Awesome
MPT 30B inference code using CPU
Run inference on the latest MPT-30B model using your CPU. This inference code uses a ggml quantized model. To run the model we'll use a library called ctransformers that has bindings to ggml in python.
Turn style with history on latest commit:
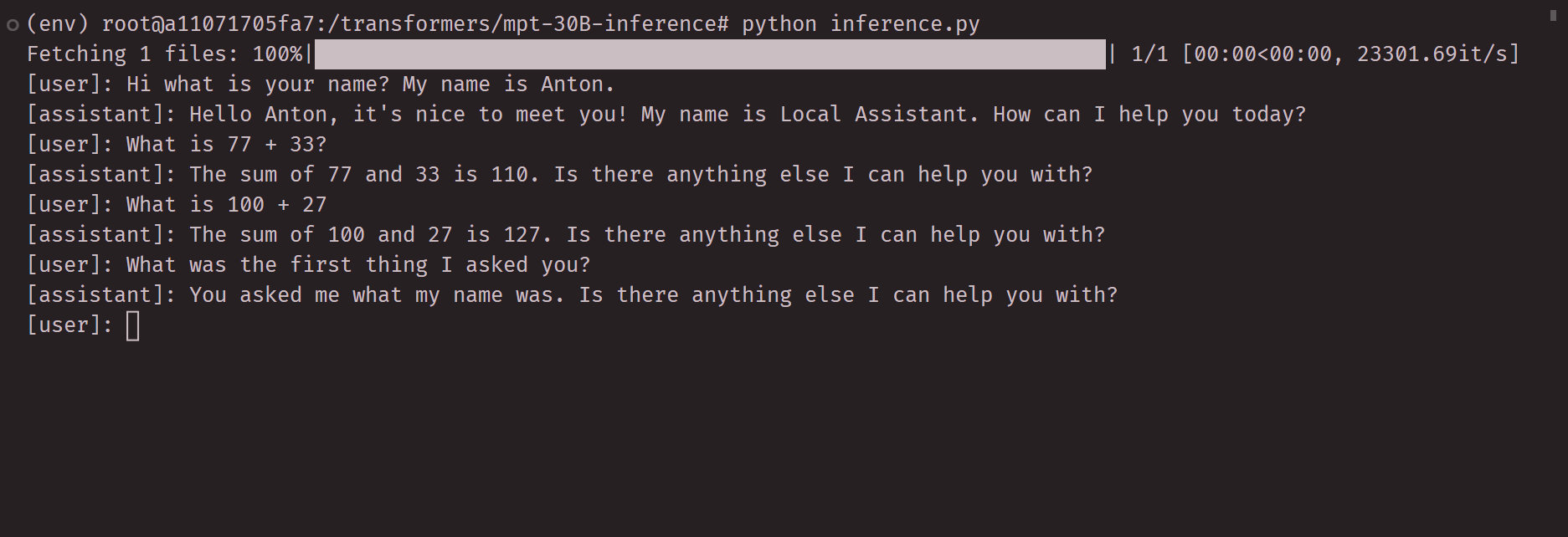
Video of initial demo:
Requirements
I recommend you use docker for this model, it will make everything easier for you. Minimum specs system with 32GB of ram. Recommend to use python 3.10.
Tested working on
Will post some numbers for these two later.
- AMD Epyc 7003 series CPU
- AMD Ryzen 5950x CPU
Setup
First create a venv.
python -m venv env && source env/bin/activate
Next install dependencies.
pip install -r requirements.txt
Next download the quantized model weights (about 19GB).
python download_model.py
Ready to rock, run inference.
python inference.py
Next modify inference script prompt and generation parameters.