Awesome
miniBUDE
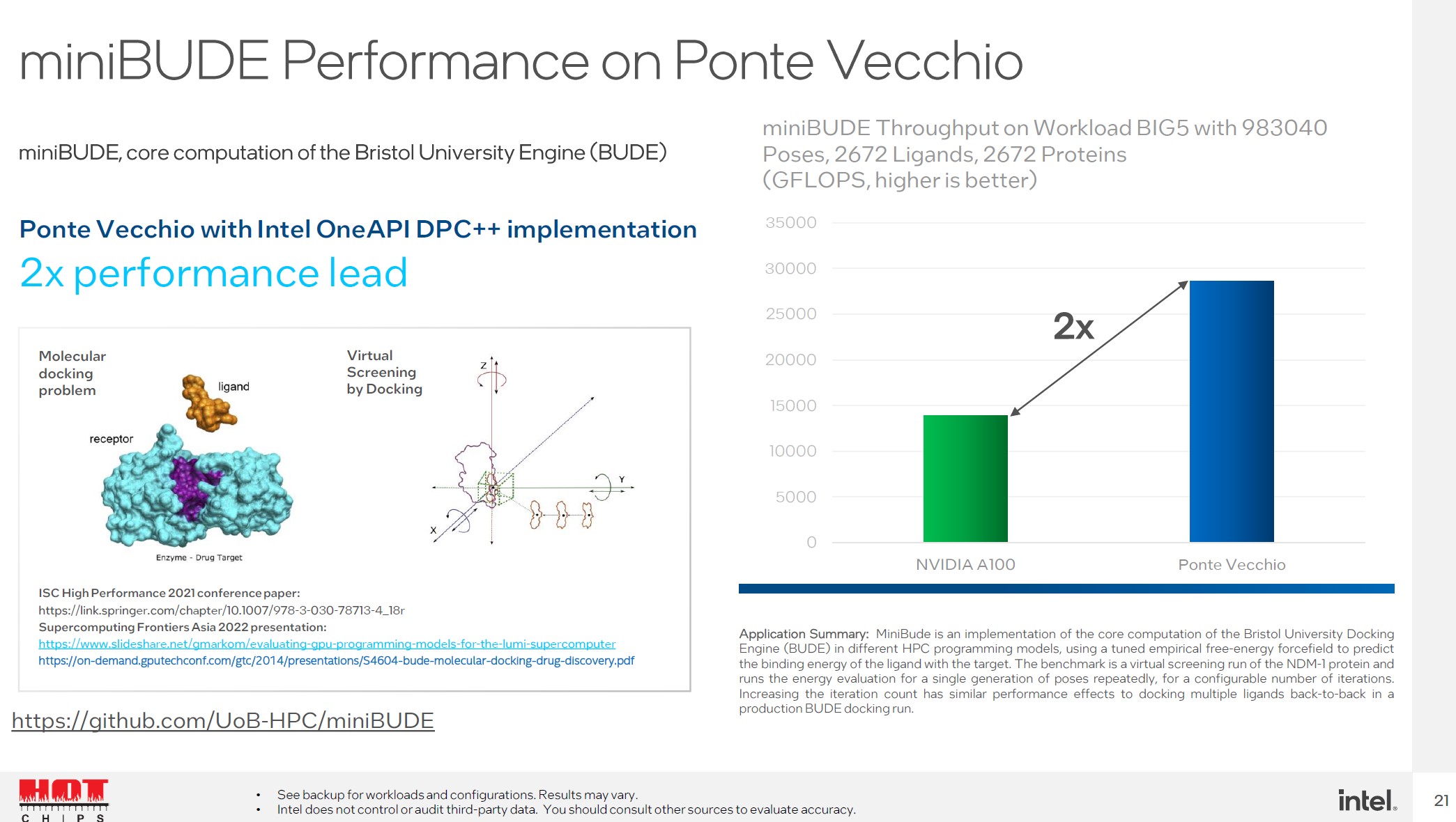
This mini-app is an implementation of the core computation of the Bristol University Docking Engine (BUDE) in different HPC programming models. The benchmark is a virtual screening run of the NDM-1 protein and runs the energy evaluation for a single generation of poses repeatedly, for a configurable number of iterations. Increasing the iteration count has similar performance effects to docking multiple ligands back-to-back in a production BUDE docking run.
[!NOTE]
miniBUDE version 20210901 used in OpenBenchmarking for multiple Phoronix articles and Intel slides uses the v1 branch. The main branch contains an identical kernel but with a unified driver and improved build system.
{kind=link}
Structure
The top-level data directory contains the input common to implementations.
The top-level makedeck directory contains an input deck generation program and a set of mol2/bhff
input files.
Each other subdirectory in src contains a separate C/C++ implementation.
Building
Drivers, compiler, and software applicable to whichever implementation you would like to build against is required. The build system requirement is CMake; no software dependency is required.
CMake
The project supports building with CMake >= 3.14.0, which can be installed without root via the official script.
Each miniBUDE implementation (programming model) is built as follows:
$ cd miniBUDE
# configure the build, build type defaults to Release
# The -DMODEL flag is required
$ cmake -Bbuild -H. -DMODEL=<model> -DCXX_EXTRA_FLAGS=-march=native <more model specific flags prefixed with -D...>
# compile
$ cmake --build build
# run executables in ./build
$ ./build/<model>-bude
The MODEL option selects one implementation of miniBUDE to build.
The source for each model's implementations are located in ./src/<model>.
Currently available models are:
For optional benchmark performance, please set -DCXX_EXTRA_FLAGS=-march=native or
equivalent. -march=native is no longer added by default to prevent bad arch selection on ARM
platforms.
This benchmark should be compiled with relaxed FP rules (e.g. -O3 -ffast-math or -Ofast); a
suitable flags will set automatically if compiling with GCC/Clang and NVHPC.
omp;ocl;std-indices;std-ranges;hip;cuda;kokkos;sycl;acc;raja;tbb;thrust
Running
By default, the following PPWI sizes are compiled: 1,2,4,8,16,32,64,128.
This is a templated compile-time size so the virtual screen kernel is compiled and unrolled for each
PPWI value.
Certain sizes, such as 64, exploits wide vector lengths on platforms that have support (e.g AVX512).
To run with the default options, run the binary without any flags. To adjust the run time, use -i to set the number of iterations. For very short runs, e.g. for simulation, use -n 1024 to reduce the number of poses.
More than one ppwi and wgsize may be specified on models that support this.
When given, miniBUDE will auto-tune all combinations of ppwi and wgsize and print the best
solution in the end.
A heatmap may be generated using this output, see heatmap.py.
Currently, the following models support this scenario: Kokkos, RAJA, CUDA/HIP, OpenCL, CUDA, SYCL,
OpenMP target, and OpenACC.
> ./omp-bude ✔ tom@soraws-uk 11:51:17
miniBUDE:
compile_commands:
- ...
vcs:
...
host_cpu:
~
time: ...
deck:
path: "../data/bm1"
poses: 65536
proteins: 938
ligands: 26
forcefields: 34
config:
iterations: 8
poses: 65536
ppwi:
available: [1,2,4,8,16,32,64,128]
selected: [1]
wgsize: [1]
device: { index: 0, name: "OMP CPU" }
# (ppwi=1,wgsize=1,valid=1)
results:
- outcome: { valid: true, max_diff_%: 0.002 }
param: { ppwi: 1, wgsize: 1 }
raw_iterations: [410.365,467.623,498.332,416.583,465.063,469.426,473.833,440.093,461.504,455.871]
context_ms: 6.184589
sum_ms: 3680.705
avg_ms: 460.088
min_ms: 416.583
max_ms: 498.332
stddev_ms: 22.571
giga_interactions/s: 3.474
gflop/s: 139.033
gfinst/s: 86.847
energies:
- 865.52
- 25.07
- 368.43
- 14.67
- 574.99
- 707.35
- 33.95
- 135.59
best: { min_ms: 416.58, max_ms: 498.33, sum_ms: 3680.71, avg_ms: 460.09, ppwi: 1, wgsize: 1 }
For reference, available command line option are:
> ./omp-bude --help INT ✘ tom@soraws-uk 11:53:01
Usage: ./bude [COMMAND|OPTIONS]
Commands:
help -h --help Print this message
list -l --list List available devices
Options:
-d --device INDEX Select device at INDEX from output of --list, performs a substring match of device names if INDEX is not an integer
[optional] default=0
-i --iter I Repeat kernel I times
[optional] default=8
-n --poses N Compute energies for only N poses, use 0 for deck max
[optional] default=0
-p --ppwi PPWI A CSV list of poses per work-item for the kernel, use `all` for everything
[optional] default=1; available=1,2,4,8,16,32,64,128
-w --wgsize WGSIZE A CSV list of work-group sizes, not all implementations support this parameter
[optional] default=1
--deck DIR Use the DIR directory as input deck
[optional] default=`../data/bm1`
-o --out PATH Save resulting energies to PATH (no-op if more than one PPWI/WGSIZE specified)
[optional]
-r --rows N Output first N row(s) of energy values as part of the on-screen result
[optional] default=8
--csv Output results in CSV format
[optional] default=false
Overriding default flags
By default, we have defined a set of optimal flags for known HPC compilers.
There are assigned those to RELEASE_FLAGS, and you can override them if required.
To find out what flag each model supports or requires, simply configure while only specifying the model. For example:
> cd miniBUDE
> cmake -Bbuild -H. -DMODEL=omp
No CMAKE_BUILD_TYPE specified, defaulting to 'Release'
-- CXX_EXTRA_FLAGS:
Appends to common compile flags. These will be appended at link phase as well.
To use separate flags at link phase, set `CXX_EXTRA_LINK_FLAGS`
-- CXX_EXTRA_LINK_FLAGS:
Appends to link flags which appear *before* the objects.
Do not use this for linking libraries, as the link line is order-dependent
-- CXX_EXTRA_LIBRARIES:
Append to link flags which appear *after* the objects.
Use this for linking extra libraries (e.g `-lmylib`, or simply `mylib`)
-- CXX_EXTRA_LINKER_FLAGS:
Append to linker flags (i.e GCC's `-Wl` or equivalent)
-- Available models: omp;ocl;std-indices;std-ranges;hip;cuda;kokkos;sycl;acc;raja;tbb;thrust
-- Selected model : omp
-- Supported flags:
CMAKE_CXX_COMPILER (optional, default=c++): Any CXX compiler that supports OpenMP as per CMake detection (and offloading if enabled with `OFFLOAD`)
ARCH (optional, default=): This overrides CMake's CMAKE_SYSTEM_PROCESSOR detection which uses (uname -p), this is mainly for use with
specialised accelerators only and not to be confused with offload which is is mutually exclusive with this.
Supported values are:
- NEC
OFFLOAD (optional, default=OFF): Whether to use OpenMP offload, the format is <VENDOR:ARCH?>|ON|OFF.
We support a small set of known offload flags for clang, gcc, and icpx.
However, as offload support is rapidly evolving, we recommend you directly supply them via OFFLOAD_FLAGS.
For example:
* OFFLOAD=NVIDIA:sm_60
* OFFLOAD=AMD:gfx906
* OFFLOAD=INTEL
* OFFLOAD=ON OFFLOAD_FLAGS=...
OFFLOAD_FLAGS (optional, default=): If OFFLOAD is enabled, this *overrides* the default offload flags
OFFLOAD_APPEND_LINK_FLAG (optional, default=ON): If enabled, this appends all resolved offload flags (OFFLOAD=<vendor:arch> or directly from OFFLOAD_FLAGS) to the link flags.
This is required for most offload implementations so that offload libraries can linked correctly.
Benchmarks
Two input decks are included in this repository:
bm1is a short benchmark (~100 ms/iteration on a 64-core ThunderX2 node) based on a small ligand (26 atoms)bm2is a long benchmark (~25 s/iteration on a 64-core ThunderX2 node) based on a big ligand ( 2672 atoms)*bm2is a long benchmark (~25 s/iteration on a 64-core ThunderX2 node) based on a big ligand (2672 atoms)bm2_longis a very long benchmark based onbm2but with 1048576 poses instead of 65536
They are located in the data directory, and bm1 is run by default.
All implementations accept a --deck parameter to specify an input deck directory.
See makedeck for how to generate additional input decks.
Citing
Please cite miniBUDE using the following reference:
@inproceedings{poenaru2021performance,
title={A performance analysis of modern parallel programming models using a compute-bound application},
author={Poenaru, Andrei and Lin, Wei-Chen and McIntosh-Smith, Simon},
booktitle={International Conference on High Performance Computing},
pages={332--350},
year={2021},
organization={Springer}
}
Andrei Poenaru, Wei-Chen Lin, and Simon McIntosh-Smith. 2021. A Performance Analysis of Modern Parallel Programming Models Using a Compute-Bound Application. In High Performance Computing: 36th International Conference, ISC High Performance 2021, Virtual Event, June 24 – July 2, 2021, Proceedings. Springer-Verlag, Berlin, Heidelberg, 332–350. https://doi.org/10.1007/978-3-030-78713-4_18
For the Julia port specifically: https://doi.org/10.1109/PMBS54543.2021.00016
@inproceedings{lin2021julia,
title={Comparing julia to performance portable parallel programming models for hpc},
author={Lin, Wei-Chen and McIntosh-Smith, Simon},
booktitle={2021 International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS)},
pages={94--105},
year={2021},
organization={IEEE}
}
For the ISO C++ port specifically: https://doi.org/10.1109/PMBS56514.2022.00009
@inproceedings{lin2022cpp,
title={Evaluating iso c++ parallel algorithms on heterogeneous hpc systems},
author={Lin, Wei-Chen and Deakin, Tom and McIntosh-Smith, Simon},
booktitle={2022 IEEE/ACM International Workshop on Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS)},
pages={36--47},
year={2022},
organization={IEEE}
}