Awesome
EN-data_mining
Data Mining Historical Newspapers Metadata (Europeana Newspaper Project)
Synopsis
Newspapers from European digital librabries collections are part of the data set OLR’ed (Optical Layout Recognition) by the project Europeana Newspapers (www.europeana-newspapers.eu). The OLR refinement consists of the description of the structure of each issue and articles (spatial extent, title and subtitle, classification of content types) using the METS/ALTO formats.
From each digital document is derived a set of bibliographical metadata (date of publication, title) and quantitative metadata related to content and layout (number of pages, articles, words, illustrations, etc.). Shell and XSLT or Perl scripts are used to extract some metadata from METS manifest or from ALTO files.
Installation
You can use a XSLT stylesheet (called with DOS scripts) or a Perl script (faster).
Sample documents are stored in the "DOCS" folder. The scripts have been designed for the CCS METS/ALTO profil, but this can be easily fixed.
The metadata are generated in a "STATS" folder.
XSLT
Two DOS shell scripts :
- batch-EN.bat
- xslt.cmd
Two XSLT stylesheets:
- analyseAltosCCS.xsl
- calculeStatsMETS_CSV.xsl
The XSLT are runned with Xalan-Java. Path to the Java binary must be set in xslt.cmd.
For each document, its metadata are stored in the STATS folder under two formats :
- XML (raw metadata, with detailled values for each page)
- CSV (metadata at the issue level)
An aggregated file (metadata.csv) contains all the CSV metadata.
Test
- Open a DOS terminal.
- Change dir to the batch folder
-
batch-EN.bat
Perl script
Faster and richer (more metadata) than the XSLT scripts.
- One Perl script: extractMD.pl
- One shell script (Bash): batch.sh (runs the Perl script and packages the results files)
For each document, metadata are stored in the STATS folder (available formats : XML, JSON, CSV, txt)
Test
- Open a shell terminal (Linux, Mac OS X).
- Change dir to the batch folder
-
perl extractMD.pl DOCS xml json csv
Charts
See here.
(Made with Highcharts)
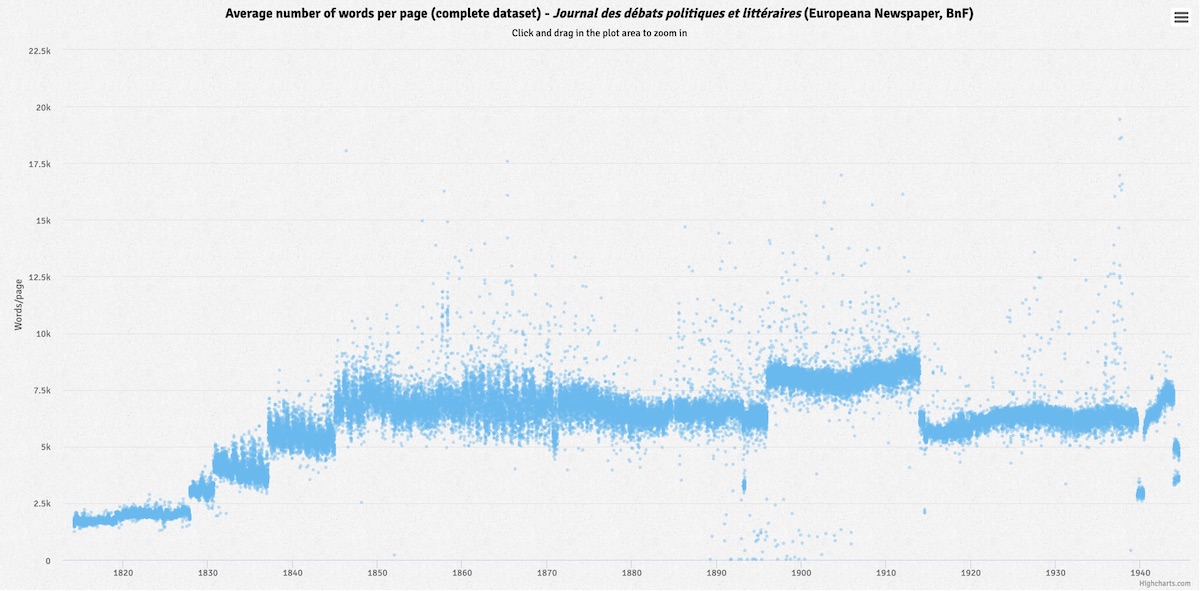
Journal des débats politiques et littéraires : Number of words per page (complete dataset, interactive timeline)
Datasets
The complete set of derived data contains about 5,500,000 atomic metadata from six national and regional French newspapers (1814-1945, 880,000 pages, 150,000 issues) of Gallica (www.gallica.fr) press collections:
- Le Matin
- Le Gaulois
- Le Petit journal illustré
- Le Journal des débats politiques et littéraires
- Le Petit Parisien
- Ouest-Eclair
The datasets (XML, CSV or JSON formats) are publicly available here
API
XQuery based HTTP APIs to request BaseX XML databases:
- findIllustratedPages: look for graphical pages (at least one illustration and a small word density)
- findCaptionedIllustrations: look in the illustrations captions (to be used on the "captions" dataset)
Test
- Install BaseX.
- Import one (or all) the datasets in a BaseX database.
- Launch the BaseX HTTP server (bin/basexhttp)
- Say to BaseX where are your XQuery files: in the .basex config file, edit RESTPATH. Eg RESTPATH=$home/BaseXWeb
- Store your XQuery files (.xq) in the $RESTPATH folder
- Fix the database name in the XQuery files (last lines of the scripts)
- Open a web browser and test the service: http://localhost:8984/rest lists the available databases and http://localhost:8984/rest/database_name gives the content of a database (first connection: ID=admin, passwd=admin)
- Test the API: http://localhost:8984/rest?run=findCaptionedIllustrations.xq&fromDate=1886-01-01&keyword=statue.*libert%C3%A9
License
CC0
<a href="http://creativecommons.org/publicdomain/zero/1.0/"><img src="https://camo.githubusercontent.com/4df6de8c11e31c357bf955b12ab8c55f55c48823/68747470733a2f2f6c6963656e7365627574746f6e732e6e65742f702f7a65726f2f312e302f38387833312e706e67" alt="CC0" data-canonical-src="https://licensebuttons.net/p/zero/1.0/88x31.png" style="max-width:100%;"></a>
This work has been part-funded through the EU Competitiveness and Innovation Framework Programme grant Europeana Newspapers (Ref. 297380)