torch.distributed.launch --nproc_per_node=8 main_pretrain.py --model mae_vit_large_patch16 --input_size 224 --batch_size 64 --mask_ratio 0.75 --warmup_epochs 15 --epochs 1000 --blr 1e-4 --save_ckpt_freq 100 --output_dir logs_dir/maevqgan --data_path <path_to_dataset>
Evaluation
Dataset preparation:
Our evaluation pipeline is based on Volumetric Aggregation Transformer. Please follow the dataset preparation steps for PASCAL-5i dataset in this repository.
Evaluate on Foreground Segm on Pascal 5i on split [0-3]:
cd evaluate && python evaluate_segmentation.py \
--model mae_vit_large_patch16 \
--base_dir <pascal_5i_basedir> \
--output_dir <outputs_dir> \
--ckpt <model_ckp_path> \
--split <split> \
--dataset_type pascal
The script will save a log.txt file with the results as well as results visualization.
Evaluate on Reasoning Tasks:
set dataset_type to the reasoning task out of 'color' 'shape' 'size' 'shape_color' 'size_color' 'size_shape'.
python -m evaluate.evaluate_reasoning \
--model mae_vit_large_patch16 \
--output_dir <outputs_dir> \
--ckpt <model_ckp_path>\
--dataset_type color \
--tta_option 0
tta_option allows to play with different prompt ensmebling. tta_option=0 is for standard visual prompt. Other configurations are listed in visual_prompting/evaluate/evaluate_reasoning.py:42 The script will save a log.txt file with the results as well as results visualization.
Evaluate on Single Object Detection:
cd evaluate && python evaluate_segmentation.py \
--task detection \
--model mae_vit_large_patch16 \
--base_dir <pascal_5i_basedir> \
--output_dir <outputs_dir> \
--ckpt <model_ckp_path> \
--dataset_type pascal_det
The script will save a log.txt file with the results as well as results visualization.
Evaluate on Colorization:
python -m evaluate.evaluate_colorization \
--model mae_vit_large_patch16 \
--output_dir <outputs_dir> \
--ckpt <model_ckp_path>\
--data_path <path_to_imagenet_dir>
The script will save a log.txt file with the results as well as results visualization.
Pretrained Models
| Model | Pretraining | Epochs | Link |
|---|---|---|---|
| MAE-VQGAN (ViT-L) | CVF | 1000 | link |
| MAE-VQGAN (ViT-L) | CVF + IN | 3400 | link |